テスト時適応の目的は、推論フェーズでソース ドメイン モデルをテスト データに適応させることであり、未知の画像損傷フィールドへの適応において優れた結果を達成しました。ただし、現在の手法の多くは、現実のシナリオにおけるテスト データ フローを考慮していません。たとえば、次のようになります。
- テスト データ フローは、時間変動する分布 (従来のドメイン適応における固定分布ではなく)
- テスト データ ストリームには、(完全に独立した同一に分布したサンプリングではなく) ローカル クラス相関がある可能性があります
- テスト データ ストリームでは、長期間にわたって依然として世界的なカテゴリの不均衡が示されています
#最近、中国南部ではA* 工科大学 STAR チームと CUHK-Shenzhen チームは、これらの実際のシナリオでのデータ フローのテストが既存の手法に大きな課題をもたらすことを、多数の実験を通じて証明しました。研究チームは、最先端の手法の失敗は、まず不均衡なテストデータに基づいて正規化層を無差別に調整することが原因であると考えています。
この目的を達成するために、研究チームは
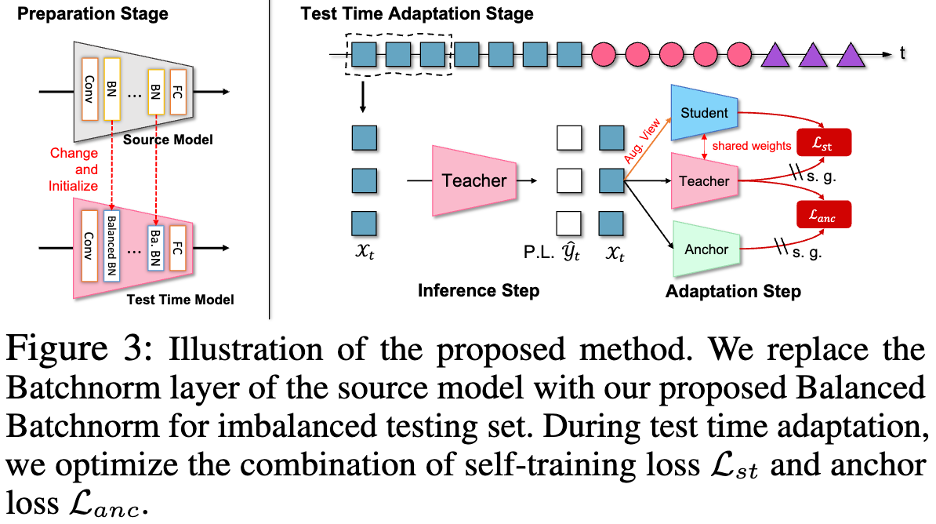
従来の推論フェーズのバッチ正規化層を置き換える革新的なBalanced BatchNorm層(Balanced BatchNorm層)を提案しました。同時に、未知のテスト データ ストリームでの学習を自己トレーニング (ST) のみに依存すると、過剰適応 (疑似ラベル カテゴリの不均衡、ターゲット ドメインが固定ドメインではない) につながりやすく、その結果、パフォーマンスが低下する可能性があることがわかりました。変化するドメインでのパフォーマンス。 したがって、チームは
アンカー損失 (アンカー損失) を通じてモデル更新を正規化することを推奨します これにより、継続的なドメイン転送の下での自立性が向上します トレーニングは大幅に役立ちますモデルの堅牢性が向上します。最終的に、モデル TRIBE は 4 つのデータ セットと複数の実世界テスト データ ストリーム設定の下で安定して最先端のパフォーマンスを達成し、既存の高度な手法を大幅に上回りました。研究論文がAAAI 2024に採択されました。 
論文リンク: https://arxiv.org/abs/2309.14949
コードリンク: https://github.com/Gorilla-Lab- SCUT/TRIBE
