


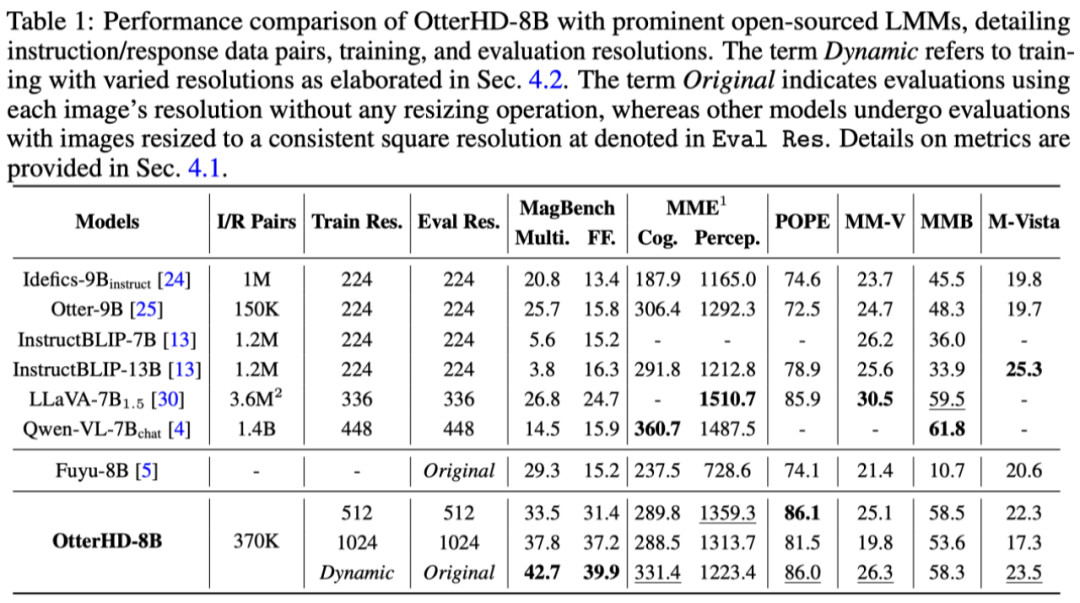
「清明節の川沿い」に登場するラクダの数を知りたいですか? UHD入力に対応したマルチモーダルモデルを見てみましょう。
最近、南洋工科大学の中国チームは、Fuyu-8B に基づいて 80 億パラメータのマルチモーダル大型モデル OtterHD を構築しました。

論文アドレス: https://arxiv.org/abs/2311.04219
制限付きOtterHD-8B は、固定サイズのビジュアル エンコーダの従来のモデルとは異なり、柔軟な入力サイズを処理する機能を備えており、さまざまな推論ニーズの下での汎用性を確保しています。
同時に、チームは新しいベンチマーク テスト MagnifierBench も提案しました。これは、大きなサイズの画像内のオブジェクトの細部と空間的関係を識別する LLM の能力を慎重に評価できます。
#実験結果は、高解像度入力を直接処理する場合、OtterHD-8B のパフォーマンスが同様のモデルよりも大幅に優れていることを示しています
 #GPT4-V がかつて混乱させたリンゴの数を数える問題に直面しましたが、モデルはリンゴが 11 個含まれていると計算することに成功しました
#GPT4-V がかつて混乱させたリンゴの数を数える問題に直面しましたが、モデルはリンゴが 11 個含まれていると計算することに成功しました

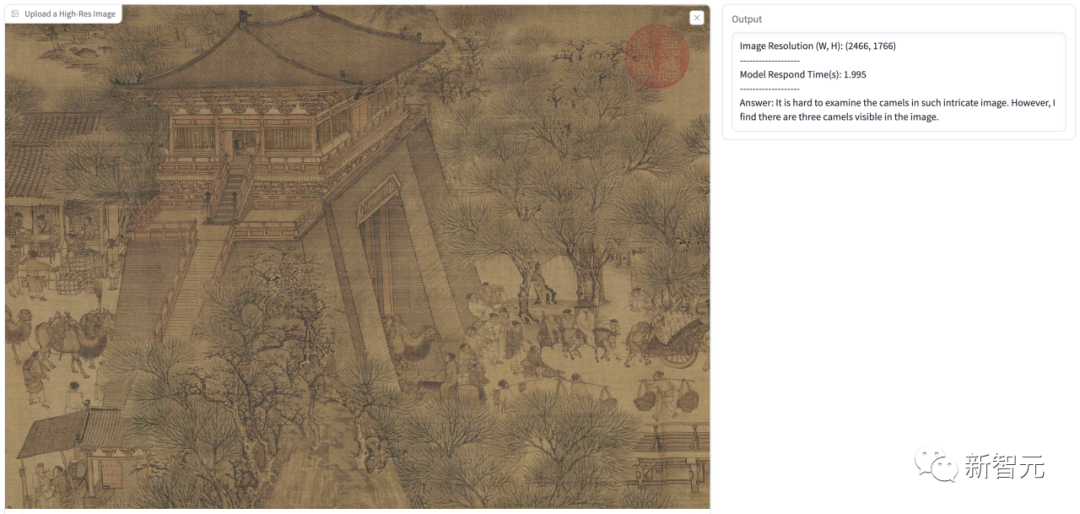
モデルの回答は、写真内のブラック ホールとホワイト ホールの情報を正確に識別し、それがトンネル状の構造であることを識別し、詳細な説明を与えました。
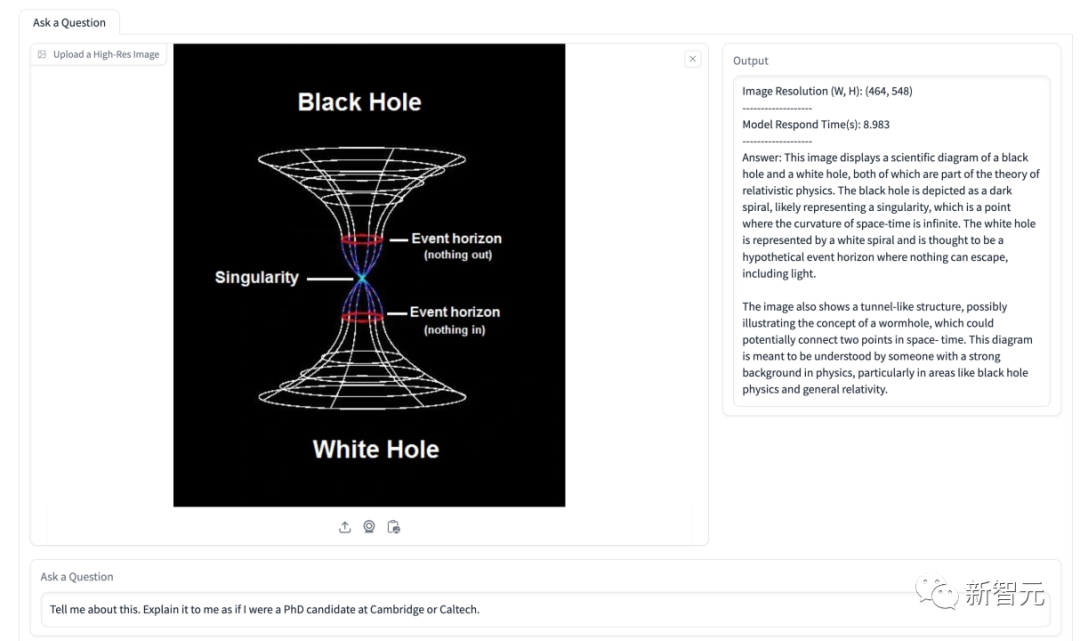
下の図では、モデルはエネルギーシェアに関する状況を説明するよう求められています。このモデルは、図に示されているいくつかのエネルギー タイプを識別し、時間の経過に伴うそれらの割合を正確に示します。
