



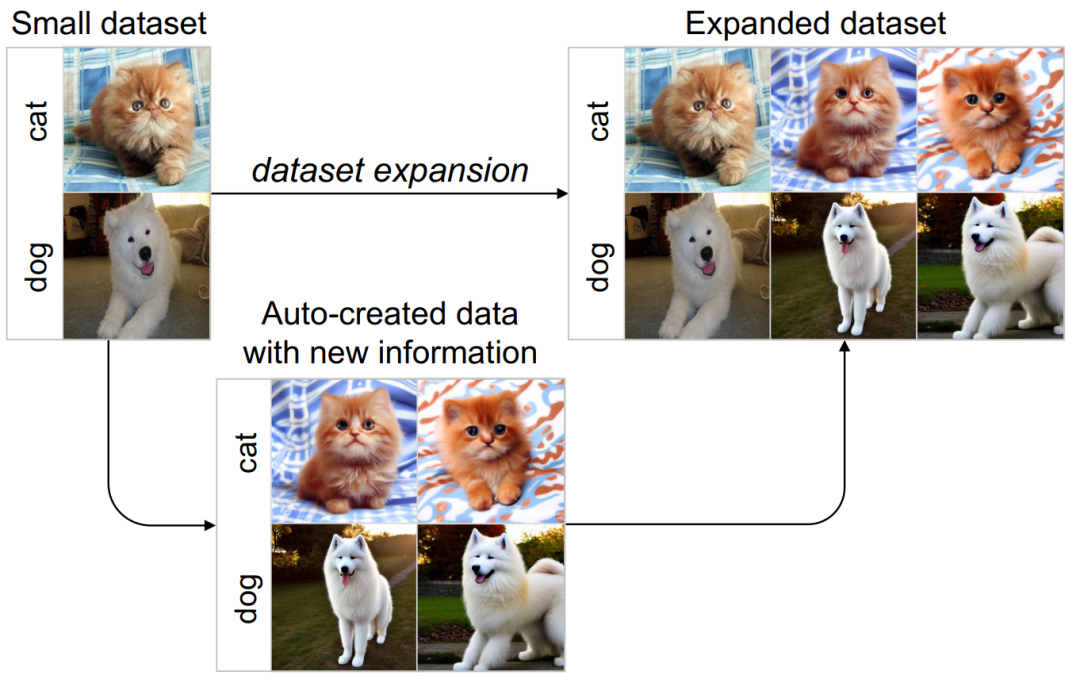
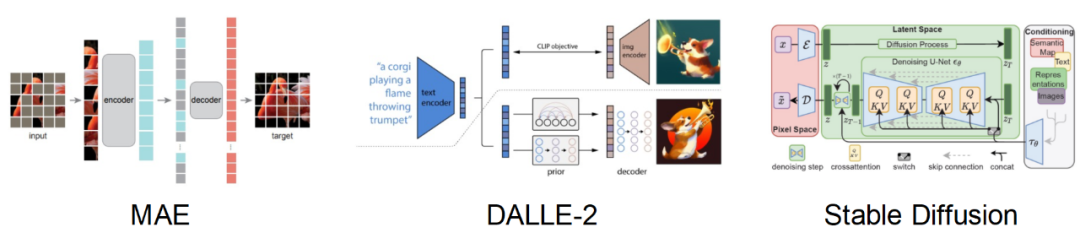
しかし、データ想像力のためのアプリオリなモデルとして人間を直接モデル化することはできません。幸いなことに、最近の生成モデル (安定拡散、DALL-E2 など) は、大規模なデータセットの分布に適合する強力な機能を実証しており、リッチでリアルな画像を生成できます。このことから、この論文では、事前にトレーニングされた生成モデルを事前モデルとして使用し、その強力な事前知識を活用して、小規模なデータセットに対して効率的なデータの関連付けと増幅を実行するようになりました。
上記のアイデアに基づいて、この研究は新しい Guided Imagination Framework (GIF) を提案します。この方法により、自然画像や医療画像のタスクに対するディープ ニューラル ネットワークの分類パフォーマンスと汎化能力が効果的に向上し、手動によるデータ収集と注釈付けによって生じる膨大なコストが大幅に削減されます。同時に、拡張されたデータセットはモデルの転移学習を促進し、ロングテール問題を軽減するのにも役立ちます。
次に、このデータセット増幅の新しいパラダイムがどのように設計されているかを見てみましょう。
データセット増幅の課題と指針となる標準データセット増幅を設計するには 2 つの方法があります。課題: (1) 生成されたサンプルに正しいカテゴリ ラベルを付けるにはどうすればよいでしょうか? (2) 生成されたサンプルにモデルのトレーニングを促進するための新しい情報が含まれていることを確認するにはどうすればよいですか?これら 2 つの課題に対処するために、この研究では広範な実験を通じて 2 つの増幅指針基準、(1) カテゴリ一貫した情報の強化、(2) サンプルの多様性の向上を発見しました。