ディープ ニューラル ネットワークの成功は、トレーニングされたモデルをテスト ドメインの想定に合わせて一般化するかどうかにかかっています。 。ただし、実際のアプリケーションでは、異なる照明条件や悪天候によって引き起こされる視覚的な損傷など、配布外のテストデータの堅牢性が懸念されます。最近の研究では、このデータ損失が事前トレーニングされたモデルのパフォーマンスに重大な影響を与える可能性があることが示されています。重要なのは、テスト データの破損 (配布) は不明なことが多く、展開前には予測できない場合もあります。
したがって、推論段階でテスト データの分布に適応するように事前トレーニングされたモデルを調整することは、価値のある新しいトピック、つまりテスト時ドメイン適応 (TTA) です。これまで、TTA は主に分布調整 (TTAC、TTT)、自己教師ありトレーニング (AdaContrast)、および自己トレーニング (Conjugate PL) を通じて実装されていました。これにより、さまざまな視覚的損傷テスト データに大幅かつ堅牢な改善がもたらされました。
既存のテスト時ドメイン適応 (TTA) 方法は、通常、安定したクラス分布、サンプルが独立した同一分布のサンプリングに従う、固定ドメイン オフセットなど、いくつかの厳密なテスト データの仮定に基づいています。これらの仮定に触発されて、多くの研究者が CoTTA、NOTE、SAR、RoTTA などの現実世界のテスト データ フローを調査するようになりました。
最近、SAR (ICLR 2023) や RoTTA (CVPR 2023) などの現実世界の TTA に関する研究は、ローカル クラスの不均衡と TTA への継続的なドメイン シフトによってもたらされる課題に主に焦点を当ててきました。ローカル クラスの不均衡は、通常、テスト データが独立して同じように分散してサンプリングされていないという事実から生じます。直接的に無差別にドメインを適応させると、偏った分布推定が行われます。
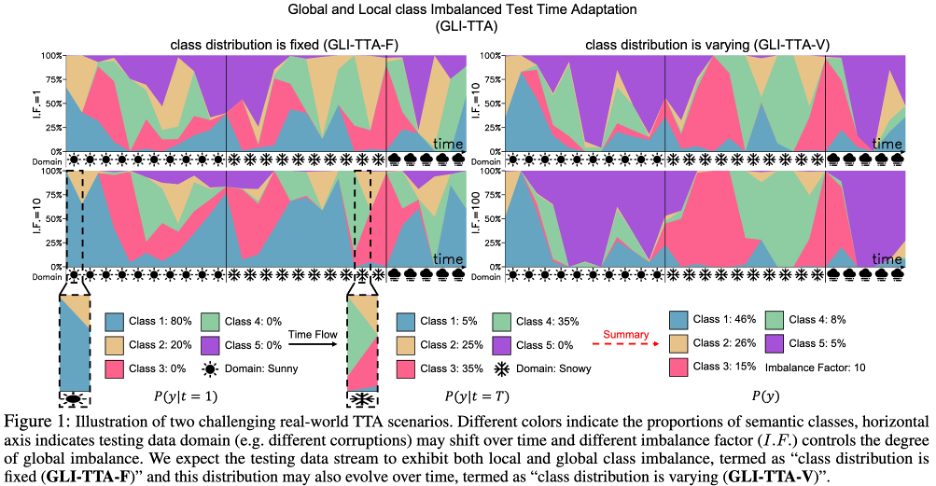
最近の研究では、この課題を解決するために、指数関数的に更新されるバッチ正規化統計 (RoTTA) またはインスタンス レベルの識別更新バッチ正規化統計 (NOTE) が提案されています。研究の目標は、テスト データの全体的な分布が著しく不均衡である可能性があり、クラスの分布も時間の経過とともに変化する可能性があることを考慮して、ローカル クラスの不均衡という課題を克服することです。より困難なシナリオの図を以下の図 1 に示します。
