


マルチモーダル対比表現 (MCR) は、さまざまなモダリティからの入力を意味的に調整された共有スペースにエンコードすることを目的としています。
CLIP の大成功により、視覚言語ドメインとしてモデルでは、モーダル コントラスト表現がますます登場し始めており、多くの下流タスクで大幅な改善が達成されていますが、これらの手法は大規模で高品質のペア データに大きく依存しています
この問題を解決するために、浙江大学や他の機関の研究者らは、ペアのデータを必要とせず、トレーニングが非常に効率的なマルチモーダルコントラスト表現学習方法である連結マルチモーダルコントラスト表現 (C-MCR) を提案しました。

# 論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2305.14381
# #C-MCR プロジェクトのホームページのリンク: https://c-mcr.github.io/C-MCR/モデルとコードのアドレス: https://github. com/MCR -PEFT/C-MCR
この方法では、ペアのデータを使用せずに、ハブ モダリティを通じてさまざまな事前トレーニング済みのコントラスト表現を接続し、強力なオーディオビジュアルと 3D 点群を学習します。 -テキスト表現、およびオーディオビジュアル検索、音源位置特定、3D オブジェクト分類などの複数のタスクで SOTA 効果を達成しました。
はじめに
マルチモーダル対比表現 (MCR) は、さまざまなモダリティからのデータを統一された意味論的空間にマッピングすることを目的としています。視覚言語分野における CLIP の大成功により、よりモーダルな組み合わせ間の対照的な表現を学習することが注目の研究テーマとなり、ますます注目を集めています。ただし、既存のマルチモーダル対比表現の一般化能力は、主に多数の高品質のデータ ペアから恩恵を受けます。これにより、大規模で高品質なデータが欠如しているモダリティでの対比表現の開発が大幅に制限されます。たとえば、オーディオ データとビジュアル データのペア間の意味的相関関係は曖昧であることが多く、3D 点群とテキスト間のペア データは希少であり、入手が困難です。