方法論的フレームワーク発見された増幅指針基準に基づいて、この研究は、誘導された想像力の増幅フレームワークを提案します。 (GIF)。各入力シード サンプル x に対して、GIF は最初に前の生成モデルの特徴抽出器を使用してサンプル特徴 f を抽出し、特徴に対してノイズ摂動を実行します: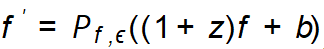 。ノイズ (z、b) を設定する最も簡単な方法は、ガウス ランダム ノイズを使用することですが、生成されたサンプルに正しいクラス ラベルが付けられ、より多くの情報がもたらされることを保証できません。したがって、効率的なデータセット増幅のために、GIF は発見された増幅ガイドライン、つまり
。ノイズ (z、b) を設定する最も簡単な方法は、ガウス ランダム ノイズを使用することですが、生成されたサンプルに正しいクラス ラベルが付けられ、より多くの情報がもたらされることを保証できません。したがって、効率的なデータセット増幅のために、GIF は発見された増幅ガイドライン、つまり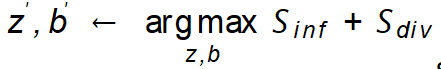 に基づいてノイズ摂動を最適化します。
に基づいてノイズ摂動を最適化します。
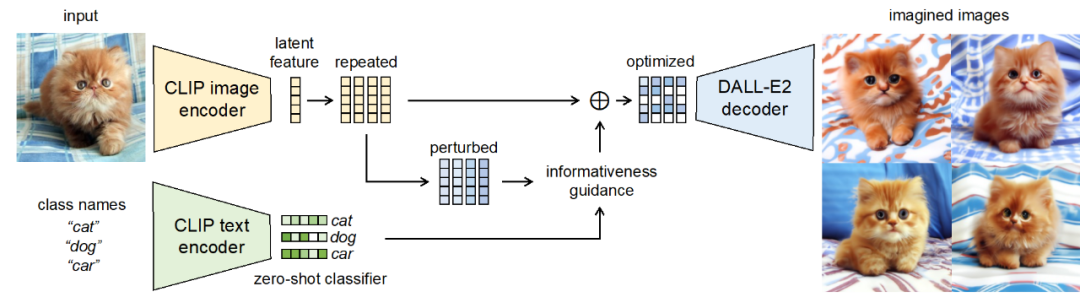
#使用される増幅ガイダンス標準は次のように実装されます。クラス一貫性のある情報量インデックス: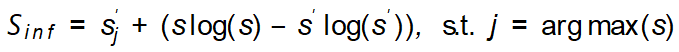 ; サンプル多様性インデックス:
; サンプル多様性インデックス: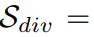
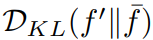 。これら 2 つの指標を最大化することで、GIF はノイズ摂動を効果的に最適化し、それによってカテゴリの一貫性を維持し、より多くの情報コンテンツをもたらすサンプルを生成できます。
。これら 2 つの指標を最大化することで、GIF はノイズ摂動を効果的に最適化し、それによってカテゴリの一貫性を維持し、より多くの情報コンテンツをもたらすサンプルを生成できます。
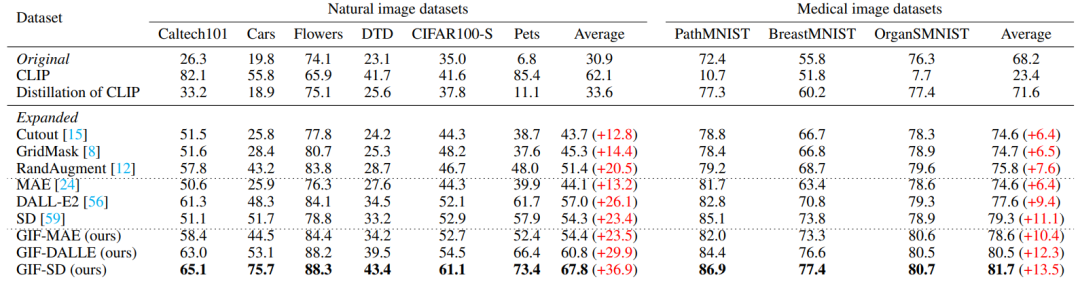
増幅効果GIF はより強い増幅効果を持っています: GIF-SD は、 6 つの自然データセットでは分類精度が平均 36.9% 向上し、3 つの医療データセットでは分類精度が平均 13.5% 向上しました。
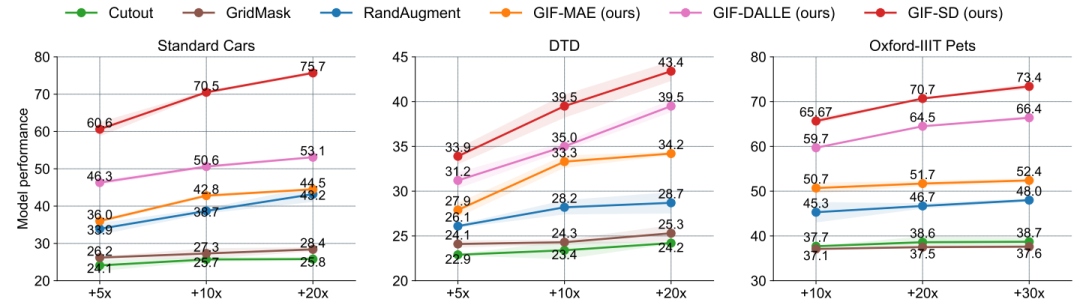
増幅効率GIF はより強い増幅効率を持っています: 車と DTD データセットでは、 GIF-SD を使用した 5 倍増幅の効果は、ランダム データ拡張を使用した 20 倍増幅の効果をも上回ります。
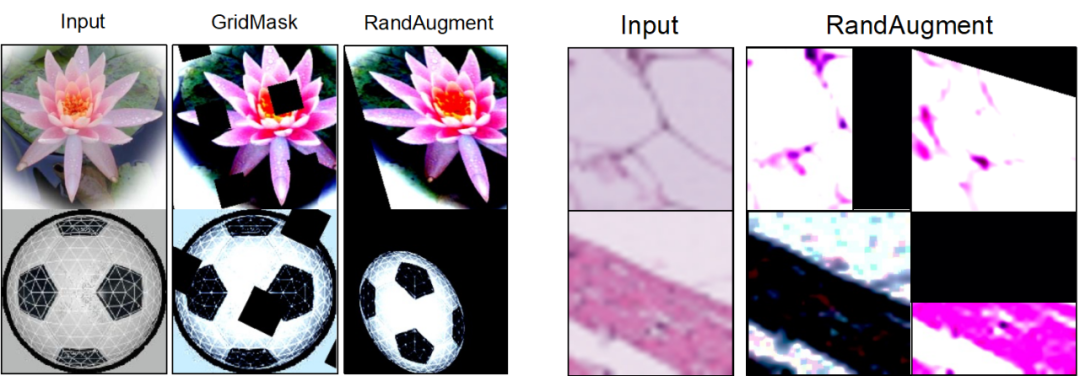
#可視化結果既存のデータ拡張手法では新しい画像コンテンツを生成できませんが、GIF の方がより適切に生成できます。新しいコンテンツを含むサンプル。
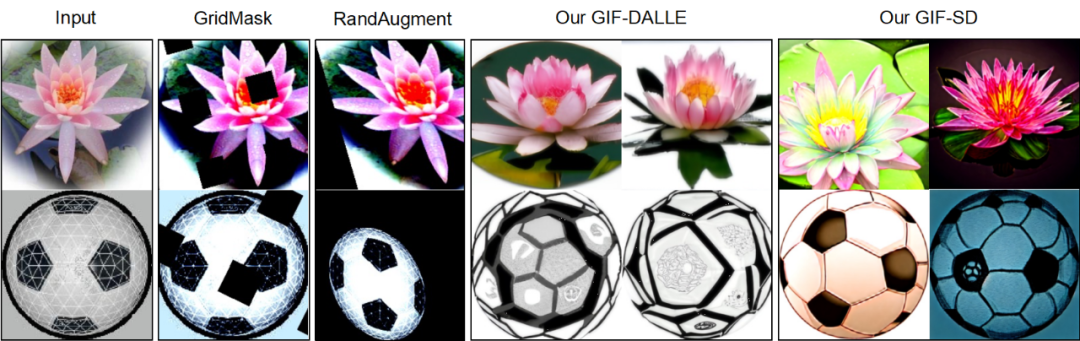
