アクティベーション関数は深層学習において重要な役割を果たしており、ニューラル ネットワークに非線形特性を導入することで、ネットワークが複雑な入出力関係をより適切に学習し、シミュレートできるようになります。活性化関数の正しい選択と使用は、ニューラル ネットワークのパフォーマンスとトレーニング効果に重要な影響を与えます。
この記事では、一般的に使用される 4 つの活性化関数、Sigmoid、Tanh、ReLU、Softmax について、導入から使用方法まで紹介します。シナリオ、利点、欠点、最適化ソリューションについて 5 つの側面で説明し、アクティベーション関数を包括的に理解できるようにします。

##1. シグモイド関数
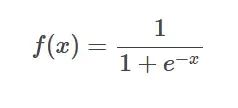 シグモイド関数の公式
シグモイド関数の公式
はじめに: シグモイド関数は一般的に A任意の実数を 0 と 1 の間にマッピングできる非線形関数を使用しました。
正規化されていない予測値を確率分布に変換するためによく使用されます。
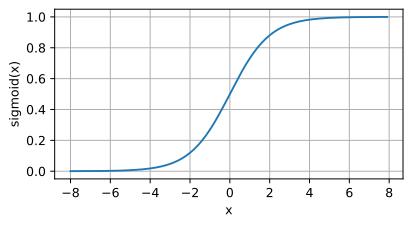 SIgmoid 関数のイメージ
SIgmoid 関数のイメージ
アプリケーション シナリオ:
出力は 0 から 1 の間に制限されており、確率分布。 - 回帰問題またはバイナリ分類問題を処理します。
-
次のような利点があります:
- 入力の任意の範囲を 0 ~ 1 の間の にマッピングできるため、確率を表現するのに適しています。
- 範囲が制限されているため、計算がより簡単かつ高速になります。
欠点: 入力値が非常に大きい場合、勾配が非常に小さくなり、勾配消失の問題が発生する可能性があります。
最適化計画:
-
ReLU などの他のアクティベーション関数を使用する: ReLU またはそのバリアント (Leaky ReLU および Parametric ReLU) などの他のアクティベーション関数を組み合わせて使用します。
-
深層学習フレームワークで最適化手法を使用する: TensorFlow や PyTorch などの深層学習フレームワークによって提供される最適化手法を使用します。勾配クリッピング、学習率調整など。
2. Tanh 関数
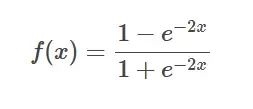 Tanh 関数の公式
Tanh 関数の公式
はじめに: T
anh 関数はシグモイドです任意の実数を -1 から 1 までにマッピングする関数の双曲線バージョン。
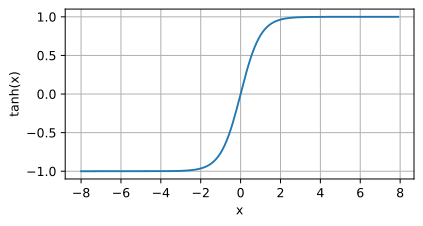 Tanh 関数のイメージ
Tanh 関数のイメージ
アプリケーション シナリオ: シグモイドより急峻な関数が必要な場合、または -1 ~ の範囲が必要な場合1 は特定のアプリケーションで必要な出力です。
次のような利点があります: ダイナミック レンジが大きくなり、曲線が急勾配になるため、収束速度が向上します。
Tanh 関数の欠点は、入力が±1、その導関数は急速に 0 に近づくため、勾配消失の問題が発生します
最適化計画:
-
他の活性化関数を使用してくださいReLU など:ReLU やそのバリアント (Leaky ReLU および Parametric ReLU) など、他のアクティベーション関数と組み合わせて使用します。
-
残留接続の使用: 残留接続は、ResNet (残留ネットワーク) などの効果的な最適化戦略です。
#3、
ReLU 関数
ReLU 関数の式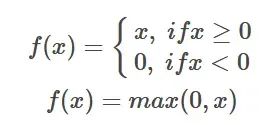 はじめに: ReLU 活性化関数は単純な非線形関数であり、その数式は f(x) = max(0,
はじめに: ReLU 活性化関数は単純な非線形関数であり、その数式は f(x) = max(0,
#x) です。入力値が 0 より大きい場合、ReLU 関数はその値を出力し、入力値が 0 以下の場合、ReLU 関数は 0 を出力します。