しかし、ペアデータを欠くこれらのモーダルの組み合わせには、同じ中間モダリティを持つ大量の高品質のペアデータが含まれることが多いことが観察されています。たとえば、オーディオビジュアル領域では、オーディオビジュアルデータの品質は信頼できませんが、オーディオ-テキストとテキスト-ビジュアルの間に高品質のペアデータが大量に存在します。
同様に、3D 点群とテキストのペア データの利用可能性は限られていますが、3D 点群と画像および画像とテキストのデータは豊富にあります。これらのハブ モードは、モード間のさらなるリンクを確立できます。
大量のペア データを持つモダリティには、事前にトレーニングされた対比表現があることが多いことを考慮して、この記事では、ハブ モダリティを通じて、異なるモダリティ間の対比表現を直接接続することを試みます。新しい対比表現空間は、ペアのデータを欠いている様相の組み合わせに対して構築されます。
連結マルチモーダル コントラスト表現 (C-MCR) を使用すると、重複モードを通じて多数の既存のマルチモーダル コントラスト表現との接続を構築できるため、より広範囲のモダリティを学習できます。それらの間の。この学習プロセスはペアになったデータを必要とせず、非常に効率的です。
C-MCR には 2 つの重要な利点があります。
# #焦点は柔軟性にあります:
C-MCR の機能は、モーダル学習のための直接のペアリングが欠けている対照的な表現を提供することです。別の観点から見ると、C-MCR は既存の各マルチモーダル コントラスト表現空間をノードとして扱い、重なり合うモードをキー ハブ モードとして扱います。個々の分離されたマルチモーダル コントラスト表現を接続することで、次のことが可能になります。得られたマルチモーダル アライメントの知識を柔軟に拡張し、より広範囲のインターモーダル対比表現を採掘するため