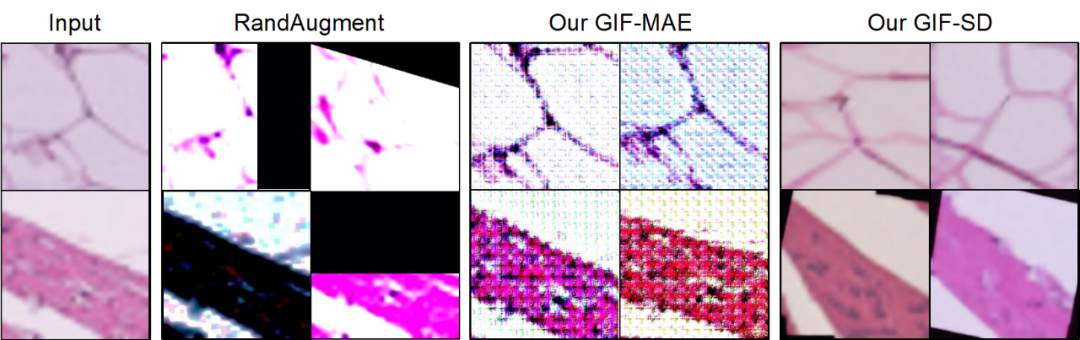
計算コストと時間コスト手動によるデータ収集と注釈と比較して、GIF は大幅にコストを削減できます。データセットの増強にかかる時間とコスト。

増幅されたデータの汎用性これらのデータセットは、増幅されると、さまざまなニューラル ネットワーク モデルのトレーニングに直接使用できます。構造。

#モデルの汎化能力の向上GIF は、モデルの分布外汎化パフォーマンスの向上に役立ちます(OOD の一般化)。

#ロングテール問題の軽減GIF はロングテール問題の軽減に役立ちます。

GIF によって生成された画像は安全で無害です。
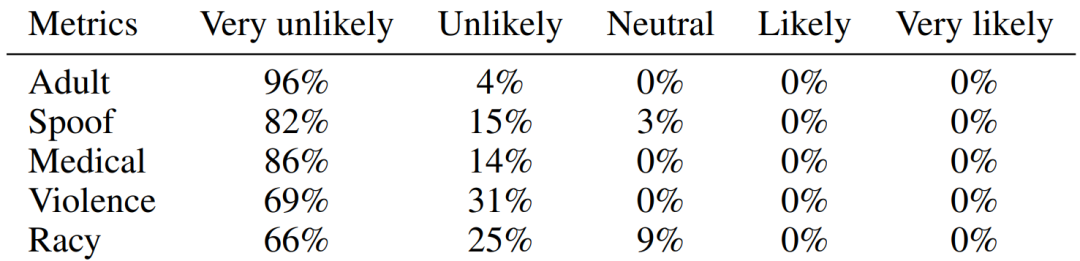 上記の実験結果に基づいて、人間の類推と想像力の学習をシミュレートすることにより、この論文で設計された方法が効果的に実行できると信じる理由があります。小規模データ セットを増幅することで、小規模データ タスク シナリオにおけるディープ ニューラル ネットワークの実装とアプリケーションが向上します。
上記の実験結果に基づいて、人間の類推と想像力の学習をシミュレートすることにより、この論文で設計された方法が効果的に実行できると信じる理由があります。小規模データ セットを増幅することで、小規模データ タスク シナリオにおけるディープ ニューラル ネットワークの実装とアプリケーションが向上します。
以上が新しい GIF フレームワークの紹介: 人間の例に倣い、データセット増幅の新しいパラダイムが到来の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