テスト データ内のクラスの蔓延は推論段階の前には不明であり、ブラインド テスト時間の調整によってモデルが多数派のクラスに偏る可能性があるため、既存の TTA メソッドは無効になります。経験的観察に基づくと、この問題は、正規化層 (BN、PL、TENT、CoTTA など) を更新するためのグローバル統計を推定するために現在のデータ バッチに依存する方法で特に顕著になります。 1. 現在のデータ バッチはローカル カテゴリの不均衡の影響を受け、全体的な分布推定に偏りが生じます。 2. グローバル クラスの不均衡を伴うテスト データ全体から単一のグローバル分布を推定する グローバル分布は容易に多数派クラスに偏り、内部共変量シフトが発生する可能性があります。 偏ったバッチ正規化 (BN) を回避するために、チームはバランスの取れたバッチ正規化レイヤー (バランス バッチ正規化レイヤー) を提案しました。モデル化され、クラス分布からグローバル分布が抽出されます。バランスの取れたバッチ正規化レイヤーにより、ローカルおよびグローバルにクラス不均衡なテスト データ ストリームの下で、クラスバランスのとれた分布推定値を取得できます。
ドメインのシフトは、照明や気象条件の段階的な変化など、時間の経過とともに現実世界のテスト データで頻繁に発生します。これは、既存の TTA 方法に別の課題をもたらします。ドメイン A への過剰適応により、ドメイン A からドメイン B に切り替えるときに TTA モデルが矛盾する可能性があります。
特定の短期領域への過剰適応を軽減するために、CoTTA はパラメータをランダムに復元し、EATA はフィッシャー情報を使用してパラメータを正規化します。それにもかかわらず、これらの方法は、テスト データの分野で新たに生じている課題にまだ明示的に対処していません。
この記事では、2 ブランチ自己トレーニング アーキテクチャに基づいた 3 ネットワーク自己トレーニング モデル (Tri-Net Self-Training) を形成するためのアンカー ネットワーク (Anchor Network) を紹介します。アンカー ネットワークは凍結されたソース モデルですが、テスト サンプルを介してバッチ正規化レイヤーのパラメーターではなく統計を調整できます。また、アンカリング損失は、アンカー ネットワークの出力を使用して教師モデルの出力を正規化し、ネットワークが局所的な分布に過剰に適応するのを避けるために提案されています。
最終モデルは、3 ネット セルフ トレーニング モデルとバランスのとれたバッチ正規化レイヤー (BalancEd 正規化を備えた TRI-ネット セルフ トレーニング、TRIBE) を組み合わせて、調整可能な学習率のより広い範囲で良好なパフォーマンスを発揮します。優れた性能。これは、4 つのデータ セットと複数の実世界のデータ ストリームの下で大幅なパフォーマンスの向上を示し、独自の安定性と堅牢性を示しています。