#2. 効率:
# C-MCR は既存の表現空間の接続を構築するだけでよいため、2 つの単純なマッパーを学習するだけで済み、トレーニング パラメータとトレーニング コストは非常に低くなります。この実験では、テキストをハブとして使用し、ビジュアルテキスト (CLIP) とテキストオーディオ (CLAP) を比較して空間的なつながりを表現し、最終的に高品質のビジュアルを取得します。 -音声表現
同様に、空間を表す画像接続テキストビジュアル(CLIP)とビジュアル3D点群(ULIP)を比較することで、3D点群のセットが得られます。 -テキストのコントラスト表現
方法
図 1 (a) C-MCR のアルゴリズム フローを紹介します (テキストを使用して CLIP と CLAP を接続する例を示します) )。テキストのデータ (重複するモダリティ) は、それぞれ CLIP と CLAP のテキスト エンコーダーによってテキスト特徴にエンコードされます。 #同時に、それぞれ CLIP 空間と CLAP 空間にエンコードされ、画像メモリと音声メモリを形成する、対になっていない大量のシングルモーダル データも存在します 機能のセマンティック強化とは、セマンティック表現機能を強化するために機能を改善および最適化するプロセスを指します。これらの特徴を適切に調整することで、表現したい意味をより正確に反映することができ、言語表現の効果が向上します。機能意味強化テクノロジには、自然言語処理の分野で重要な応用価値があり、機械によるテキスト情報の理解と処理を支援し、意味理解と意味生成における機械の能力を向上させることができます。 # 空間接続の堅牢性と包括性を強化するために、表現の意味情報を改善することから始めることができます。