



19 世紀は印象派芸術運動が栄えた時代で、絵画、彫刻、版画などの芸術の分野に影響を与えました。印象派は、形式的な正確さをほとんど追求せずに、短いスタッカートのブラシストロークを使用することを特徴とし、後に印象派の芸術スタイルに発展しました。つまり、印象派の画家の筆致は修正されておらず、明らかな特徴を示しており、形式的な正確さを追求しておらず、どこか曖昧ですらある。印象派の芸術家は、光と色の科学的な概念を絵画に導入し、伝統的な色の概念に革命をもたらしました。
D3GA では、作成者はユニークな目標を持っており、逆のことを行うことでフォトリアリスティックなパフォーマンス効果を作成したいと考えています。この目標を達成するために、著者は仮想キャラクターの構造と外観を構築し、リアルタイムで安定した効果を実現するための最新の「セグメント ブラシストローク」として D3GA のガウス スプラッター テクノロジーを創造的に使用しました。

「日の出・印象」は印象派の有名画家モネの代表作です。

アニメーション用の新しいコンテンツを生成できるリアルな人物像を作成するには、現在アバターの構築が必要です。大量の作業用マルチビューデータ。これは、単眼式の方法では精度が限られているためです。さらに、既存の技術では、正確な 3D レジストレーションを含む複雑な前処理が必要です。ただし、これらの登録データの取得には反復が必要であり、エンドツーエンドのプロセスに統合するのは困難です。 さらに、正確な登録を必要とせず、神経放射野 (NeRF) に基づく方法もあります。ただし、これらの方法では、リアルタイム レンダリングが遅くなったり、衣服のアニメーションに問題が生じたりすることがよくあります。
Kerbl らは、古典的なサーフェス スプラッティング レンダリング方法をベースに改良された 3D ガウス スプラッティング (3DGS) と呼ばれるレンダリング方法を提案しました。神経放射線場に基づく最先端の方法と比較して、3DGS は、高精度の 3D 初期化を必要とせずに、より高速なフレーム レートで高品質の画像をレンダリングできます。
ただし、3DGS はもともと静的なシーン用に設計されました。現在、動的シーンのレンダリングに使用できる、時間条件に基づいたガウス スプレーティング法を提案している人もいます。この方法は、以前に観察されたものを再生することしかできないため、新しい動きやこれまでに見たことのない動きを表現するのには適していません。
著者は、駆動された神経放射線場に基づいて、3D 人間の外観と変形をモデル化し、標準化された空間に配置しますが、放射線場ではなく 3D ガウスを使用します。ガウス スプラッティングでは、パフォーマンスが向上するだけでなく、カメラ レイ サンプリング ヒューリスティックを使用する必要がなくなります。
