###導入###
| プログラミングの道を歩み始めたら、コーディングの問題を理解していないと、キャリアを通じてその問題が幽霊のように付きまとうことになり、さまざまな超自然的な出来事が次から次へと続いて尾を引くことになります。プログラマーの最後まで戦う精神を発揮してこそ、コーディングの問題によるトラブルを完全になくすことができます。
|
私が初めてコーディングの問題に遭遇したのは、JavaWeb 関連のプロジェクトを書いているときでした。文字列がブラウザからアプリケーション コードにさまよって、データベースに埋め込まれました。コーディングの地雷を踏む可能性があります。いつでもどこでも。 2 回目にコーディングの問題に遭遇したのは、Python を学習していたときでした。Web ページのデータをクロールしているときに、再びコーディングの問題が発生しました。その時、私の気分は崩壊しました。現在、最も人気のある文は次のとおりです。「当時は混乱していました」 。」。
文字エンコーディングを理解するには、コンピューターの起源から始める必要があります。コンピューター内のすべてのデータは、テキスト、画像、ビデオ、またはオーディオ ファイルであっても、最終的には 01010101 のようなデジタル形式で保存されます。 「私たちは幸運であり、同時に不幸でもあります。幸運なことに、時代は私たちにコンピューターに触れる機会を与えてくれました。残念なことに、コンピューターは私たちの同胞によって発明されたものではないので、コンピューターの標準は国民の習慣に従って設計されなければなりません」アメリカ帝国. 結局のところ、コンピューターは最初にどのようにして文字を表現したのでしょうか?これはコンピューターコーディングの歴史から始まります。
アスキー
JavaWeb 開発を行うすべての初心者は、文字化けしたコードの問題に遭遇するでしょうし、Python クローラーを行うすべての初心者は、エンコードの問題に遭遇するでしょう。エンコードの問題はなぜそれほど苦痛なのでしょうか?この問題は、Guido van Rossum が 1992 年に Python 言語を作成したときに始まりました。当時、Guido は Python 言語が今日これほど普及するとは予想していなかったし、コンピューター開発の速度がこれほど驚くべきものになるとは予想していませんでした。グイド氏が最初にこの言語を設計したとき、エンコードについて気にする必要はありませんでした。英語の世界では、文字数が非常に限られており、26 文字 (大文字と小文字)、10 個の数字、句読点、および制御文字であるためです。 、キーボード上の すべてのキーに対応する文字を合計すると、100 文字強になります。 1 バイトは 8 ビットに相当し、8 ビットは 256 個のシンボルを表現できるため、コンピュータで 1 文字を表すのに 1 バイトの記憶域を使用するには十分です。そこで、賢明なアメリカ人は、ASCII (American Standard Code for Information Interchange) と呼ばれる一連の文字エンコード標準を開発しました。各文字は一意の番号に対応します。たとえば、文字 A に対応する 2 進値は 01000001 で、対応する 10 進値は 65 です。当初、ASCII は 128 文字コードのみを定義していました (96 個のテキスト記号と 32 個の制御記号を含む、合計 128 文字)。すべての文字を表すには 1 バイトのうち 7 ビットだけが必要なので、ASCII は 1 バイトのみを使用します。最後の 7 ビットと最上位ビットはすべて0です。
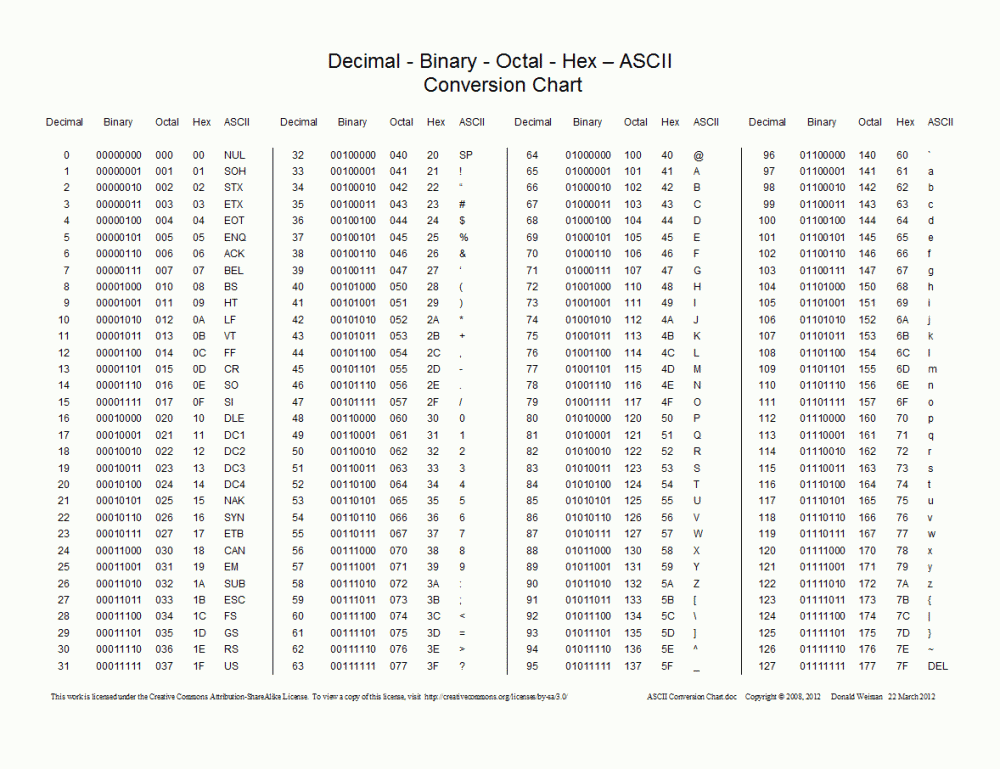
EASCII (ISO/8859-1)
しかし、コンピュータが他の西ヨーロッパ地域にもゆっくりと普及すると、ASCII エンコーディング テーブルにはない西ヨーロッパ固有の文字が多数あることがわかり、後に EASCII と呼ばれる拡張可能な ASCII が登場しました。 ASCII をベースにしています オリジナルの 7 ビットをベースに 8 ビットに拡張されています ASCII と完全な互換性があります 拡張されたシンボルには、表記号、計算記号、ギリシャ文字、特殊なラテン文字が含まれますしかし、EASCII 時代は混沌とした時代です。統一された規格はありません。それぞれが独自の規格に従って、最上位ビットを使用して独自の文字エンコード規格セットを実装しています。より有名なものは、CP437、 CP437 は Windows システムです。以下に示すように、 で使用される文字エンコーディング:
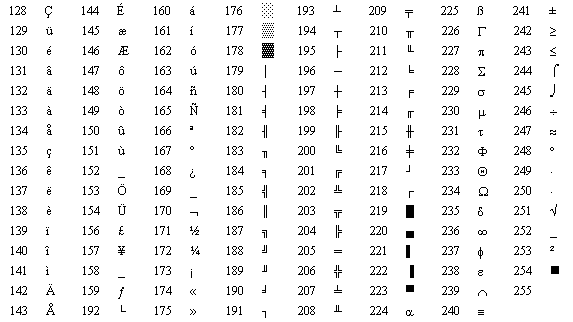
もう 1 つの広く使用されている EASCII は ISO/8859-1(Latin-1) です。これは、国際標準化機構 (ISO) と国際電気標準会議 (IEC) が共同開発した一連の 8 ビット コードです。文字セット標準である ISO/8859-1 は、CP437 文字エンコーディングの 128 ~ 159 の間の文字のみを継承するため、160 から定義されます。残念ながら、これらの多数の ASCII 拡張文字セットには相互互換性がありません。

GBK
時代が進むにつれて、コンピュータは何千もの家庭に普及し始め、ビル・ゲイツは、誰もがデスクトップにコンピュータを置くという夢を実現させます。しかし、コンピュータが中国に参入する際に直面しなければならない問題の 1 つは、文字エンコーディングです。我が国の漢字は人間が最も頻繁に使用する文字ですが、漢字は広く奥が深く、常用漢字は数万種類あります。 EASCII ですら大したものではないと思われたため、賢明な中国人は GB2312 (GB0 とも呼ばれる) と呼ばれる独自のコード セットを作成し、国家によって公開されました。 1981 年に中国標準管理局。 GB2312 エンコードには合計 6763 個の漢字が含まれており、ASCII とも互換性があります。 GB2312 の登場は基本的に漢字のコンピュータ処理ニーズを満たしており、GB2312 に含まれる漢字は中国本土での使用頻度の 99.75% をカバーしています。しかし、GB2312 は依然として漢字のニーズを 100% 満たすことができず、一部の希少文字や繁体字を扱うことができず、その後 GB2312 をベースにして GBK と呼ばれるコードが作成されました。 GBKには27,484文字の漢字だけでなく、チベット語、モンゴル語、ウイグル語などの主要な少数民族言語も含まれています。 GBK も同様に ASCII エンコーディングと互換性があり、英語は 1 バイト、中国語は 2 バイトで表現されます。
ユニコード
中国語の文字を扱うために別の山を設け、独自のニーズに応じて一連のコーディング標準を開発することもできますが、コンピューターはアメリカ人や中国人だけでなく、ヨーロッパや他の国の文字も使用しています。アジアなど 世界中の日本語と韓国語の文字の総数は数十万と推定されており、これは ASCII コードや GBK でさえ表現できる範囲をはるかに超えています。さらに、なぜ人々はあなたの GBK 標準を使用するのでしょうか?この膨大なキャラクターライブラリをどうやって表現するのか?そこで、United Alliance International Organization が Unicode エンコーディングを提案しました。Unicode の学名は「Universal Multiple-Octet Coded Character Set」、UCS と呼ばれます。

Unicode には、UCS-2 と UCS-4 の 2 つの形式があります。 UCS-2 はエンコードに 2 バイトを使用し、合計 16 ビットを使用します。理論的には、最大 65536 文字を表現できます。ただし、世界中のすべての文字を表現するには、65536 個近くあるため、65536 個の数値では明らかに不十分です。漢字だけで 100,000 文字あるため、Unicode 4.0 仕様では追加の文字エンコーディングのセットが定義されています。UCS-4 は 4 バイトを使用します (実際には 31 ビットのみが使用され、最上位ビットは 0 でなければなりません)。
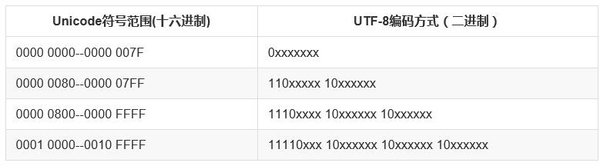