図は、電球を交換するフローチャートに関するものです。 . モデルはフローチャートの意味を正確に理解し、段階的に詳細なガイダンスを提供します。
80億パラメータコマンド微調整OtterHD-8B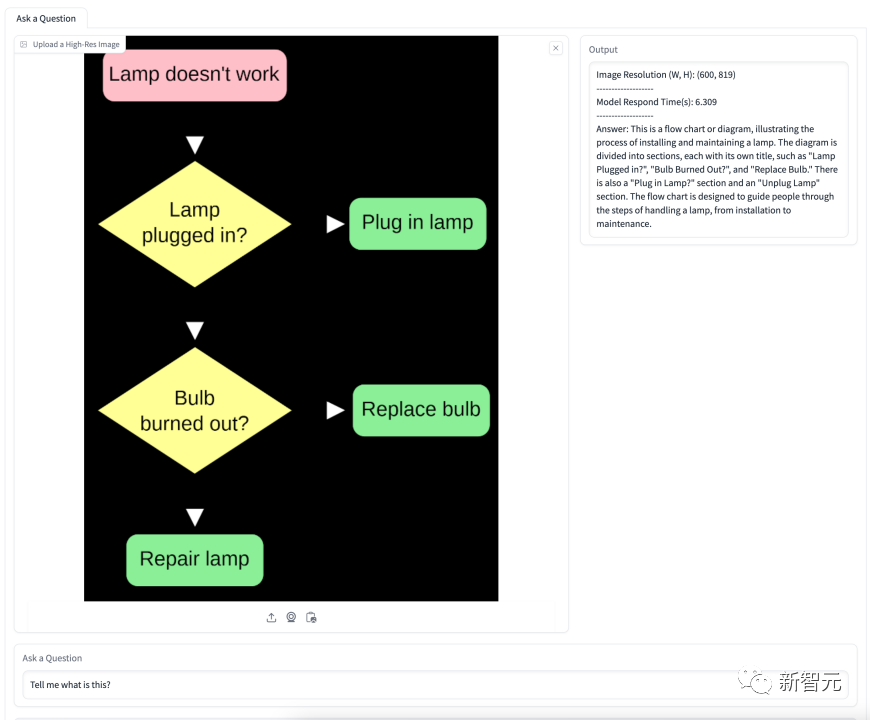
さらに、推論中に、さらに大きな解像度まで拡張できます。 (1440×1440など)。
トレーニングの詳細
予備実験で、チームはふゆが得意とすることを発見しました。ベンチマークは特定の命令に応答する際のパフォーマンスが低く、その結果、MME および MMBench でのモデルのパフォーマンスが非常に弱くなりました。
これらの問題に対処するために、チームは、以下に基づいて命令の微調整を実行しました。 370K 混合データは Fuyu モデルを調整し、LLaVA-1.5 の同様の命令テンプレートを参照してモデルの回答形式を標準化します
トレーニング段階では、すべてのデータセットが命令に編成されます。回答 はい。統合されたデータローダーに要約され、代表的な整合性を確保するために均一にサンプリングされます。
モデリング コードのパフォーマンスを向上させるために、チームは、Fuyu の助けを借りて、FlashAttendant リソース ライブラリにある FlashAttendant-2 とオペレーター フュージョン テクノロジを採用しました。図 2 に示すように、簡素化されたアーキテクチャでは、これらの変更により GPU の使用率とスループットが大幅に向上しました
# 具体的には、チームによって提案された方法は、フル パラメータを使用できます。トレーニングは、8×A100 GPU ではエポックあたり 3 時間で完了しますが、LoRA 微調整後はエポックあたり 1 時間しかかかりません。 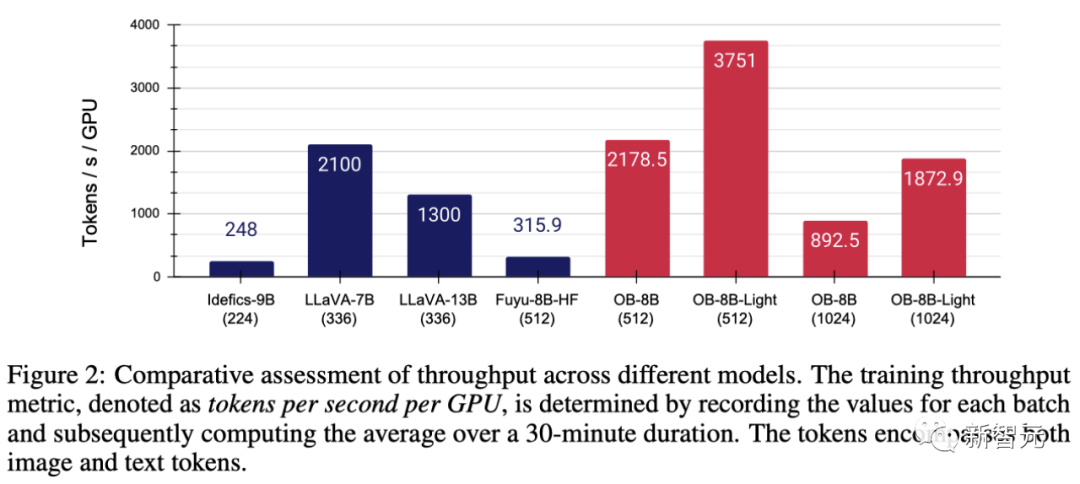
AdamW オプティマイザーを使用してモデルをトレーニングする場合、バッチ サイズは 64、学習率は 1×10^-5、重み減衰は 0.1 に設定されます。
