


マルチモーダルな大型モデルが急増していますが、画像編集、自動運転、ロボット工学などのきめ細かいタスクで実用化する準備はできていますか?
最新のモデルの機能は依然として、画像全体または特定の領域のテキスト説明を生成することに限定されており、ピクセルレベルの理解 (オブジェクトのセグメンテーションなど) の機能は比較的限定されています。
この問題に対応して、ユーザーのセグメント化命令 (たとえば、「写真の中のビタミン C が豊富な果物をセグメント化してください」) を処理するために、マルチモーダルな大規模モデルの使用を検討する取り組みが始まりました。
しかし、市販されている方法にはすべて 2 つの大きな欠点があります:
1) 現実世界のシナリオでは不可欠な、複数のターゲット オブジェクトが関与するタスクを処理できません。 #2) SAM のような事前トレーニング済みの画像セグメンテーション モデルに依存しており、SAM の 1 回の前方伝播に必要な計算量は、Llama-7B が 500 個を超えるトークンを生成するのに十分です。
この問題を解決するために、Bytedance Intelligent Creation チームは北京交通大学および北京科学技術大学の研究者と協力して、PixelLM を提案しました。PixelLM は、 SAM に依存しないでください。
詳しく紹介する前に、PixelLM のいくつかのグループの実際のセグメンテーション効果を体験してみましょう:
以前の作品と比較した PixelLM の利点は次のとおりです:
任意の数のオープン ドメイン ターゲットやさまざまな複雑な推論セグメンテーション タスクを適切に処理できます。
 上記の効果を達成するために、この研究はどのように行われたのでしょうか?
上記の効果を達成するために、この研究はどのように行われたのでしょうか?
背後にある原理
図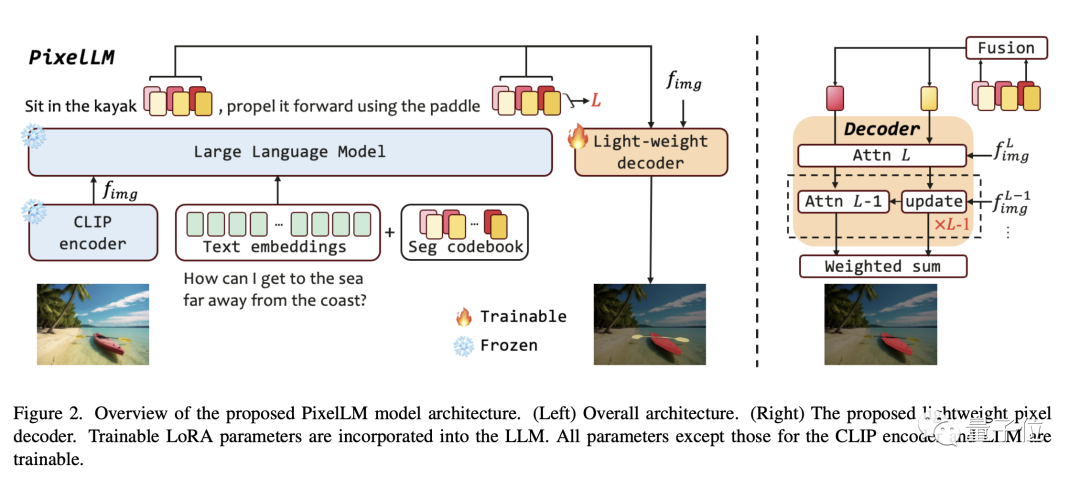 論文のフレームワーク図に示されているように、PixelLM アーキテクチャは非常にシンプルであり、4 つの要素で構成されています。主要部分。後の 2 つは PixelLM の中核です:
論文のフレームワーク図に示されているように、PixelLM アーキテクチャは非常にシンプルであり、4 つの要素で構成されています。主要部分。後の 2 つは PixelLM の中核です:
研究者の説明によると、Seg コードブック内のトークンは L 個のグループに分割でき、各グループには N 個のトークンが含まれ、各グループは CLIP-ViT 視覚機能のスケールに対応します。
入力画像の場合、PixelLM は、CLIP-ViT ビジュアル エンコーダーによって生成された画像特徴から L スケール特徴を抽出します。最後の層はグローバル画像情報をカバーし、LLM が画像の内容を理解するために使用します。
セグメント コードブックのトークンは、テキスト命令および画像特徴の最後の層とともに LLM に入力され、自己回帰の形式で出力が生成されます。出力には、LLM によって処理されたセグメント コードブック トークンも含まれます。これらのトークンは、L スケール CLIP-ViT 機能とともにピクセル デコーダーに入力されて、最終的なセグメンテーション結果が生成されます。