ReLU 関数のイメージ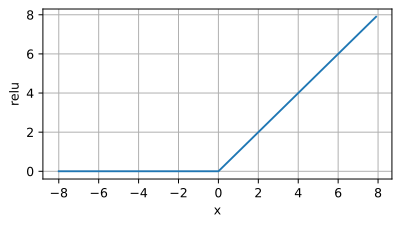 アプリケーション シナリオ: ReLU 活性化関数は、深層学習モデル、特に畳み込みニューラル ネットワーク (CNN) 中間で広く使用されています。 。その主な利点は、計算が簡単で、勾配消失問題を効果的に軽減できること、および
アプリケーション シナリオ: ReLU 活性化関数は、深層学習モデル、特に畳み込みニューラル ネットワーク (CNN) 中間で広く使用されています。 。その主な利点は、計算が簡単で、勾配消失問題を効果的に軽減できること、および
によりモデルのトレーニングを高速化できることです。したがって、ReLU は、ディープ ニューラル ネットワークをトレーニングする際に優先される活性化関数としてよく使用されます。
次の利点があります:
-
勾配消失問題の軽減: Sigmoid や Tanh などの活性化関数との比較、ReLU活性化値の方が効率的です。これが正の場合、勾配が小さくならないため、勾配消失の問題が回避されます。
-
トレーニングの高速化: ReLU のシンプルさと計算効率により、モデルのトレーニング プロセスを大幅に高速化できます。
欠点:
-
「死んだニューロン」問題: 入力値が小さい場合または 0 に等しい場合、ReLU の出力は 0 になり、ニューロンが機能しなくなります。この現象は「デッド ニューロン」と呼ばれます。
-
非対称性: ReLU の出力範囲は [0, ∞) であり、入力値が負の数の場合、出力はこれにより、ReLU 出力の非対称分布が生じ、生成の多様性が制限されます。
最適化計画:
-
リーキー ReLU: リーキー ReLU入力が 0 以下の場合、出力の傾きは小さくなり、完全な「デッド ニューロン」問題が回避されます。
-
パラメトリック ReLU (PReLU): Leaky ReLU とは異なり、PReLU の傾きは固定されていませんが、次の条件に基づいて調整できます。データの最適化を学びます。
4. ソフトマックス関数
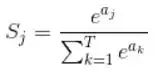 ソフトマックス関数の公式
ソフトマックス関数の公式
はじめに: Softmax は一般的に使用される活性化関数であり、主に多分類問題で使用され、入力ニューロンを確率分布に変換できます。主な特徴は、出力値の範囲が 0 ~ 1 であり、すべての出力値の合計が 1 になることです。
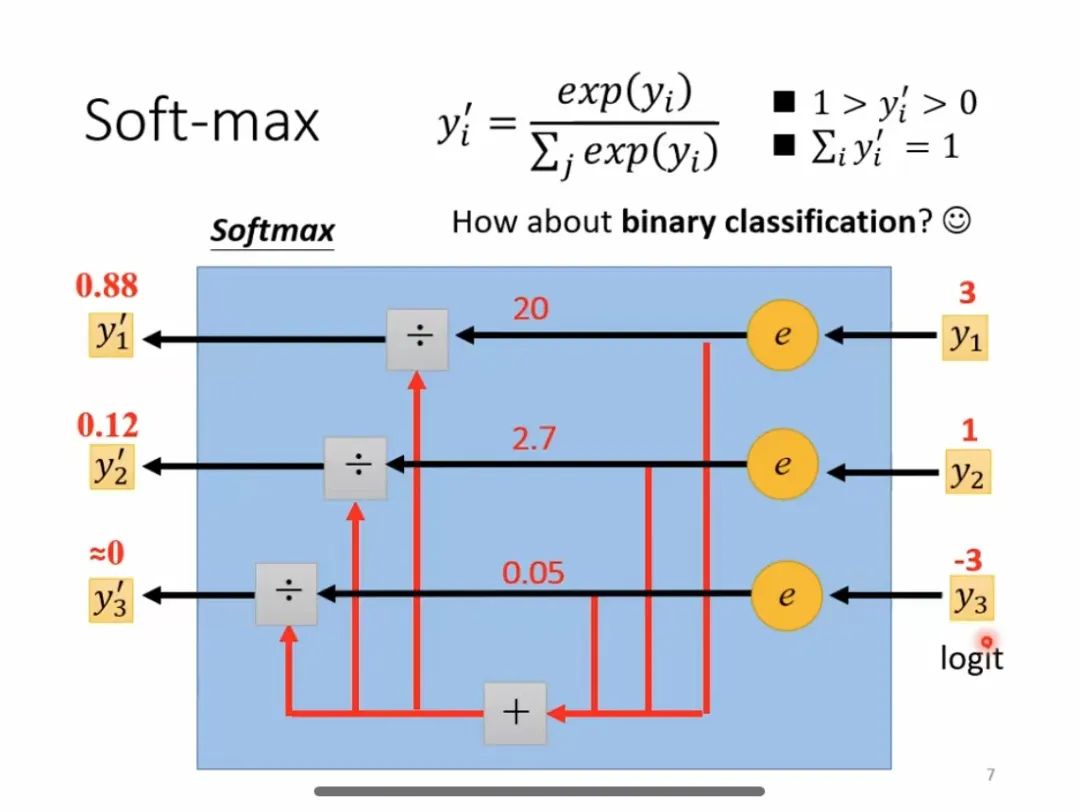 ソフトマックス計算プロセス
ソフトマックス計算プロセス
アプリケーション シナリオ:
- 複数分類タスクでは、Convert を使用しました。ニューラル ネットワークの出力を確率分布に変換します。
- 自然言語処理、画像分類、音声認識などの分野で広く使用されています。
次のような利点があります: 複数分類の問題では、各カテゴリに相対確率値を提供して、その後の意思決定と分類を容易にすることができます。
欠点: グラデーションの消失またはグラデーションの爆発の問題が発生します。
最適化スキーム:
-
ReLU などの他の活性化関数を使用する: 他の活性化関数を組み合わせて使用します。 ReLU またはその他のバリアント (Leaky ReLU および Parametric ReLU)。
- 深層学習フレームワークで最適化手法を使用する: バッチ正規化、重み減衰など、深層学習フレームワーク (TensorFlow や PyTorch など) によって提供される最適化手法を使用します。
以上が一般的に使用される AI 活性化関数の分析: Sigmoid、Tanh、ReLU、Softmax のディープラーニングの実践の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
































![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



