回帰は統計における最も強力なツールの 1 つです。機械学習の教師あり学習アルゴリズムは、分類アルゴリズムと回帰アルゴリズムの 2 つのタイプに分類されます。回帰アルゴリズムは連続分布の予測に使用され、離散的なカテゴリ ラベルだけでなく連続的なデータを予測できます。
回帰分析は、製品の売上、交通の流れ、住宅価格、気象条件などの予測など、機械学習の分野で広く使用されています。
回帰アルゴリズムは、一般的に使用される機械学習です。変数 X と従属変数 Y の間の関係を自動的に確立するためのアルゴリズム。機械学習の観点から見ると、属性 X とラベル Y の間のマッピング関係を実現するためのアルゴリズム モデル (関数) を構築するために使用されます。学習プロセス中、アルゴリズムは適合度が最適になるように最良のパラメーター関係を見つけようとします。
回帰アルゴリズムでは、アルゴリズム (関数) の最終結果は連続データ値です。入力値 (属性値) は d 次元の属性/数値ベクトルです。
一般的に使用される回帰アルゴリズムには、線形回帰、多項式回帰、決定木回帰、リッジ回帰、ラッソ回帰、ElasticNet 回帰などが含まれます。
この記事では、いくつかの一般的な回帰アルゴリズムとそれぞれの特徴を紹介します
##線形回帰-
##多項式回帰
- サポート ベクター マシン回帰
-
デシジョン ツリー回帰
- ランダム フォレスト回帰
- LASSO 回帰
- Ridge のリターン
- ElasticNet のリターン
- XGBoost のリターン
- 局所加重線形回帰
- 1. 線形回帰
線形回帰多くの場合、これは人々が機械学習とデータ サイエンスについて学ぶ最初のアルゴリズムです。線形回帰は、入力変数 (X) と単一の出力変数 (y) の間に線形関係があると仮定する線形モデルです。一般的に、次の 2 つの状況があります。
単変量線形回帰は、単一の入力変数 (つまり、単一の特徴変数) と単一の出力変数の間の関係を分析するために使用されるモデリング手法です。関係
多変数線形回帰 (多重線形回帰とも呼ばれます): 複数の入力変数 (複数の特徴変数) と 1 つの出力変数の間の関係をモデル化します。
線形回帰に関するいくつかの重要なポイント:
モデル化が迅速かつ簡単
- これは、モデル化したい関係がそれほど複雑ではなく、大量のデータがない場合に特に役立ちます。
- 非常に直感的な理解と説明。
- 異常値に対して非常に敏感です。
- 2. 多項式回帰
多項式回帰は、非線形分離可能データのモデルを作成する場合に最も一般的な選択肢の 1 つです。これは線形回帰に似ていますが、変数 X と y の間の関係を使用して、データ ポイントに適合する曲線を描く最適な方法を見つけます。
多項式回帰に関するいくつかの重要なポイント:
は非線形の分離可能なデータをモデル化できますが、線形回帰ではそれを実現できません。一般に、これはより柔軟であり、かなり複雑な関係をモデル化できます。
- 特徴変数 (設定する指数) のモデリングを完全に制御します。
#慎重な設計が必要です。最適なインデックスを選択するには、ある程度のデータ知識が必要です。 -
サポート ベクター マシンは分類問題でよく知られています。回帰における SVM の使用は、サポート ベクター回帰 (SVR) と呼ばれます。 Scikit-learn では、このメソッドが SVR() に組み込まれています。