図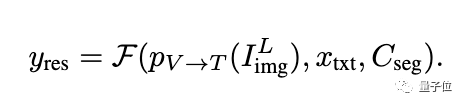
図 では、なぜ各グループに N が含まれるように設定する必要があるのでしょうか。トークン??研究者らは、次の図を参照して説明しました:
では、なぜ各グループに N が含まれるように設定する必要があるのでしょうか。トークン??研究者らは、次の図を参照して説明しました:
複数のターゲット、または非常に複雑なセマンティクスを持つターゲットが関与するシナリオでは、LLM は詳細なテキスト応答を提供できますが、単一のトークンだけでは完全にキャプチャできない可能性があります。ターゲットセマンティクスの内容。
複雑な推論シナリオにおけるモデルの能力を強化するために、研究者らは各スケール グループ内に複数のトークンを導入し、1 つのトークンの線形融合演算を実行しました。トークンがデコーダーに渡される前に、線形投影レイヤーを使用して各グループ内のトークンがマージされます。
次の図は、各グループに複数のトークンがある場合の効果を示しています。アテンション マップは、デコーダーによって処理された後の各トークンの様子です。この視覚化は、複数のトークンが一意で補完的な情報を提供し、その結果、より効果的なセグメンテーション出力が得られることを示しています。
 写真
写真
さらに、複数のターゲットを区別するモデルの能力を強化するために、PixelLM は追加のターゲット精製損失も設計しました。
上記のソリューションが提案されていますが、モデルの機能を最大限に活用するには、モデルには依然として適切なトレーニング データが必要です。現在利用可能な公開データセットをレビューしたところ、既存のデータには次のような大きな制限があることがわかりました:
1) オブジェクトの詳細の説明が不十分;
2) 複雑な推論と複数のターゲット番号に関する問題の欠如 -答えは正しいです。
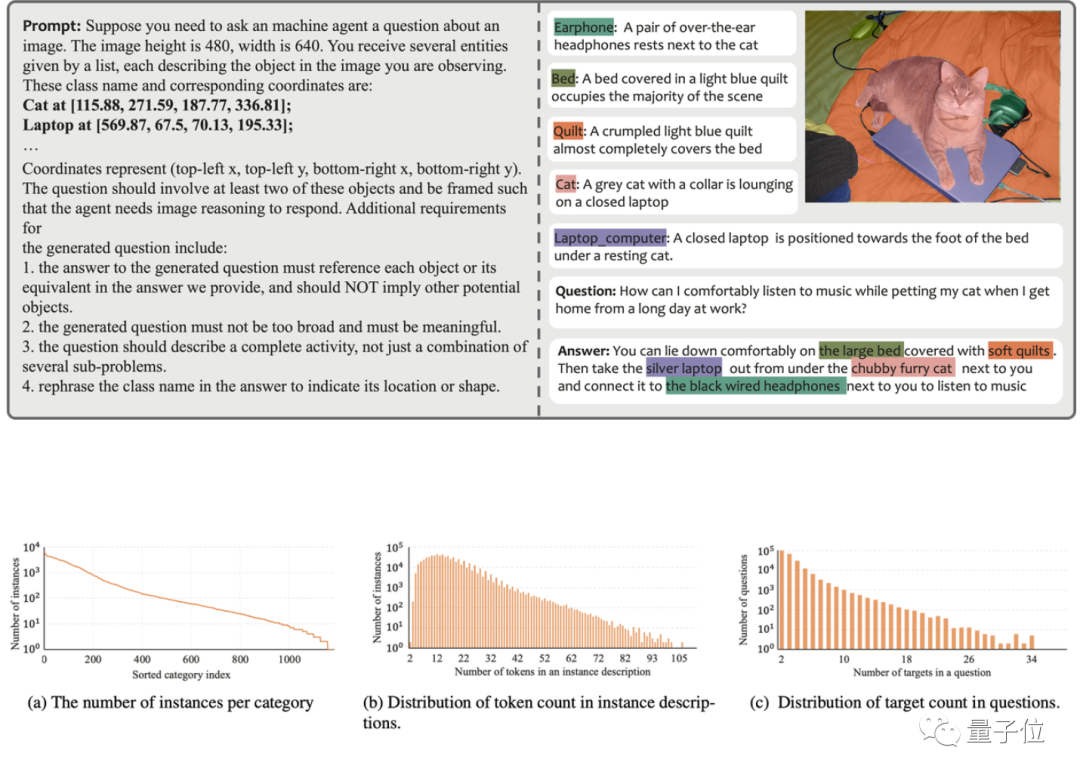
これらの問題を解決するために、研究チームは GPT-4V を使用して自動データ アノテーション パイプラインを構築し、MUSE データ セットを生成しました。以下の図は、MUSE 生成時に使用されるプロンプトと生成されるデータの例を示しています。
 画像
画像
MUSE では、すべてのインスタンス マスクは LVIS データセットから取得され、画像コンテンツに基づいて生成された詳細なテキスト説明が追加されます。 MUSE には 246,000 の質問と回答のペアが含まれており、各質問と回答のペアには平均 3.7 のターゲット オブジェクトが含まれます。さらに、研究チームは、データセットの徹底的な統計分析を実施しました。
カテゴリ統計: MUSE には、元の LVIS データセットからの 1,000 以上のカテゴリと、質問と回答に基づいた独自の説明を持つ 900,000 のインスタンスがあります。ペアはコンテキストによって異なります。図 (a) は、すべての質問と回答のペアにわたる各カテゴリのインスタンスの数を示しています。
