


大規模な言語モデルは、インテリジェントな運転の新しいパターンを切り開き、人間のような思考と認知能力を与えます。この記事では、自動運転 (AD) における大規模言語モデル (LLM) の可能性について詳しく説明します。そこでシミュレーション環境で閉ループ自動運転を実現できるLLMベースのADフレームワークであるDriveMLMが提案されている。具体的には次の点があります:
要約すると、DriveMLM の主な貢献は次のとおりです。

大規模言語モデル (LLM) からの言語選択を実用的な制御信号に変換することは、車両制御にとって重要です。これを達成するために、LLM の出力を、一般的な Apollo システムの行動計画モジュールの決定フェーズと調整しました。共通のアプローチに基づいて、意思決定プロセスをスピード意思決定とパス意思決定の 2 つのカテゴリに分類します。具体的には、速度決定ステータスには(維持、加速、減速、停止)が含まれ、経路決定ステータスには(追従、左変更、右変更、左ボロー、右ボロー)が含まれる。
MLLM プランナー
 DriveMLM の MLLM プランナーは、マルチモーダル トークナイザーと MLLM デコーダーの 2 つのコンポーネントで構成されています。 2 つのモジュールは緊密に連携し、さまざまな入力を処理して運転上の決定を正確に決定し、その決定に対する説明を提供します。
DriveMLM の MLLM プランナーは、マルチモーダル トークナイザーと MLLM デコーダーの 2 つのコンポーネントで構成されています。 2 つのモジュールは緊密に連携し、さまざまな入力を処理して運転上の決定を正確に決定し、その決定に対する説明を提供します。
MLLM デコーダ 。デコーダは、トークン化された入力を決定状態と決定解釈に変換する中核です。この目的を達成するために、表 1 に示すように、LLM ベースの AD 用のシステム メッセージ テンプレートを設計しました。見てわかるように、システム メッセージには、AD タスクの説明、トラフィック ルール、決定状態の定義、および各モーダル情報がマージされる場所を示すプレースホルダーが含まれています。このアプローチにより、さまざまなモダリティやソースからの入力をシームレスに統合できます。
出力は、意思決定ステータス (表 1 の Q2 を参照) と意思決定の説明 (表 1 の Q3 を参照) を提供する形式になっているため、意思決定プロセスの透明性と明確さが提供されます。教師ありメソッドに関して、私たちのフレームワークは、次のトークンの予測でクロスエントロピー損失を使用するという一般的な手法に従っています。このようにして、MLLM プランナーは、さまざまなセンサーやソースからのデータを詳細に理解して処理し、それを適切な決定と解釈に変換することができます。
CARLA シミュレーターのさまざまなシナリオから意思決定状態と説明の注釈を作成できるデータ生成パラダイムを提案します。このパイプラインは、LLM ベースの AD システムをトレーニングするための決定状態や詳細な説明が不足している既存の運転データの制限に対処できます。私たちのパイプラインは、データ収集とデータ アノテーションという 2 つの主要なコンポーネントで構成されています。
データ収集は、現実的でありながら意思決定の多様性を高めるように設計されています。まず、シミュレーション環境でさまざまな挑戦的なシナリオを構築します。安全運転には複雑な運転行動が必要です。経験豊富なドライバーやエージェントなどの専門家は、多くのアクセス可能な場所の 1 つでトリガーされるこれらのシナリオを安全に運転することが求められます。特に、インタラクション データは、専門家がランダムに運転要求を提案し、それに応じて運転するときに生成されます。専門家が安全に目的地まで運転すると、データが記録されます。
データ アノテーションは主に意思決定と解釈に焦点を当てます。まず、速度と経路の決定状態は、手動で作成されたルールを使用して、専門家の運転軌跡に基づいて自動的に注釈が付けられます。次に、説明の注釈が最初にシーンに基づいて生成され、近くの現在の要素によって動的に定義されます。第三に、生成された説明アノテーションは手動アノテーションによって洗練され、その多様性は GPT-3.5 によって拡張されます。さらに、対話コンテンツは、人間の要求の実行または拒否など、人間のアノテーターによって洗練されます。このようにして、コストのかかるフレームごとの決定状態のアノテーションや、コストのかかる説明アノテーションを最初から手作業で記述することを回避し、データ アノテーション プロセスを大幅にスピードアップします。
トレーニング用に 280 時間の走行データを収集しました。データには、CARLA の 8 つのマップ (Town01、Town02、Town03、Town04、Town06、Town07、Town10HD、Town12) で収集された 50 キロメートルのルートと、さまざまな天候と照明条件での 30 の運転シナリオが含まれています。平均して、各シーンには各マップ上に約 200 のトリガー ポイントがあり、ランダムにトリガーされます。それぞれの状況は、運転において一般的またはまれに安全上重要な状況になります。これらのシナリオの詳細については、補足ノートに記載されています。各フレームごとに、前後左右の 4 台のカメラからの画像と、自車両の中心に追加された LIDAR センサーからの点群が収集されます。私たちが収集するすべてのデータには、シナリオをうまく前進させるための対応する解釈と正確な決定が含まれています。
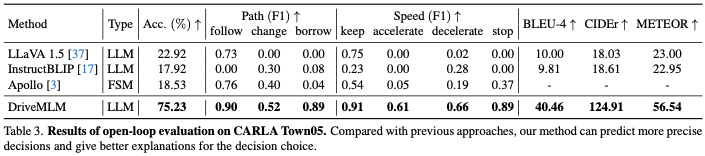