#残りの問題は、これらのケージの変形を引き起こす信号を定義することです。ドライバー駆動のアバターにおける現在の最先端テクノロジーは、RGB-D 画像や複数のカメラなどの高密度の入力信号を必要としますが、これらの方法は、伝送帯域幅が比較的低い状況には適さない可能性があります。この研究では、著者らは、骨格関節角度や四元数形式の 3D 顔のキーポイントなど、人間のポーズに基づいたよりコンパクトな入力を使用しています。さまざまな体型、動き、服装 (親密な服装に限定されない) をカバーする 9 つの高品質マルチビュー シーケンスで個人固有のモデルをトレーニングすることで、後で次のことが可能になります。あらゆる被写体の新しい姿勢がその姿を動かします。
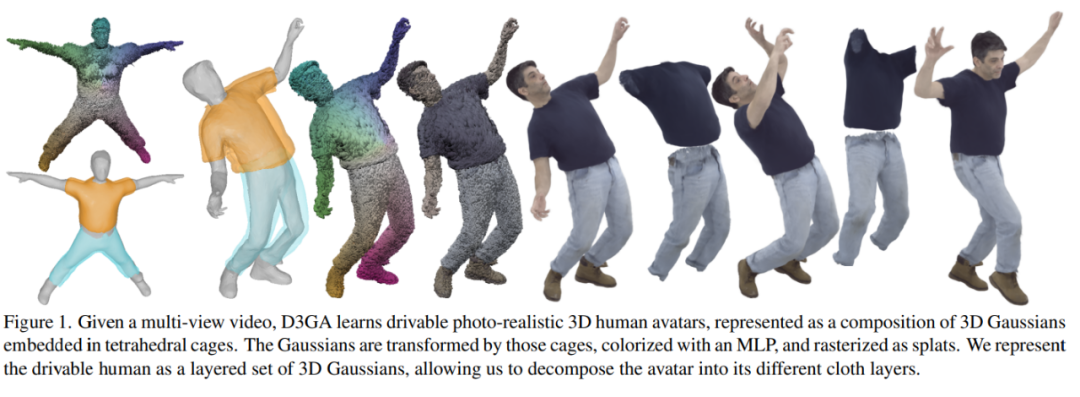
 メソッドの概要
メソッドの概要
 ##
##
仮想キャラクターを動的にボリューム化する現在の方法は、変形空間から正準空間に点をマッピングするか、単に依存するかのどちらかです。フォワードマッピング。バック マッピングに基づく方法では、エラーが発生しやすいバック パスが必要であり、視点依存効果のモデル化に問題があるため、正準空間でエラーが蓄積する傾向があります。
そこで、著者はフォワードマッピングのみの方法を採用することにしました。 D3GA は 3DGS に基づいており、ニューラル表現とケージを通じて拡張され、仮想キャラクターの各動的部分の色と幾何学的形状をそれぞれモデル化します。
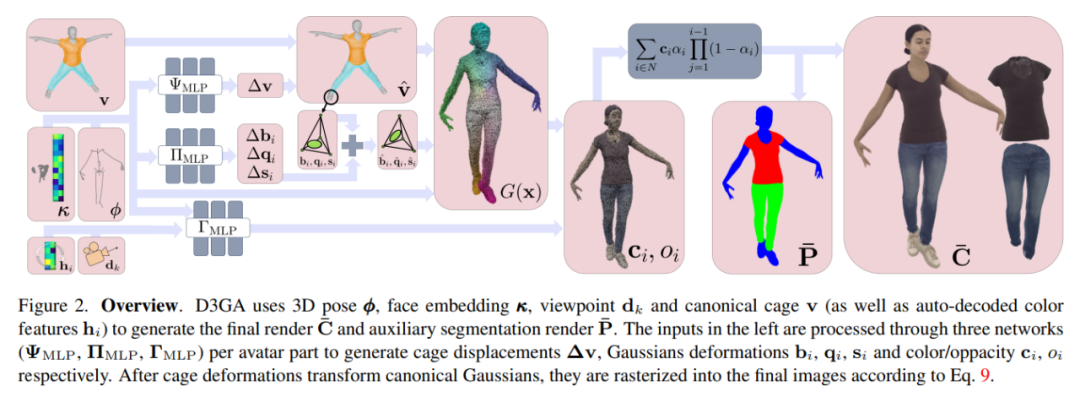
D3GA は、3D ポーズ ϕ、顔埋め込み κ、視点 dk、および標準ケージ v (および自動的にデコードされた色特徴 hi) を使用して、最終的なレンダリングを生成します。 C ̄ と補助セグメンテーションは P ̄ をレンダリングします。左側の入力は、仮想キャラクター パーツごとに 3 つのネットワーク (ΨMLP、ΠMLP、ΓMLP) を通じて処理され、ケージ変位 Δv、ガウス変形 bi、qi、si、色/透明度 ci、oi が生成されます。
ケージ変形によって正準ガウス分布が変形された後、式 9 を介して最終画像にラスタライズされます。
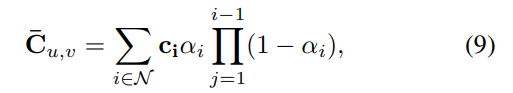
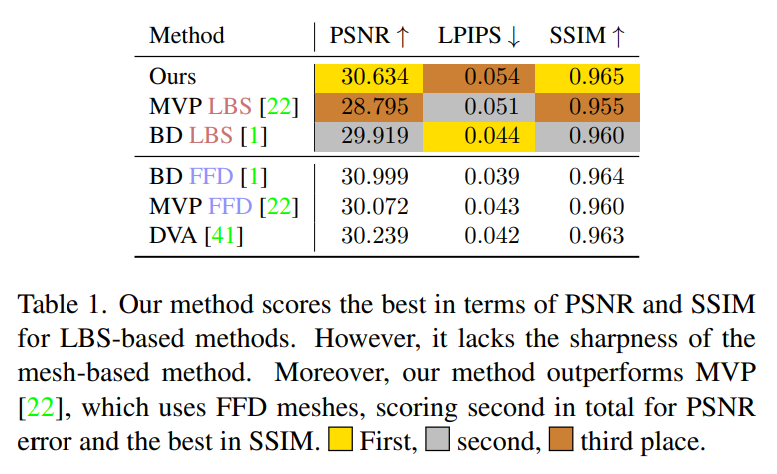

#ボリュームベースの方法との比較これに比べて、著者の方法は仮想キャラクターの服装を分離することができ、服装も駆動可能である。図 5 は、特定の衣服登録モジュールを必要とせずに、骨の関節角度だけで個々の衣服の層を制御できることを示しています。
以上がAI研究も印象派から学べるのでしょうか?これらの本物そっくりの人々は、実際には 3D モデルですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