トークン数の統計: 図 (b) は、インスタンスに記述されているトークンの数の分布を示しています。一部のインスタンスの記述には、100 を超えるトークンが含まれています。これらの説明は単純なカテゴリ名に限定されるものではなく、GPT-4V ベースのデータ生成プロセスを通じて、外観、プロパティ、他のオブジェクトとの関係など、各インスタンスに関する詳細情報が豊富に含まれています。データセット内の情報の深さと多様性により、トレーニングされたモデルの汎化能力が強化され、オープンドメインの問題を効果的に解決できるようになります。
ターゲット数の統計: 図 (c) は、各質問と回答のペアのターゲット数の統計を示しています。ターゲットの平均数は 3.7 で、最大ターゲット数は 34 に達します。この数は、単一の画像に対するほとんどのターゲット推論シナリオをカバーできます。
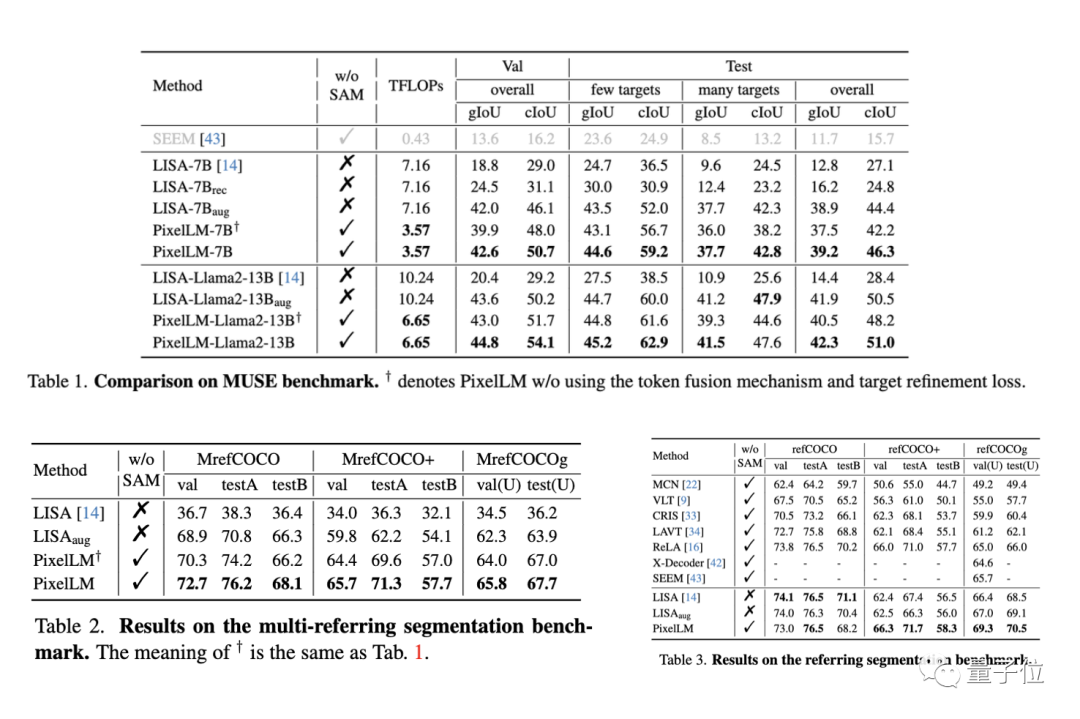
研究チームは、MUSE ベンチマーク、参照セグメンテーション ベンチマーク、および複数参照セグメンテーション ベンチマークを含む 3 つのベンチマークで PixelLM のパフォーマンスを評価しました。研究チームは、1 つの問題で参照セグメンテーション ベンチマークの各画像に含まれる複数のターゲットを連続的にセグメント化するモデルを必要としています。
同時に、PixelLM は複数のターゲットが関係する複雑なピクセル推論タスクを処理する最初のモデルであるため、研究チームはモデルの比較分析を行うために 4 つのベースラインを確立しました。
ベースラインのうち 3 つは、PixelLM で最も関連性の高い作業である LISA に基づいており、次のものが含まれます:
1) オリジナル LISA;
2) LISA_rec: 最初に質問を入力します。 LLAVA-13B: ターゲットのテキスト返信を取得し、LISA を使用してテキストを分割します。
3) LISA_aug: MUSE を LISA トレーニング データに直接追加します。
4) もう 1 つは、LLM を使用しない一般的なセグメンテーション モデルである SEEM です。
 写真
写真
3 つのベンチマークのほとんどの指標で、PixelLM のパフォーマンスは他の方法よりも優れており、PixelLM は SAM に依存していないため、その TFLOP は同じサイズのモデルに比べてはるかに低いです。
興味のある友人は、まずこの波をフォローし、コードがオープンソースになるのを待つことができます~
参考リンク:
[1]//m.sbmmt.com / link/9271858951e6fe9504d1f05ae8576001
[2]//m.sbmmt.com/link/f1686b4badcf28d33ed632036c7ab0b8
以上がPixelLM: SA に依存せずにピクセルレベルの推論を効率的に実装するバイトマルチモーダル大規模モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