サポート ベクター回帰に関するいくつかの重要なポイント:
これは、性別の外れ値に対して堅牢です。高次元空間で効果的です
優れた一般化機能 (これまで見たことのない新しいデータに正しく適応する機能) を備えています。-
If特徴の数はサンプルの数よりもはるかに大きいため、過学習が起こりやすくなります-
デシジョン ツリーは、次のタイプです。使用される分類と回帰にはノンパラメトリック教師あり学習方法が使用されます。目標は、データの特徴から推測される単純な決定ルールを学習することによって、ターゲット変数の値を予測するモデルを作成することです。ツリーは区分的定数近似として見ることができます。
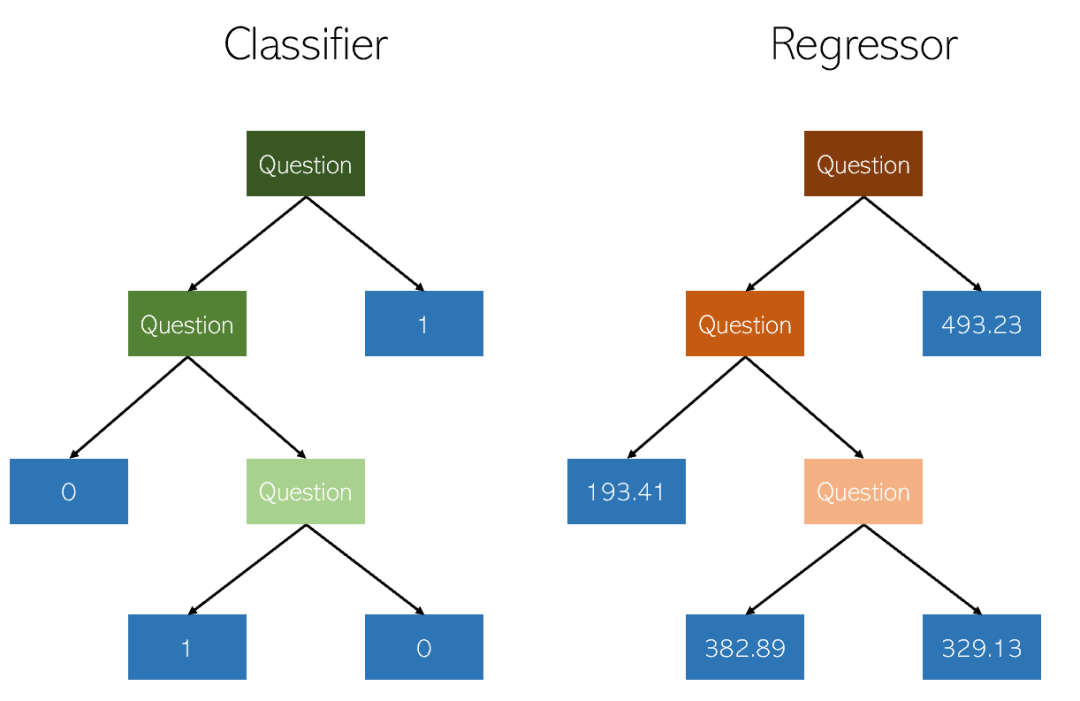
デシジョン ツリーに関するいくつかの重要なポイント:
- 理解しやすく、説明しやすい。樹木を視覚化することができます。
- カテゴリ値と連続値の両方に適用されます
- DT (予測データ) の使用コストは、使用されるデータ ポイントの数に比例します。ツリーを対数的にトレーニングするには
- #決定木の予測は滑らかでも連続的でもありません (上の図に示すように、区分的定数近似です)
5. ランダム フォレスト回帰
ランダム フォレスト回帰は、基本的にデシジョン ツリー回帰と非常によく似ています。これは、データセットのさまざまなサブサンプルに複数のデシジョン ツリーを適合させ、それらを平均して予測精度を向上させ、過剰適合を制御できるメタ推定ツールです。
ランダム フォレスト リグレッサーのパフォーマンスは、回帰問題におけるデシジョン ツリー (一般的に分類問題では優れていますが) は、ツリー構築アルゴリズムに固有の微妙な過適合と過小適合により発生します。 :
デシジョン ツリーの過学習を軽減し、精度を向上させます。
- カテゴリ値と連続値にも機能します。
- 多くのデシジョン ツリーに適合して出力を結合するため、多くのコンピューティング能力とリソースが必要になります。
- 6. LASSO 回帰
LASSO 回帰は、収縮線形回帰の変形です。縮小とは、データ値を平均として中心点まで縮小するプロセスです。このタイプの回帰は、重度の多重共線性 (特徴間の相関が高い) を持つモデルに最適です。
Lasso 回帰に関するいくつかのポイント:
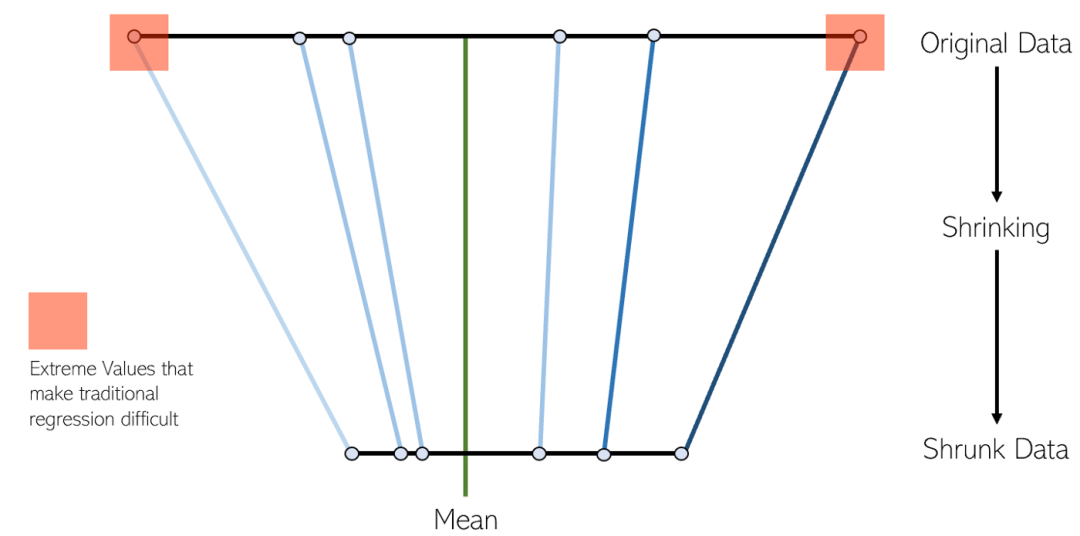
#自動変数を削除し、機能を選択するために最も一般的に使用されます。
- これは、重度の多重共線性 (特徴が互いに高度に相関している) を示すモデルに適しています。
- LASSO 回帰は L1 正則化を利用します
- LASSO 回帰は、一部の特徴のみを選択し、他の特徴を組み合わせると係数が に削減されるため、Ridge よりも優れていると考えられます。ゼロ。
- 7. リッジ回帰
リッジ回帰は、どちらの手法も収縮法を使用するため、LASSO 回帰と非常によく似ています。 Ridge 回帰と LASSO 回帰はどちらも、重度の多重共線性の問題 (つまり、特徴間の高い相関) を伴うモデルに適しています。それらの主な違いは、Ridge が L2 正則化を使用することです。つまり、LASSO 回帰のように係数がゼロになることはありません (しかしゼロに近い)