この点に関して、まず意味的一貫性と意味的整合性の 2 つの観点から議論します ##CLIP と CLAP は、それぞれ信頼性の高い位置合わせされた画像とテキスト、およびテキストと音声の表現を学習しました。 CLIP と CLAP に固有のモーダル アライメントを利用して、i 番目のテキストと意味的に一貫した画像と音声の特徴を生成します。これにより、表現空間のコントラストをより適切に定量化できます。モダリティ ギャップと重複しないモダリティ間の相関関係をより直接的にマイニング:
モーダル内セマンティック整合性 各表現の意味論的な完全性を高めるために、ゼロ平均ガウス ノイズを表現に追加し、単位超球に繰り込み直すことを提案します。 図 1 (c) に示すように、対比表現空間では、各表現が単位超球上の点を表現していることがわかります。ガウス ノイズを追加して繰り込みを行うと、単位球上の円を表現できるようになります。 2 つの特徴間の空間的距離が近いほど、それらの意味的な類似性は高くなります。したがって、サークル内のフィーチャは同様のセマンティクスを持ち、サークルはセマンティクスをより完全に表現できます
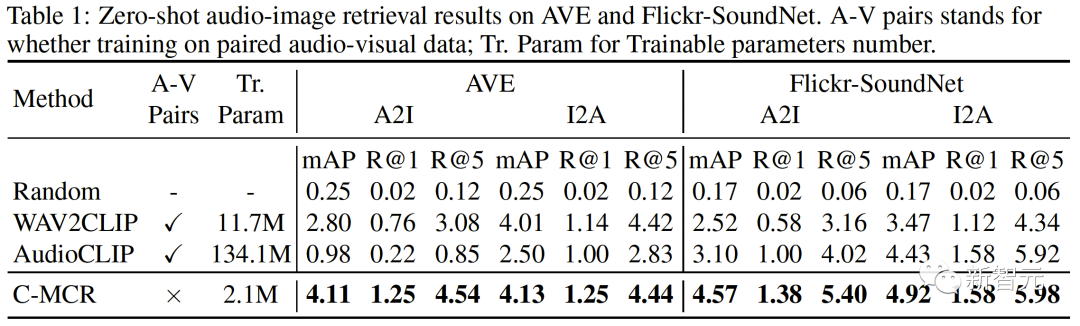
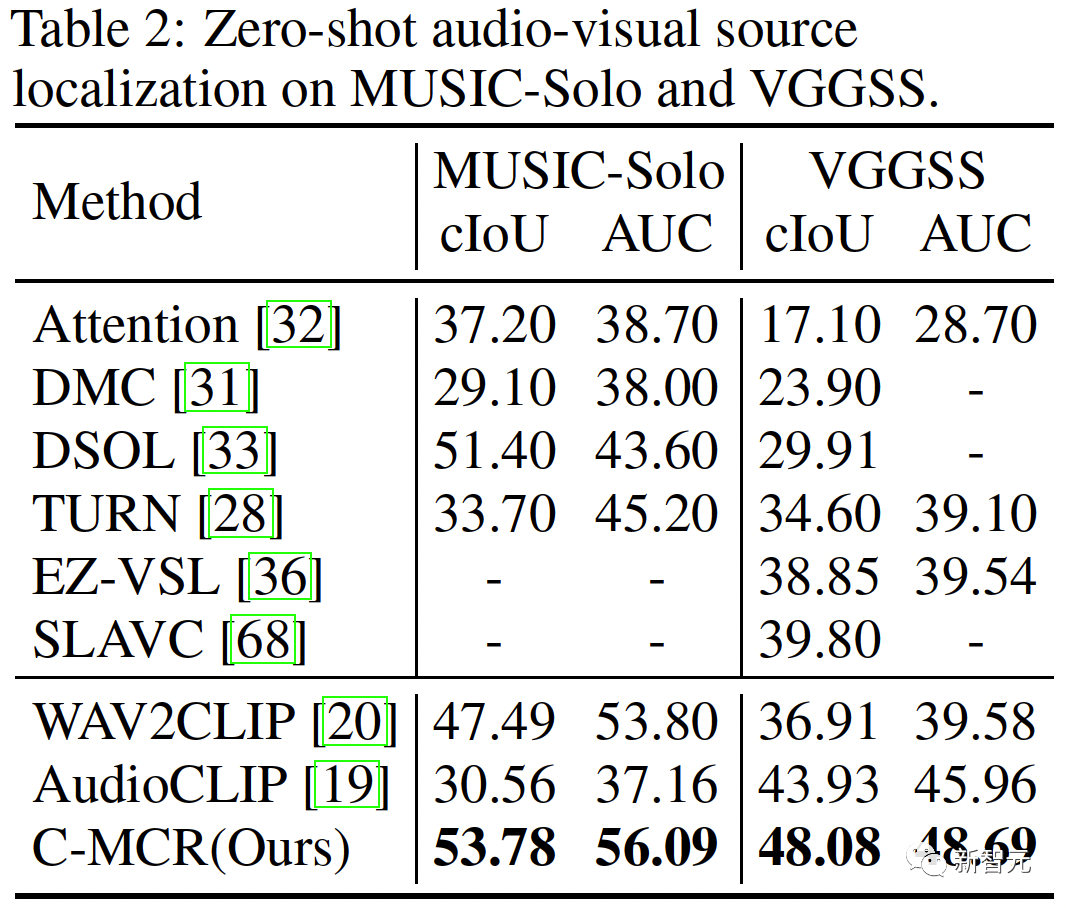
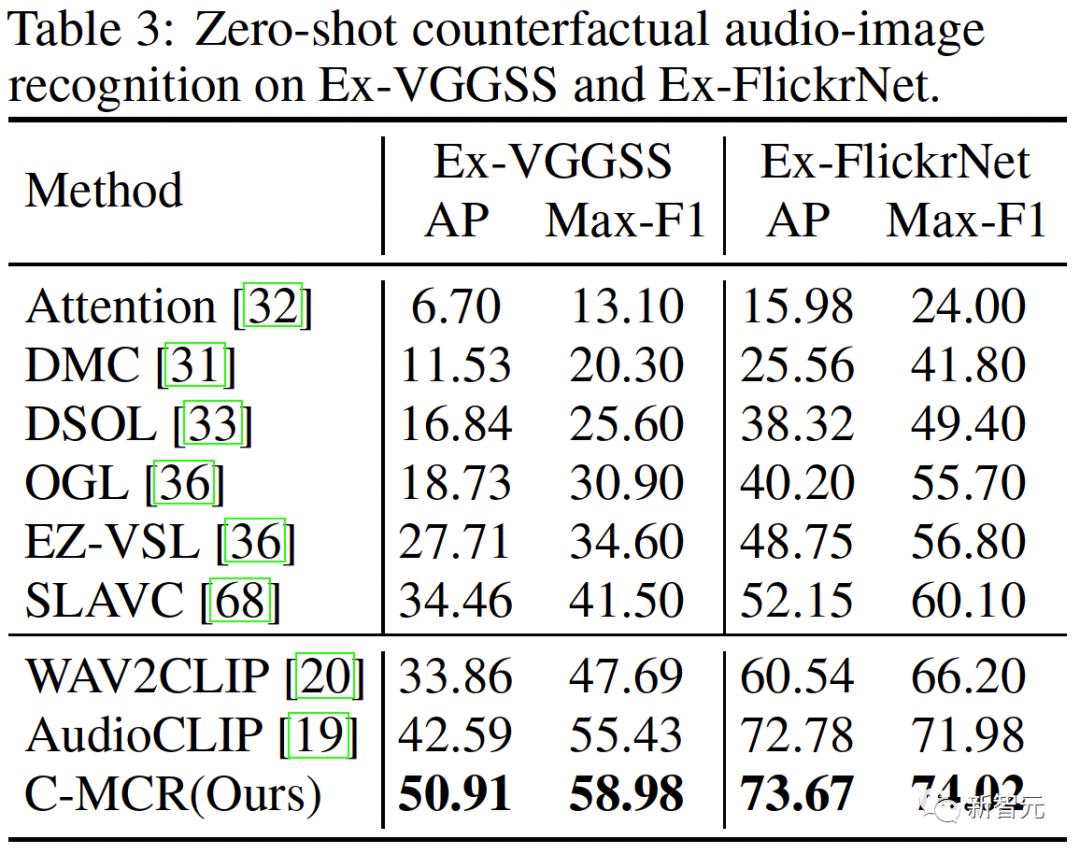
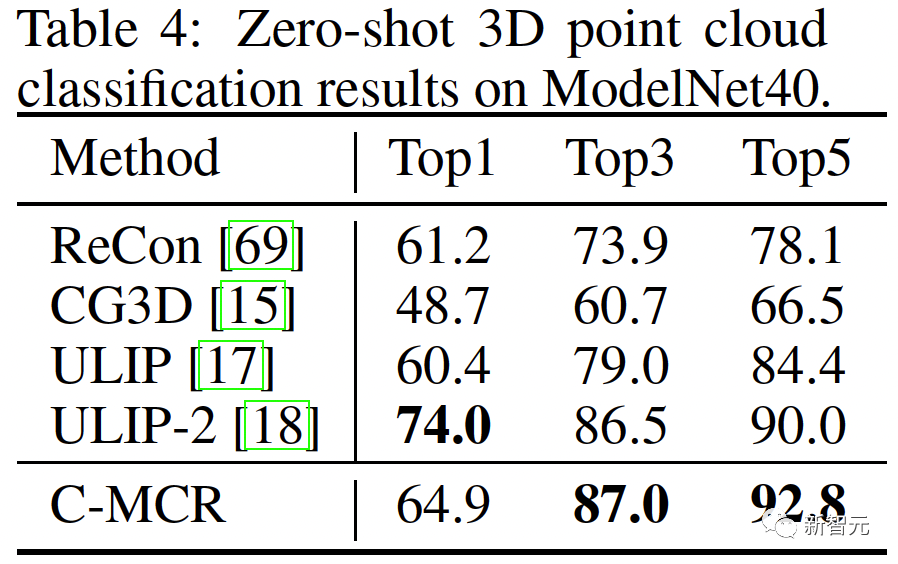
##新しい空間では、異なる空間からの意味的に類似した表現が互いに近いことを保証する必要があります。 同じテキストから派生した ( ( 2 つの対照的な表現空間をより包括的に接続するために、( ##3. MCR 内の調整 空間間のつながりに加えて、コントラスト表現空間内にもモダリティギャップ現象が存在します。