


Google DeepMindは12月15日、「FunSearch」と呼ばれるモデルトレーニング手法を発表した。このモデルは、「上位レベルの問題」や「ビンパッキング問題」を含む、一連の「数学とコンピュータサイエンスを含む複雑な問題」を解決できると言われています。
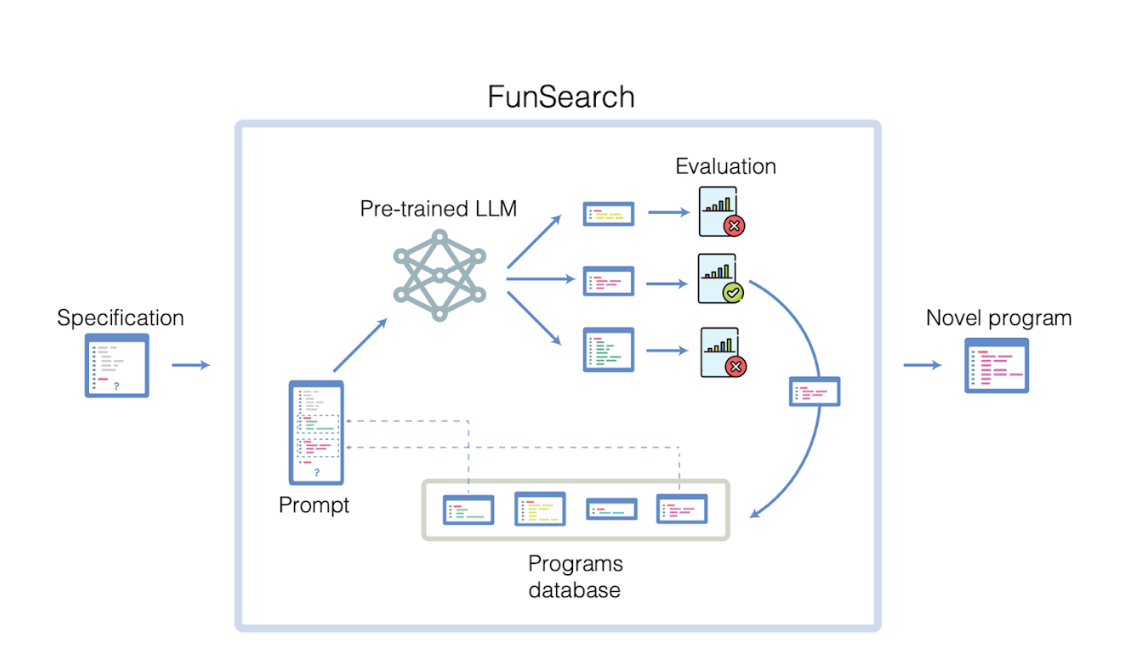
FunSearchモデルのトレーニング手法には、AIモデルが出力する創造的な問題解決手法を判定するために使用される「評価者」と呼ばれるシステムが導入されていると報告されています。このメソッドは反復を繰り返すことで、より強力な数学的機能を備えた AI モデルをトレーニングできます。
Google DeepMind は、テストに PaLM 2 モデルを使用しました。研究者らは専用のコード プールを確立し、コードの形式でモデルへの入力として一連の質問を使用し、評価プロセスをセットアップしました。各反復で、モデルはコード プールから問題を自動的に選択し、創造的な新しい解決策を生成し、それらを評価のために評価者に送信します。最適なソリューションは、コード プールに再度参加し、次の反復を開始します
FunSearch トレーニング メソッドは、このメソッドが「離散数学 (組み合わせ論)」で優れたパフォーマンスを発揮し、トレーニングされたモデルは極値の組み合わせ数学の問題を簡単に解決できることが IT House レポートで述べられています。研究者らはプレスリリースの中で、「カウントと順列を含む数学の中心的な問題である上位レベルの問題」のモデル計算に対する手続き的アプローチについて説明している。
さらに、研究者らは、FunSearch トレーニング メソッドを使用して、「異なるサイズのアイテムを最小数のコンテナに入れる」問題である「ビン パッキング問題」の解決にも成功しました。FunSearch は「ビン パッキング問題」です。 「アイテムの既存のボリュームに基づいて自動的に調整する」プログラムを生成する「オンザフライ」ソリューションを提供します。 
研究者らは、ニューラル ネットワークを使用して学習する他の AI トレーニング方法と比較して、FunSearch トレーニング方法でトレーニングされたモデルの出力コードはチェックとデプロイが容易であり、実際の産業への統合が容易であると述べています。環境の真ん中。 
以上がDeepMind は、AI モデルが離散数学的計算を実行できるようにする FunSearch トレーニング手法を公開しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



