


ドキュメント画像をMarkdown形式に変換したいですか?
以前は、このタスクにはテキスト認識、レイアウトの検出と並べ替え、数式テーブルの処理、テキストのクリーニングなどの複数の手順が必要でしたが、今回は 1 つの手順だけで済みます。文コマンド、
マルチモーダル大規模モデルVary はエンドツーエンドの結果を直接出力します:
Picture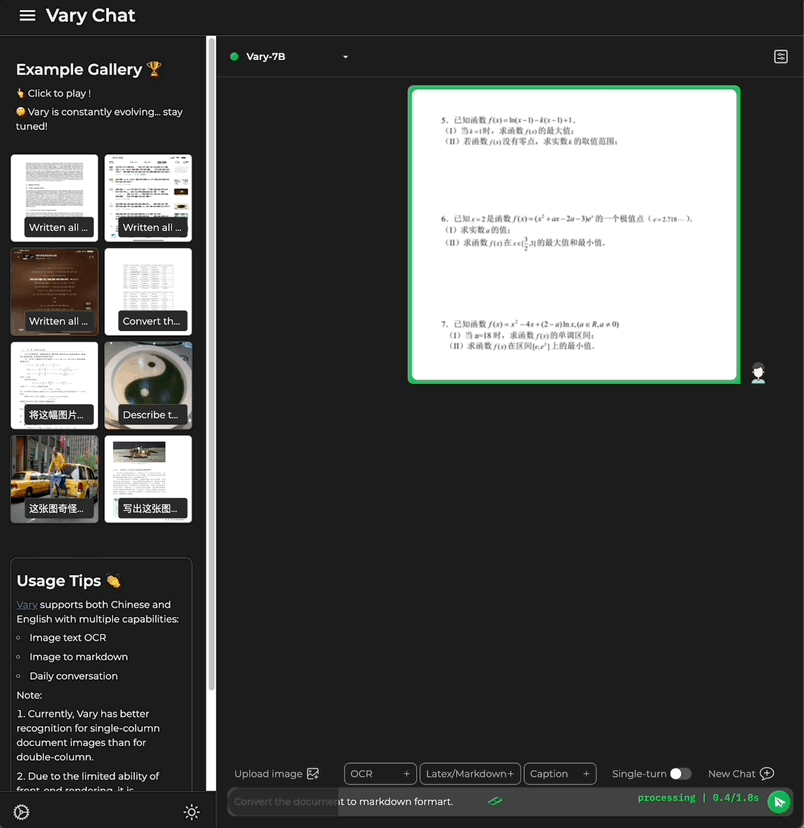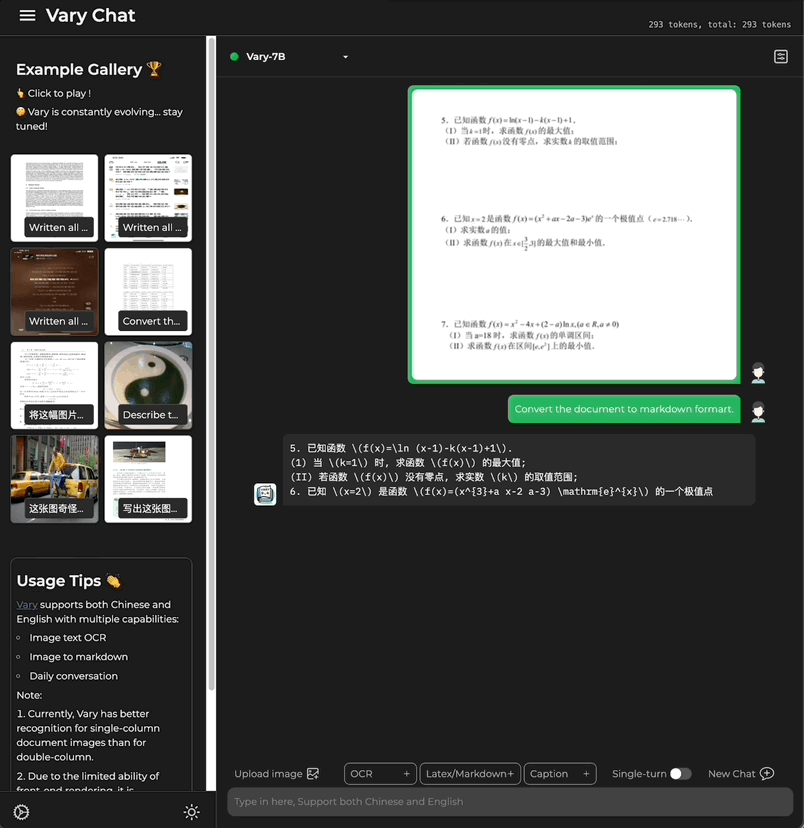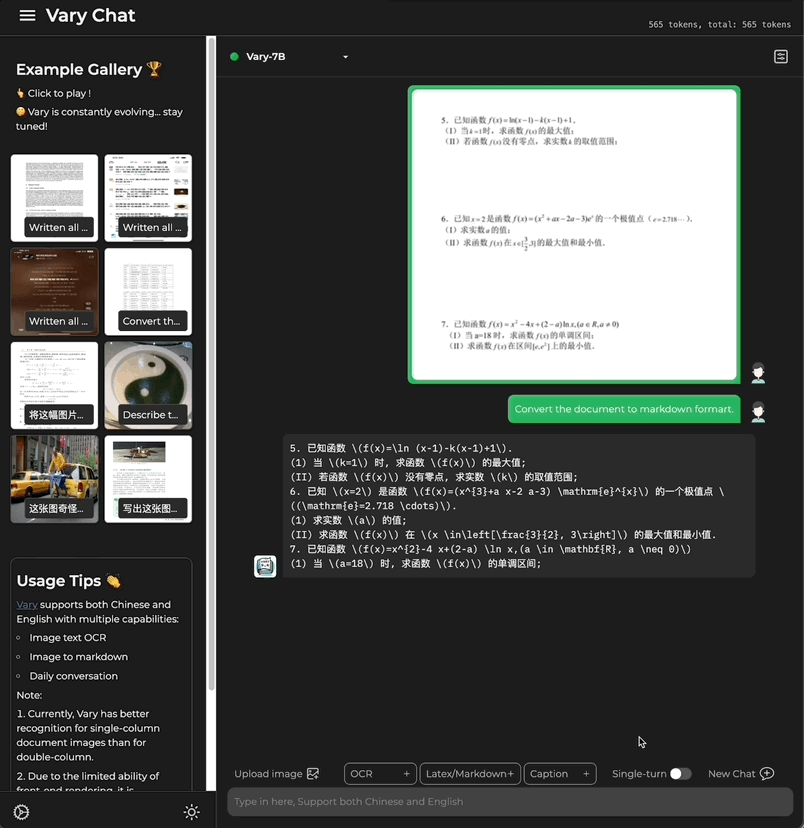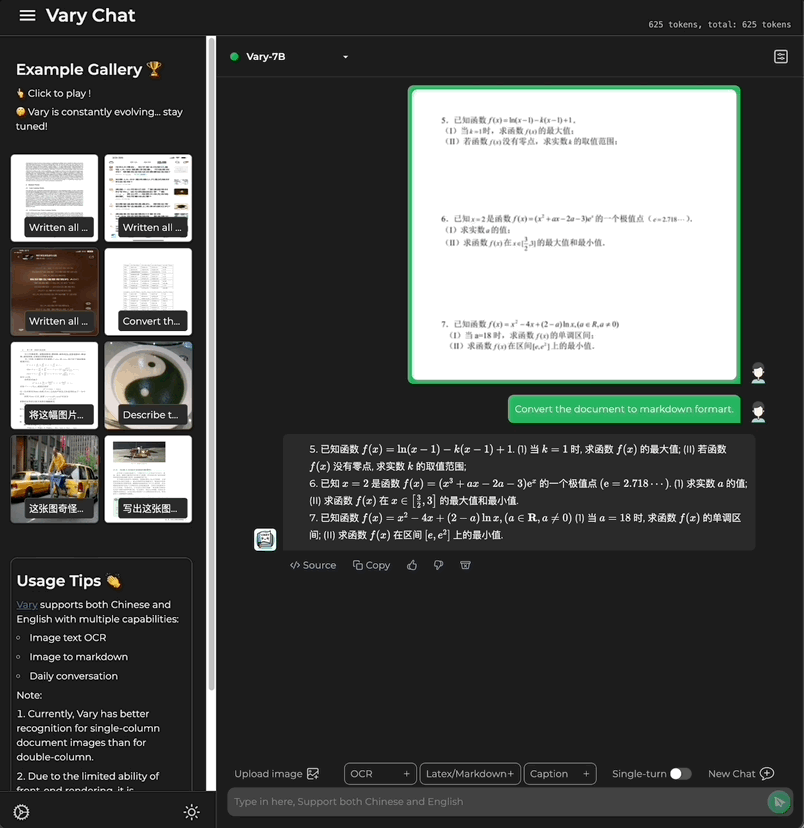 かどうか中国語または英語で書かれた大きな段落です テキスト:
かどうか中国語または英語で書かれた大きな段落です テキスト:
 式の文書画像も含まれています
式の文書画像も含まれています
Picture
 またはモバイル ページのスクリーンショット:
またはモバイル ページのスクリーンショット:
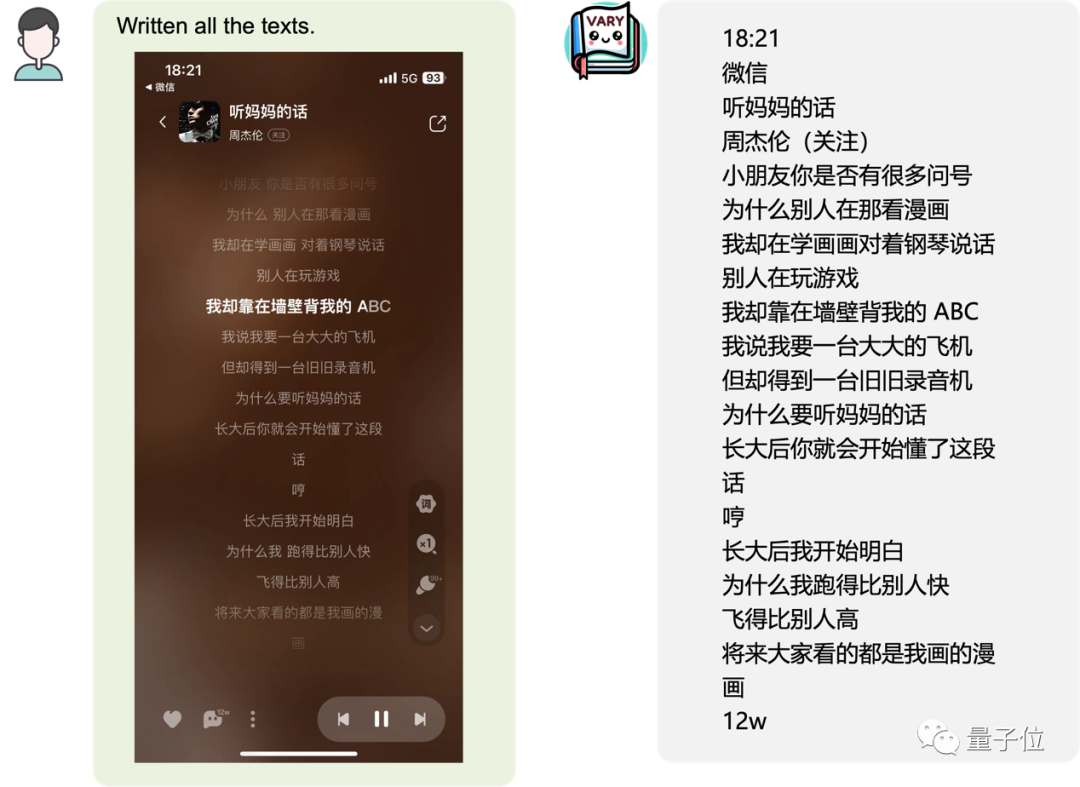 変換することもできます画像のテーブルを
変換することもできます画像のテーブルを
Picture
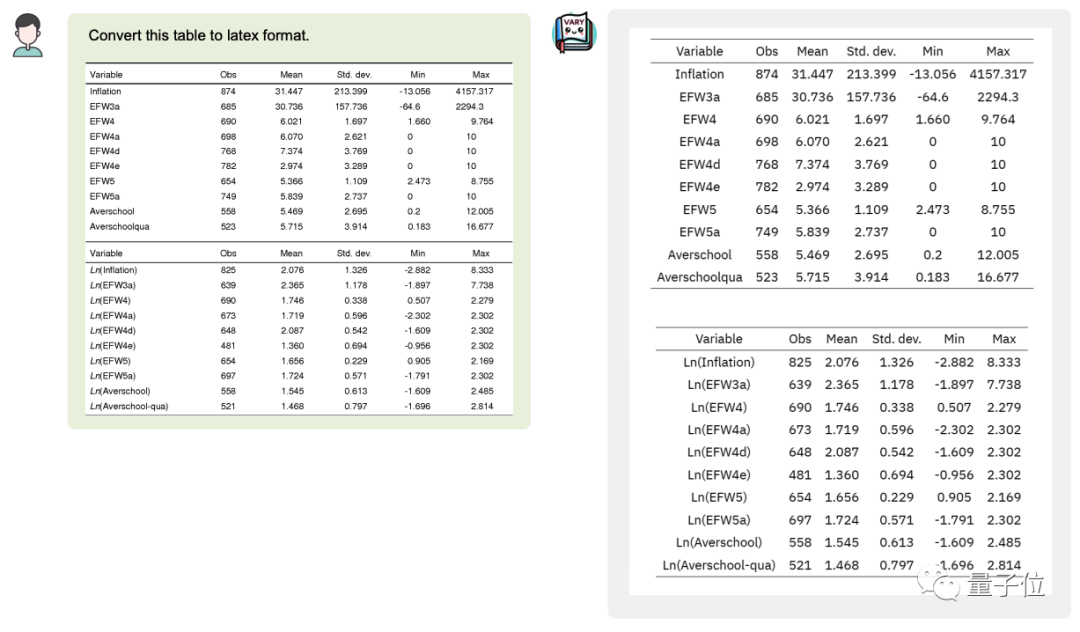 もちろん、マルチモードとして大規模なスケール モデル、ユニバーサル機能の維持は不可欠