Unicode は理論的にはすべての言語で使用される記号をカバーできます。世界中のどの文字も Unicode エンコーディングで表すことができ、文字の Unicode エンコーディングは一度決定されると変更されません。ただし、Unicode には特定の制限があります。Unicode 文字がネットワーク上で送信されるとき、または最終的に保存されるとき、必ずしも各文字に 2 バイトを必要とするわけではありません。たとえば、1 つの文字「A」は 1 バイトで表現できます。 2 バイトですが、これは明らかにスペースの無駄です。 2 番目の問題は、Unicode 文字がコンピュータに保存されるとき、それは 01 の数字の文字列であるということです。では、コンピュータは、2 バイトの Unicode 文字が 2 バイト文字を表しているのか、それとも 2 つの 1 バイト文字を表しているのかをどのようにして認識するのでしょうか?事前にコンピュータに伝えておかないと、コンピュータも混乱してしまいます。 Unicode はエンコード方法のみを規定しており、このエンコードを送信または保存する方法は規定していません。たとえば、文字「汉」の Unicode エンコードは 6C49 です。このエンコードを送信および保存するには 4 つの ASCII 数値を使用できます。また、UTF-8 でエンコードされた連続 3 バイト E6 B1 89 を使用してそれを表すこともできます。重要なのは、コミュニケーションの双方の当事者が同意する必要があるということです。したがって、Unicode エンコードには、UTF-8、UTF-16 などのさまざまな実装方法があります。ここでの Unicode は英語と同じで、国家間の通信のための世界標準であり、各国が独自の言語を持ち、英語の標準文書を自国のテキストに翻訳するという、UTF-8 と同様の実装方法です。
UTF-8
UTF-8 (Unicode Transformation Format) は Unicode の実装であり、インターネットで広く使用されており、特定の状況に応じて 1 ~ 4 バイトを使用して文字を表現できる可変長の文字エンコーディングです。たとえば、本来 ASCII コードで表現できる英語の文字は、ASCII と同じ UTF-8 で表現すると 1 バイトのスペースだけで済みます。マルチバイト (n バイト) 文字の場合、最初のバイトの最初の n ビットは 1 に設定され、n 番目のビットは 0 に設定され、後続のバイトの最初の 2 ビットは 10 に設定されます。残りの 2 進数には、文字の UNICODE コードが埋められます。
漢字「良」を例にとると、「良」に対応するUnicodeは597D、対応する間隔は0000 0800 -- 0000 FFFFとなるため、UTF-8で表現すると格納するのに3バイト必要となります。 597D はバイナリで表現されます。 : 0101100101111101、1110xxxx 10xxxxxx 10xxxxxx を入力すると、11100101 10100101 10111101、16 進数に変換: E5A5BD、つまり、「適切な」Unicode「597D」に対応する UTF-8 エンコーディングは「E5A5」です。 BD」。
中国製品
ユニコード 0101 100101 111101
エンコードルール 1110xxxx 10xxxxxx 10xxxxxx
------------------------
utf-8 11100101 10100101 10111101
------------------------
16 進数の utf-8 e 5 a 5 b d
Python 文字エンコーディング
いよいよ理論を完成させます。 Python でのコーディングの問題について話しましょう。 Python は Unicode よりもはるかに早く誕生し、Python のデフォルトのエンコーディングは ASCII です。
>>> インポート システム
>>> sys.getdefaultencoding()
'アスキー'
したがって、Python ソース コード ファイルでエンコーディングが明示的に指定されていない場合、構文エラーが発生します。
リーリー
「こんにちは」を印刷
上記は test.py スクリプトです、run
リーリー
には次のエラーが含まれます:
リーリー
ソース コードで非 ASCII 文字をサポートするには、ソース ファイルの 1 行目または 2 行目でエンコード形式を明示的に指定する必要があります。