超精密評価ベンチマーク MagnifierBench
Fuyu モデルと OtterHD モデルの登場により、入力画像の解像度を初めてより広い範囲に拡張しました。
この目的を達成するために、チームは、パノプティック シーン グラフ生成 (PVSG) データ セットに基づいて、166 枚の画像と合計 283 セットの質問をカバーする新しいテスト ベンチマーク MagnifierBench を作成しました。
PVSG データセットはビデオ データで構成されており、これには大量の乱雑で複雑なシーン、特に一人称の家事ビデオが含まれています。
アノテーションの段階で、チームはデータセット内のすべての質問と回答のペアを注意深く調べ、大きなオブジェクトに関係するものや、常識的な知識で簡単に答えられるものを除外しました。たとえば、ほとんどのリモコンは黒なので推測しやすいですが、赤や黄色などの色はこのリストには含まれていません。
図 3 に示すように、MagnifierBench によって設計された質問の種類には、認識、数字、色関連の質問などが含まれます。このデータセットの重要な基準は、質問が十分に複雑であるため、アノテーターでも正確に回答するには全画面モードにするか、画像をズームインする必要があることです。
短い回答と比較して、LMM は会話環境で詳細な回答を生成することに優れています。 
#-複数選択の質問
このモデルが直面する問題は、選択できる選択肢が複数あることです。モデルが答えとして文字 (A、B、C など) を選択できるようにするために、チームは質問の前にプロンプトとして特定の選択肢からの文字を挿入しました。この場合、正しい選択肢と完全に一致する回答のみが正しい回答とみなされます
##- 公開質問
ランダムな推測は正しい確率が 25% であるため、複数のオプションを使用するとタスクが簡素化されます。さらに、ユーザーは通常モデルに事前定義されたオプションを提供しないため、これはチャット アシスタントが直面する現実のシナリオを反映していません。この潜在的なバイアスを排除するために、チームはまた、プロンプトの選択肢を設けずに、単純かつ自由形式でモデルに質問をしました。