もちろん、マルチモードとして大規模なスケール モデル、ユニバーサル機能の維持は不可欠
Picture
 Vary は大きな可能性と非常に高い上限を示しています。OCR は長いパイプラインを必要とせず、直接出力できますプロンプトは、Latex、Word、Markdown などのさまざまな形式を出力します。 このアーキテクチャでは、強力な言語優先順位を使用して、「レバレッジ」や「デュポール」など、OCR でタイプミスが起こりやすい単語を回避できます。あいまいな文書の場合は、事前言語の助けを借りて、より強力な OCR 効果を達成することも期待されています。
Vary は大きな可能性と非常に高い上限を示しています。OCR は長いパイプラインを必要とせず、直接出力できますプロンプトは、Latex、Word、Markdown などのさまざまな形式を出力します。 このアーキテクチャでは、強力な言語優先順位を使用して、「レバレッジ」や「デュポール」など、OCR でタイプミスが起こりやすい単語を回避できます。あいまいな文書の場合は、事前言語の助けを借りて、より強力な OCR 効果を達成することも期待されています。
多くのネチズンの注目を集めたこのプロジェクトは、開始されるとすぐに広範な議論を引き起こしました。これを見たネチズンの一人は「本当にすごい!」と叫びました。
写真
 この効果はどのようにして達成されるのでしょうか? 大規模モデルからのインスピレーション
この効果はどのようにして達成されるのでしょうか? 大規模モデルからのインスピレーション