##ペーパーメソッドは 3 つの部分に分かれています:
- 実世界における TTA プロトコルの紹介;
- バランスのとれたバッチ正規化;
- 3 つのネットワークの自己学習モデル。
#現実世界の TTA プロトコル
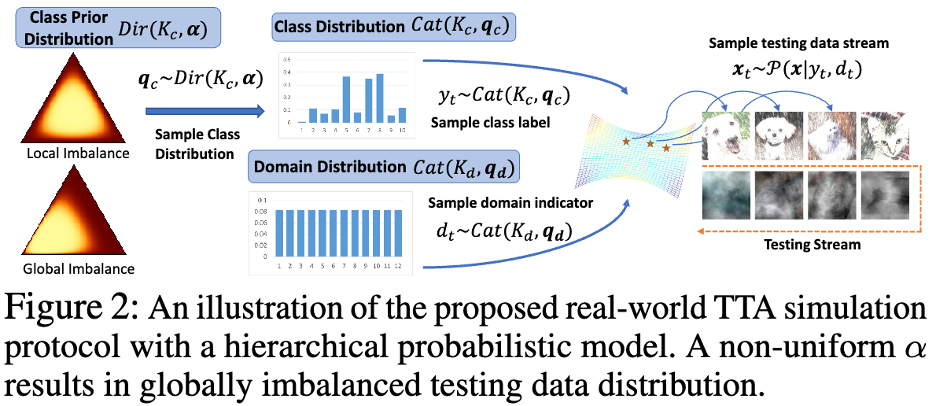
##著者は数学的確率モデルを使用して、ローカル クラスの不均衡とグローバル クラスの不均衡、および時間の経過とともに変化するドメイン分布を含む現実世界のテスト データ フローをモデル化します。以下の図 2 に示すように。 #バランスバッチ正規化
BN の不均衡なテストデータを修正するには統計によって生成されるバイアスを推定するために、著者はバランスの取れたバッチ正規化層を提案します。これは、次のように表現される各セマンティック クラスの統計のペアを維持します。
カテゴリ統計を更新するには、著者は、以下に示すように、擬似ラベル予測を利用して効率的な反復更新方法を適用します。 疑似ラベルを使用してデータの各カテゴリのサンプリング ポイントを個別にカウントし、次の式を使用してカテゴリ バランスの下で全体の分布統計を再取得し、ソースを揃えます。カテゴリバランス データ学習に適した特徴空間。 いくつかの特殊なケースでは、カテゴリの数が大きいまたは擬似ラベルの精度が低い(精度
さらなる分析と観察を通じて、著者は、 γ = 1 の場合、γ = 0 の場合、更新戦略全体が RoTTA の RobustBN 更新戦略に縮退することがわかりました。γ = 0 の場合、純粋にカテゴリーに依存しない更新戦略です。したがって、γ が 0 ~ 1 の値を取る場合、 、さまざまな状況に適応できます。 著者いくつかの生徒-教師モデルに基づいて、アンカリング ネットワーク ブランチが追加され、アンカリング損失が導入されて教師ネットワークの予測分布が制限されます。このデザインはTTACからインスピレーションを得たものです。 TTAC は、テスト データ ストリームでの自己学習のみに依存すると、確証バイアスの蓄積につながりやすいと指摘していますが、この問題は、この記事で取り上げる現実世界のテスト データ ストリームではより深刻です。 TTAC は、ソース ドメインから収集された統計情報を使用してドメイン アラインメントの正規化を実装しますが、完全な TTA 設定の場合、このソース ドメイン情報は収集できません。 同時に、著者は別の啓示も得ました。教師なしドメイン アライメントの成功は、2 つのドメイン分布の重複率が比較的高いという仮定に基づいています。したがって、著者は、教師モデルの予測分布がソース モデルの予測分布から大きく逸脱しないように、BN 統計量の凍結されたソース ドメイン モデルを調整して教師モデルを正規化するだけでした (これにより、2 つの間の高い一致率という以前の経験が破壊されました)分布)観察)。多数の実験により、この記事の発見と革新が正しく、確実であることが証明されています。アンカリング損失の式は次のとおりです。