つまり、対比表現空間では、異なるモダリティの表現は意味的には整列していますが、それらは完全に異なる部分空間に分布しています。これは、( この問題を解決するために、各対比表現空間の異なるモーダル表現を再調整することを提案します。具体的には、コントラスト損失関数の負例排除構造を除去し、モダリティギャップを低減するための損失関数を導出する。典型的な対比損失関数は次のように表すことができます: #負のペアの除外項を削除した後、最終的な式は次のように簡略化できます: 実験的に、テキストを使用してオーディオテキスト空間 (CLAP) とテキストビジュアル空間 (CLIP) を接続することによって得られました。画像接続 3D 点群 - 画像空間 (ULIP) および画像 - テキスト空間 (CLIP) を使用して 3D 点群 - テキスト表現を取得するオーディオビジュアル表現。 AVE および Flickr-SoundNet でのゼロサンプル オーディオ イメージの取得の結果は次のとおりです: MUSIC-Solo と VGGSS でのゼロサンプル音源定位結果は以下のとおりです。 # #Ex-VGGSS および Ex-FlickrNet でのゼロショットの反事実音声画像認識の結果は次のとおりです。 ModelNet40 でのゼロ-ショット 3D 点群の分類結果は次のとおりです: 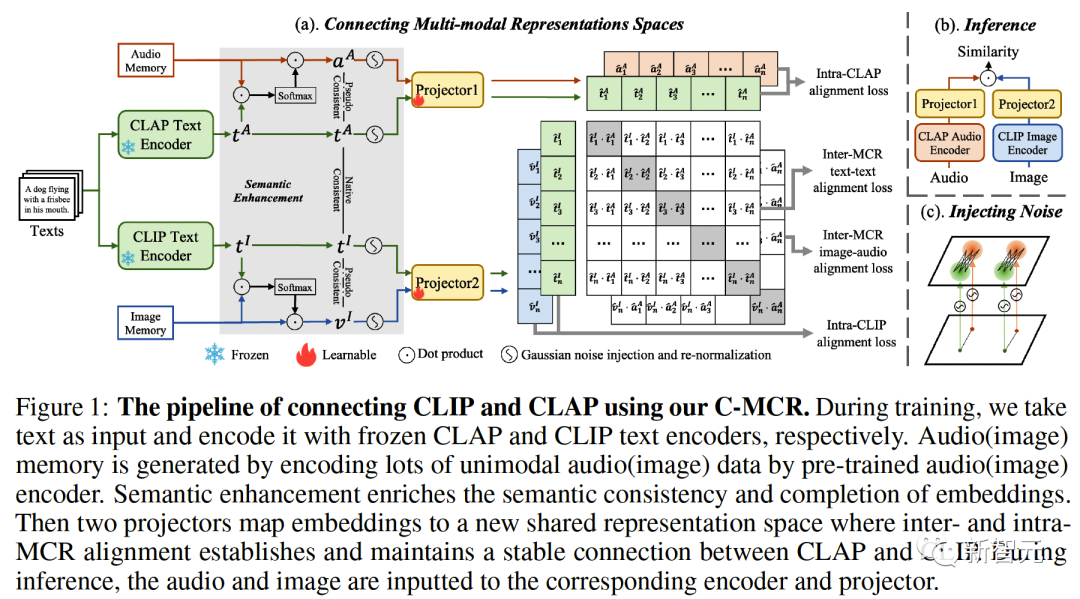
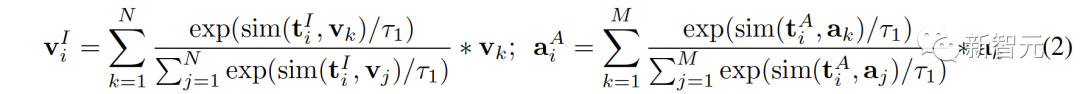 表現空間が異なれば、データの意味表現の傾向も異なるため、異なる空間にある同じテキストでも必然的に意味の逸脱や損失が生じます。この意味論的な偏りは、表現空間を接続するときに蓄積され、増幅されます。
表現空間が異なれば、データの意味表現の傾向も異なるため、異なる空間にある同じテキストでも必然的に意味の逸脱や損失が生じます。この意味論的な偏りは、表現空間を接続するときに蓄積され、増幅されます。 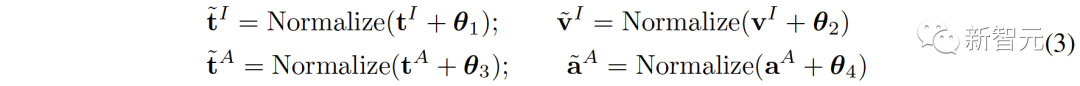 #2. MCR 間の調整