現在、ほとんどすべての大規模なマルチモーダル モデルは、ビジョン エンコーダまたはビジュアル ボキャブラリとして CLIP を使用しています。実際、4 億個の画像とテキストのペアでトレーニングされた CLIP は、強力な視覚的テキスト配置機能を備えており、ほとんどの日常業務での画像エンコーディングをカバーできます。
質問。
大規模な純粋な NLP モデル (LLaMA など) が英語から中国語 (大規模モデルにとっては「外国語」) に移行する場合、中国語をエンコードする元の語彙は非効率であるため、テキスト語彙を次のように拡張する必要があります。より良いパフォーマンスを達成し、良い結果をもたらします。 研究チームはこれに触発されました。まさにこの機能のためです。
CLIP 視覚語彙に基づくマルチモーダル大規模モデルも同じ問題に直面し、「外国語画像」に遭遇します。 」、テキストがびっしりと詰まった紙のページなど、画像を効率的にトークン化することは困難です。
Vary は、この問題を解決するために提供されたソリューションです。元の語彙を再構築することなく、視覚的な語彙を効率的に拡張できます
##Picture既製の CLIP ボキャブラリを直接使用する既存の方法とは異なり、Vary は 2 つの段階に分かれています。  最初に、小さなものだけを使用します。 デコーダ ネットワークは、自己回帰的な方法で強力な新しいビジュアル ボキャブラリを生成します。 次に、第 2 段階では、新しい語彙と CLIP 語彙が融合されて LVLM を効率的にトレーニングし、ドキュメント チャートやその他のデータでトレーニングされた新しい Vary の特性が、きめ細かい視覚認識能力を大幅に強化します。
最初に、小さなものだけを使用します。 デコーダ ネットワークは、自己回帰的な方法で強力な新しいビジュアル ボキャブラリを生成します。 次に、第 2 段階では、新しい語彙と CLIP 語彙が融合されて LVLM を効率的にトレーニングし、ドキュメント チャートやその他のデータでトレーニングされた新しい Vary の特性が、きめ細かい視覚認識能力を大幅に強化します。
バニラのマルチモーダル機能を維持しながら、エンドツーエンドの中国語と英語の画像、数式スクリーンショット、およびチャート理解機能も刺激します。
さらに、研究チームは、本来は数千のトークンを必要とした可能性のあるページコンテンツが文書画像を通じて入力され、その情報が 256 個の画像トークンに Vary 圧縮されていることにも気づきました。これにより、さらなるページ分析のための情報も提供されました。想像力の余地がさらに広がります。
現在、Vary のコードとモデルはオープンソースであり、誰でも試せる Web デモも提供されています。
興味のある友達は試してみてください~
以上がMegvii のオープンソース マルチモーダル大規模モデルは、中国語と英語をカバーするドキュメント レベルの OCR をサポートしています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