# 次の図は、TRIBE ネットワークのフレーム図を示します。
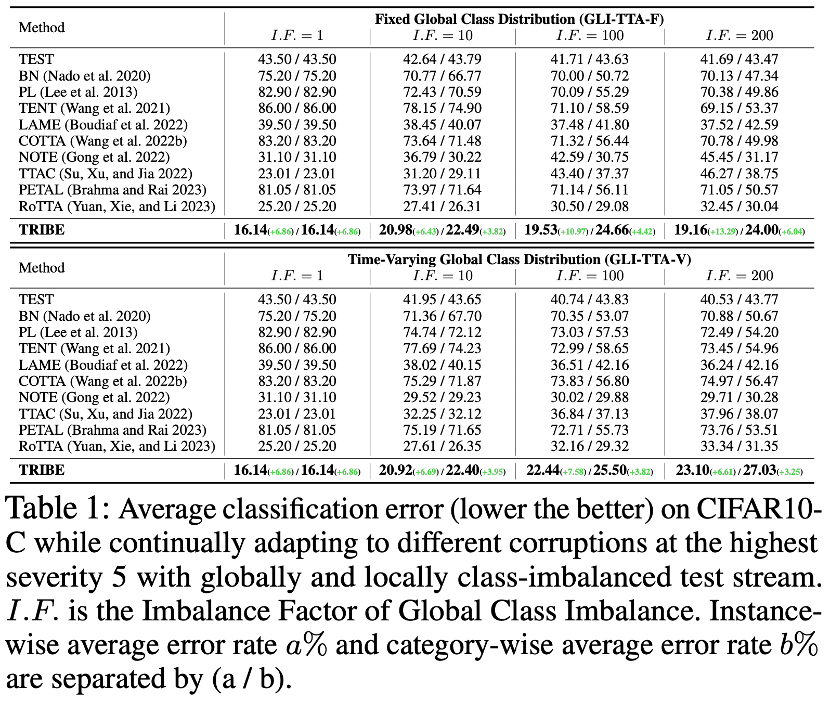
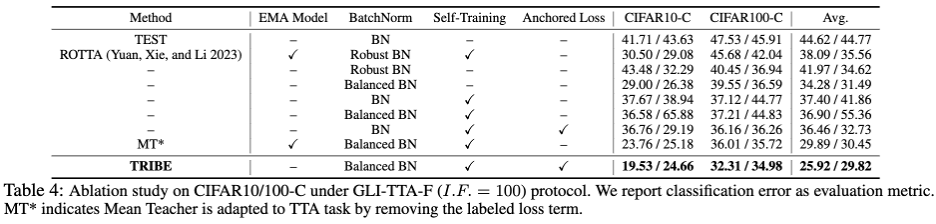
論文の著者は、2 つの実際の TTA プロトコルに基づいて 4 つのデータセットに対して TRIBE を実施しました。検証されました。実際の TTA プロトコルには、グローバル クラス分布が固定されている GLI-TTA-F と、グローバル クラス分布が固定されていない GLI-TTA-V の 2 つがあります。 上の表は、異なる不均衡係数の下での CIFAR10-C データセット内の 2 つのプロトコルのパフォーマンスを示しています。次の結論が得られます: 1. のみ論文で提案されている LAME、TTAC、NOTE、RoTTA、および TRIBE は TEST ベースラインを超えており、実際のテスト フローではより堅牢な TTA 手法の必要性を示しています。 2. グローバル クラスの不均衡は、既存の TTA メソッドに大きな課題をもたらしています。たとえば、以前の SOTA メソッド RoTTA は、I.F.=1 の場合に 25.20% のエラー率を示しましたが、 I.F.=200ではエラー率が32.45%まで上昇しますが、それに比べてTRIBEは比較的良好なパフォーマンスを安定して発揮できます。 3. TRIBE の一貫性は、これまでのすべてのメソッドを上回り、以前の SOTA を超える絶対的な利点があります (グローバル クラス バランス (I.F.=1) TTAC の設定の下) ) 約 7% 向上し、より困難なグローバル クラス インバランス (I.F.=200) 設定では約 13% のパフォーマンス向上を達成しました。 4. I.F.=10 から I.F.=200 まで、他の TTA メソッドは、不均衡が増大するにつれてパフォーマンスが低下する傾向を示します。 TRIBEは比較的安定したパフォーマンスを維持できます。これは、深刻なクラスの不均衡とアンカリング損失をより適切に考慮するバランスの取れたバッチ正規化レイヤーの導入によるもので、異なるドメインにわたる過剰適応が回避されます。 データセットの結果の詳細については、元の論文を参照してください。 さらに、表 4 はモジュール式アブレーションの詳細を示しており、以下の観察結果が得られます。