表 2 は、自然言語を使用して理解を促進するために設計された以前のデータセットとの比較を示しています。私たちのデータには 2 つのユニークな特徴があります。 1 つ目は、行動計画の状態の一貫性です。これにより、MLLM プランナーの出力を制御信号に変換し、フレームワークが閉ループ運転で車両を制御できるようになります。 2 つ目は、対人インタラクション アノテーションです。人間による自然言語による指示とそれに対応する決定と解釈が特徴です。目標は、人間のコマンドを理解し、それに応じて応答する能力を向上させることです。
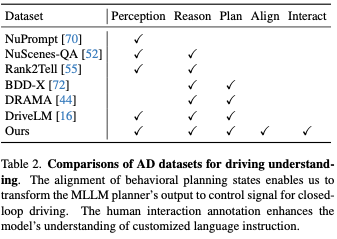
最も広く使用され、現実的に公開されている CARLA で閉ループ運転を評価します。シミュレーションベンチマーク。 CARLA で閉ループ駆動を実行できる最先端の手法がパフォーマンス比較のために含まれています。オープンソースの Apollo も、ベースラインとして CARLA で評価されました。私たちのアプローチを除けば、LLM ベースのアプローチで導入と評価の準備ができていることはありません。すべてのメソッドは Town05 の長期ベンチマークで評価されます。
表 4 に、運転スコア、ルート完了スコア、および違反スコアを示します。 Apollo はルールベースのアプローチですが、そのパフォーマンスは最近のエンドツーエンドのアプローチとほぼ同等であることに注意してください。 DriveMLM は、スコアの向上において他のすべての方法よりも大幅に優れています。これは、状態遷移を処理してハードドライブを安全に通過するのに DriveMLM の方が適していることを示唆しています。表 4 の最後の列は、MPI 評価の結果を示しています。エージェントはすべてのルートを完了する必要があるため、この指標はより包括的な運転パフォーマンスを示します。言い換えれば、テスト対象のエージェントは、すべてのルート上のすべての状況に遭遇します。 Thinktwice は Interfuser よりも優れた DS を実装していますが、停止線を頻繁に横切るため MPI が低くなります。ただし、この行為に対する CARLA の罰則は最小限です。対照的に、MPI はすべての交通違反を乗っ取りとして扱います。また、DriveMLM は他のすべての方法の中で最も高い MPI を達成しており、より多くの状況を回避できるため、より安全な運転体験が得られることを示しています。
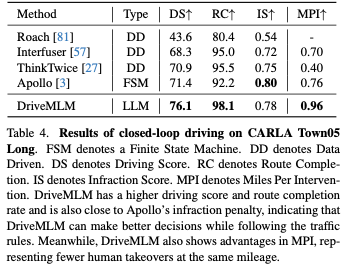
オープンループ評価を使用して、意思決定の予測タスクや説明予測タスクなどの運転知識を評価します。 。表 3 は、予測された決定ペアの精度、決定によって予測された各決定タイプの F1 スコア、および予測によって説明された BLEU-4、CIDEr、および METEOR を示しています。 Apollo の場合、Town05 で手動で収集されたシーンは、表 3 のモデルへの入力として再生されます。再生の各タイムスタンプにおける対応するモデルの状態と出力は、メトリック計算の予測として保存されます。他の方法では、対応する画像を入力として提供し、適切なプロンプトを表示します。モデルの予測を手動で収集したグラウンド トゥルースと比較することで、精度によって意思決定の正しさと人間の行動との類似性が明らかになり、F1 スコアは各パスの意思決定能力と意思決定のスピードを示します。 DriveMLM は全体的に最高の精度を達成し、LLaVA の 40.97% の精度を上回りました。 Apollo ベースラインと比較して、DriveMLM はより高い F1 スコアを達成しており、さまざまな道路状況の解決においてルールベースのステート マシンよりも効果的に優れていることを示しています。 LLaVA、structBLIP、および私たちが提案する DriveMLM は、質問と回答の形式で意思決定の説明を出力できます。 BLEU-4、CIDEr、METEOR に関しては、DriveMLM が最高のパフォーマンスを達成できます。これは、DriveMLM が決定に対して最も合理的な説明を提供できることを示しています。
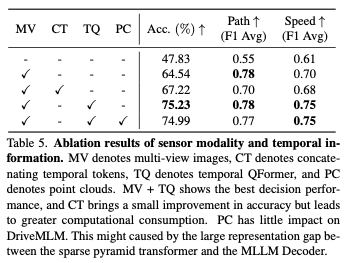
センサー モダリティ: 表 5 は、DriveMLM に対する入力センサー モダリティの影響を示しています。さまざまな影響の結果。マルチビュー (MV) 画像により、パスと速度の F1 スコアの両方でパフォーマンスが大幅に向上し、精度が 18.19% 向上しました。 Temporal QFormer は、テンポラル トークンを直接接続する場合と比較して、マルチモーダルな意思決定機能を確保しながら 7.4% の向上を達成し、その結果、速度決定の平均 F1 スコアが 0.05 向上しました。点群にはパフォーマンスを向上させる機能はありません。
人間とコンピューターの対話: 図 4 は、これを実現する方法を示しています。人間による指示 車両制御の例制御プロセスには、道路状況の分析、意思決定の選択、および説明文の提供が含まれます。同じ「追い越し」コマンドが与えられると、DriveMLM は現在の交通状況の分析に基づいて異なる応答を示しました。右車線が占有されており、左車線が利用可能な状況では、システムは左からの追い越しを選択します。ただし、すべての車線が占有されている場合など、特定の指示によって危険が生じる可能性がある状況では、DriveMLM は追い越し操作を実行しないことを選択し、適切に対応します。この場合、DriveMLM は人間と車両のインタラクションのためのインターフェイスであり、最終的に行動方針を選択する前に、交通力学に基づいて指示の妥当性を評価し、事前に定義されたルールに準拠していることを確認します。