#2. MCR 間の調整 ,
, ) は当然意味的に一貫しており、実際のタグのペアと見なすことができますが、( (,
) は当然意味的に一貫しており、実際のタグのペアと見なすことができますが、( (, ) の
) の  ,
, ) は擬似ラベル ペアと見なすことができます。
) は擬似ラベル ペアと見なすことができます。  ,
, ) 間のセマンティクスは非常に一貫性がありますが、そこから学習された接続は、オーディオ - 間接的に言えば。 (
) 間のセマンティクスは非常に一貫性がありますが、そこから学習された接続は、オーディオ - 間接的に言えば。 ( ,
, ) ペアの意味上の一貫性は信頼性が低くなりますが、オーディオビジュアル表現にとってはより直接的な利点があります。
) ペアの意味上の一貫性は信頼性が低くなりますが、オーディオビジュアル表現にとってはより直接的な利点があります。  ,
, ) と (
) と ( ) を同時に整列させます。 ,
) を同時に整列させます。 , ):
):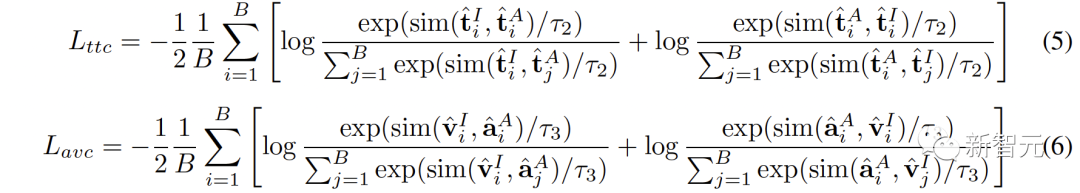 ,) から学習したより安定した接続がオーディオビジュアルにうまく継承されない可能性があることを意味します。
,) から学習したより安定した接続がオーディオビジュアルにうまく継承されない可能性があることを意味します。 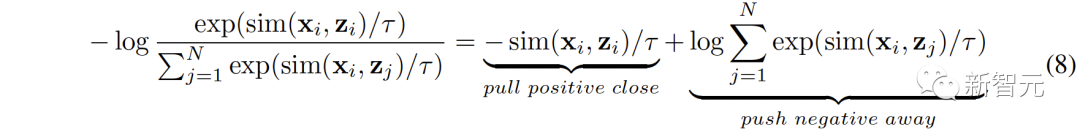
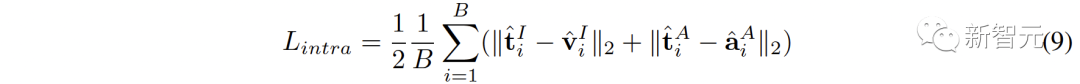
以上が「データを合わせなくても」学習できる!浙江大学らはマルチモーダルコントラスト表現C-MCRの接続を提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