1. のみBN をバランスの取れたバッチ正規化層 (Balanced BN) に置き換え、モデル パラメーターを更新せず、フォワードを通じて BN 統計のみを更新すると、10.24% (44.62 -> 34.28) のパフォーマンス向上がもたらされ、Robust BN の誤差を上回ります。率は41.97%。 2. 以前の BN 構造でも最新のバランス BN 構造でも、アンカー損失とセルフトレーニングを組み合わせると、パフォーマンスが向上し、モデルの EMA 正則化効果を上回りました。 この記事の残りの部分と 9 ページの付録では、最後に 17 件の詳細な表結果を示し、TRIBE の安定性、堅牢性、優位性を多面的に示します。付録には、バランスのとれたバッチ正規化層のより詳細な理論的導出と説明も含まれています。
##実世界 非 i.i.d. テスト データ フロー、世界的なクラスの不均衡、継続的なドメイン転送などの多くの課題に直面して、研究チームはテスト時のドメイン適応アルゴリズムの堅牢性を向上させる方法を深く検討しました。不均衡なテストデータに適応するために、著者は統計の不偏推定を実現する平衡バッチノーム層を提案し、その後、生徒ネットワーク、教師ネットワーク、アンカーネットワークを含むネットワークを提案しました。自己トレーニングをベースにしたTTA。
しかし、この記事にはまだ欠点があり、改善の余地があります。多くの実験と出発点は分類タスクと BN モジュールに基づいているため、適応させる必要はありません他のタスクや Transformer ベースのモデルに影響を与える可能性がありますが、その程度は不明です。これらの問題は、フォローアップ作業でさらなる研究と調査が必要です。
以上がTRIBE はドメイン適応の堅牢性を実現し、複数の現実のシナリオで SOTA の AAAII 2024 に到達します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




 #バランスバッチ正規化
#バランスバッチ正規化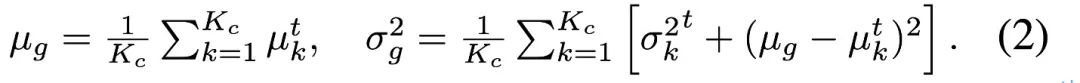
 または擬似ラベルの精度が低い(精度
または擬似ラベルの精度が低い(精度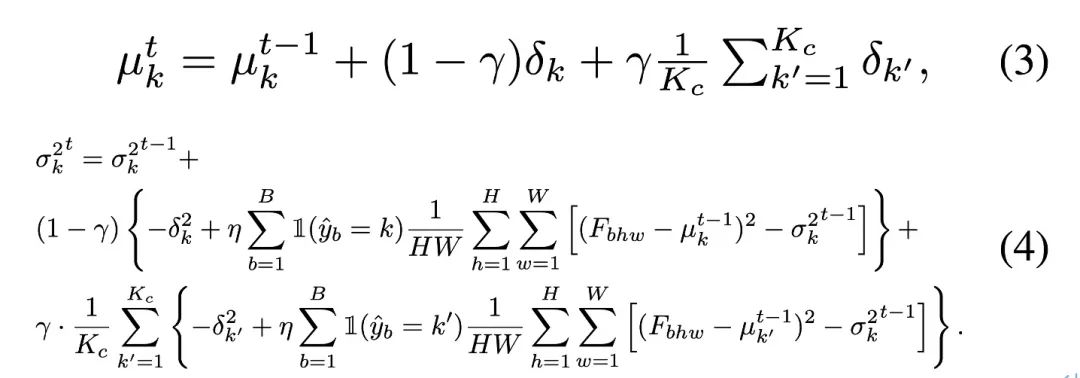
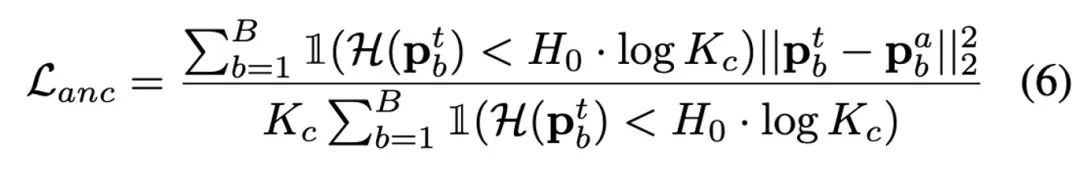
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