実際のシナリオでのパフォーマンス: nuScenes データセットに DriveMLM を適用して、開発した駆動システムのゼロショット パフォーマンスをテストします。検証セットの 6019 フレームに注釈を付け、判定精度として 0.395 のゼロショット パフォーマンスを達成しました。図 5 は 2 つの実際の運転シナリオの結果を示しており、DriveMLM の多用途性を示しています。

この研究では、自動運転 (AD) に大規模言語モデル (LLM) を利用する新しいフレームワークである DriveMLM を提案します。 DriveMLM は、マルチモーダル LLM (MLLM) を使用してモジュラー AD システムの動作計画モジュールをモデル化することで、現実的なシミュレーション環境で閉ループ AD を実装できます。 DriveMLM は、運転上の決定について自然言語による説明を生成することもできるため、AD システムの透明性と信頼性を高めることができます。 CARLA Town05 Long ベンチマークでは、DriveMLM が Apollo ベンチマークを上回るパフォーマンスを示しました。私たちは、私たちの研究が LLM と AD の統合に関するさらなる研究を促すことができると信じています。
オープンソースリンク: https://github.com/OpenGVLab/DriveMLM

元のリンク: https://mp.weixin.qq.com/s/tQeERCbpD9H8oY8EvpZsDA
以上がループを閉じるために全力を尽くしてください! DriveMLM: LLM と自動運転行動計画を完全に組み合わせます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