実験分析研究結果は、多くのモデルが MME や POPE などの確立されたベンチマークで高いスコアを達成しているにもかかわらず、パフォーマンスを発揮できないことを示しています。 MagnifierBench ではパフォーマンスが満足できないことがよくあります。一方、OtterHD-8B は MagnifierBench で良好なパフォーマンスを示しました。
#実験結果は、解像度が増加すると、それに応じて MagnifierBench のパフォーマンスも向上することを示しています。
# #As解像度が上がると、画像とテキストの比率が徐々に増加します。これは、テキスト トークンの平均数が同じままであるためです。この変更により、特に複雑な視覚的な関連付けが必要なタスクでは、LMM 解決の重要性が強調されます。

さらに、固定トレーニング方法と動的トレーニング方法のパフォーマンスの違いは、特に特定の解像度でのオーバーフィッティングの防止において、動的サイズ変更の利点を強調しています。
#動的戦略には、トレーニング中に表示されなかった場合でも、モデルをより高い解像度 (1440) に適応できるという利点もあります
いくつかの比較




同時に、OtterHD-8B は高解像度の画像処理に非常に優れています。優れたパフォーマンス
これは、新しい MagnifierBench ベンチマークで特に顕著になります。このベンチマークの目的は、複雑なシーンの詳細を認識する LMM の能力を評価し、さまざまな解像度に対するより柔軟なサポートの重要性を強調することです。
以上が南洋工科大学の中国チームは、80 億パラメータの OtterHD を通じて、「清明節の川沿い」でラクダを数える体験をお届けします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