リーリー
または次のようになります:
リーリー
Python の文字列に関連するデータ型は str と unicode です。これらはどちらも basestring のサブクラスです。str と unicode は 2 つの異なる型であることがわかります。タイプのオブジェクト。
リーリー
同じ漢字「好」を str で表すと、UTF-8 エンコーディング '/xe5/xa5/xbd' に対応し、Unicode で表すと、対応する記号は次のようになります。 u'/u597d' は、u「良い」と同等です。 str 型文字の特定のエンコード形式は、オペレーティング システムに応じて、UTF-8、GBK、またはその他の形式であることを付け加えておきます。たとえば、Windows システムでは、cmd コマンド ラインは次のように表示されます:
リーリー
Linux システムのコマンド ラインに表示される内容は次のとおりです:
リーリー
Python3x、Java、その他のプログラミング言語のいずれであっても、Unicode エンコードが言語のデフォルトのエンコード形式になっています。データが最終的にメディアに保存されるとき、メディアごとに異なる方法を使用できます。UTF を使用することを好む人もいます。 8 、GBK を使用することを好む人もいますが、プラットフォームに統一されたエンコード標準がある限り、それがどのように実装されているかは問題ではありません。
Str から Unicode への変換
それでは、Python で str と unicode の間で変換するにはどうすればよいでしょうか?これら 2 つの文字列型間の変換は、デコードとエンコードという 2 つのメソッドに依存します。
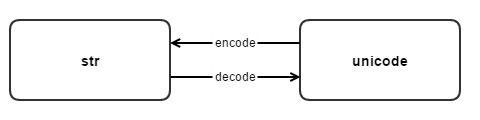 リーリー
リーリー
This'/xe5/xa5/xbd' は、関数 encode による Unicode u'hao'encoding によって取得された、UTF-8 でエンコードされた str 型文字列です。逆に、str 型 c は、関数 decode を通じて Unicode 文字列 d にデコードされます。
str と unicode
str(s) と unicode(s) は、それぞれ str 文字列オブジェクトと Unicode 文字列オブジェクトを返す 2 つのファクトリ メソッドです。str(s) は、s.encode(‘ascii’) の略称です。実験:###
リーリー
上記の s3 は Unicode 型の文字列です。str(s3) は s3.encode('ascii') を実行するのと同じです。中国語の 2 文字「Hello」は ASCII コードで表現できないため、エラーが報告されます。エンコーディング: s3.encode('gbk') または s3.encode('utf-8') では、この問題は発生しません。同様の Unicode にも同じエラーがあります:
リーリー
unicode(s4)s4.decode('ascii') と同等
したがって、正しく変換するには、そのエンコーディング s4.decode('gbk') または s4.decode('utf-8') を正しく指定する必要があります。
文字化け
文字化けの原因はすべて、次のような、さまざまなエンコードとデコード後の文字のエンコード プロセスで使用されるエンコード形式が一貫していないことに起因する可能性があります。
リーリー
UTF-8 でエンコードされた文字「好
」は 3 バイトを占めており、Unicode にデコードした後、GBK でデコードすると 2 バイトしかなく、結局文字化けしてしまいます。したがって、文字化けを防ぐ最善の方法は、文字のエンコードとデコードに常に同じエンコード形式を使用することです。
その他のヒント
Unicode 形式の文字列 (str 型) の場合:
リーリー
実際の Unicode に変換するには、以下を使用する必要があります:
リーリー
###テスト:###
リーリー
上記のコードと概念は Python2.x に基づいています。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