リッジ回帰に関するいくつかのポイント:
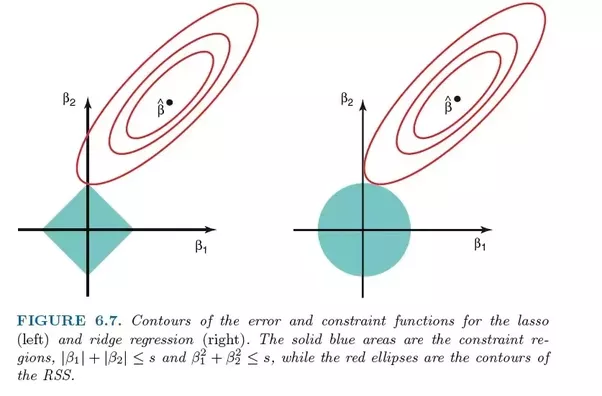
深刻な多重共線性 (特徴が互いに高度に相関している) モデルを示すのに非常に適しています。 。
- リッジ回帰では L2 正則化が使用されます。貢献度が低い特徴の係数はゼロに近くなります。
- L2 正則化の性質により、リッジ回帰は LASSO よりも悪いと考えられています。
- 8. ElasticNet 回帰
ElasticNet は、L1 および L2 正則化を使用してトレーニングされた別の線形回帰モデルです。これは、Lasso 回帰手法と Ridge 回帰手法を組み合わせたものであるため、重度の多重共線性 (特徴が互いに高度に相関している) を示すモデルにも適しています。
Lasso と Ridge を比較検討する場合、実際的な利点は、Elastic-Net が回転時の Ridge の安定性の一部を継承できることです。
9. XGBoost 回帰
XGBoost は、勾配ブースティング アルゴリズムの効率的かつ効果的な実装です。勾配ブースティングは、分類または回帰問題に使用できるアンサンブル機械学習アルゴリズムの一種です。
XGBoost は、もともと Chen Tianqi が 2016 年の論文「XGBoost: A」で開発したオープン ソース ライブラリです。 「ブースティングシステム」で開発された「スケーラブルツリー」。このアルゴリズムは、計算効率が高く効率的になるように設計されています。
關於 XGBoost 的幾點:
- #XGBoost 在稀疏和非結構化資料上表現不佳。
- 該演算法被設計為計算效率和高效,但是對於大型資料集的訓練時間仍然相當長。
- 它對異常值很敏感。
十、局部加權線性迴歸
在局部加權線性迴歸(Local Weights Linear Regression)中,我們也是在進行線性迴歸。然而,與普通線性迴歸不同的是,局部加權線性迴歸是一種局部線性迴歸方法。它透過引入權值(核函數),在進行預測時,只使用與測試點相近的部分樣本來計算迴歸係數。普通線性迴歸則是全域線性迴歸,它使用全部的樣本來計算迴歸係數
優缺點& 適用場景
優點就是透過核函數加權來預防欠擬合,缺點也很明顯K需要調試。當多元線性迴歸過擬合的時候,可以嘗試高斯核局部加權來預防過擬合。
十一、貝葉斯嶺迴歸
使用貝葉斯推論方法求解的線性迴歸模型稱為貝葉斯線性迴歸
#貝葉斯線性迴歸是一種將線性模型的參數視為隨機變數的方法,並透過先驗計算後驗。貝葉斯線性迴歸可以透過數值方法求解,在特定條件下也可以得到解析形式的後驗或相關統計量
貝葉斯線性迴歸具有貝葉斯統計模型的基本性質,可以求解權重係數的機率密度函數,進行線上學習以及基於貝葉斯因子(Bayes factor)的模型假設檢定
優缺點& 適用場景
貝葉斯迴歸的優點是其具有資料自適應能力,可以重複利用資料並防止過度擬合。在估計過程中,可以引入正規化項,例如在貝葉斯線性迴歸中引入L2正則化項,就可以實現貝葉斯嶺迴歸
缺點就是學習過程開銷太大。當特徵數在10個以為,可以嘗試貝葉斯回歸。
以上が機械学習アプリケーションで一般的に使用される回帰アルゴリズムとその特徴の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



