


現在、多くの有名モデルが数学が得意だと主張しています。本当の才能を持っているのは誰でしょうか?連続テスト問題で「カンニング」したのは誰ですか?
今年、誰かがハンガリー国立数学最終試験のために発表されたばかりの問題について包括的なテストを実施しました
多くのモデルが突然成功しました"元の形状になりました。」 。
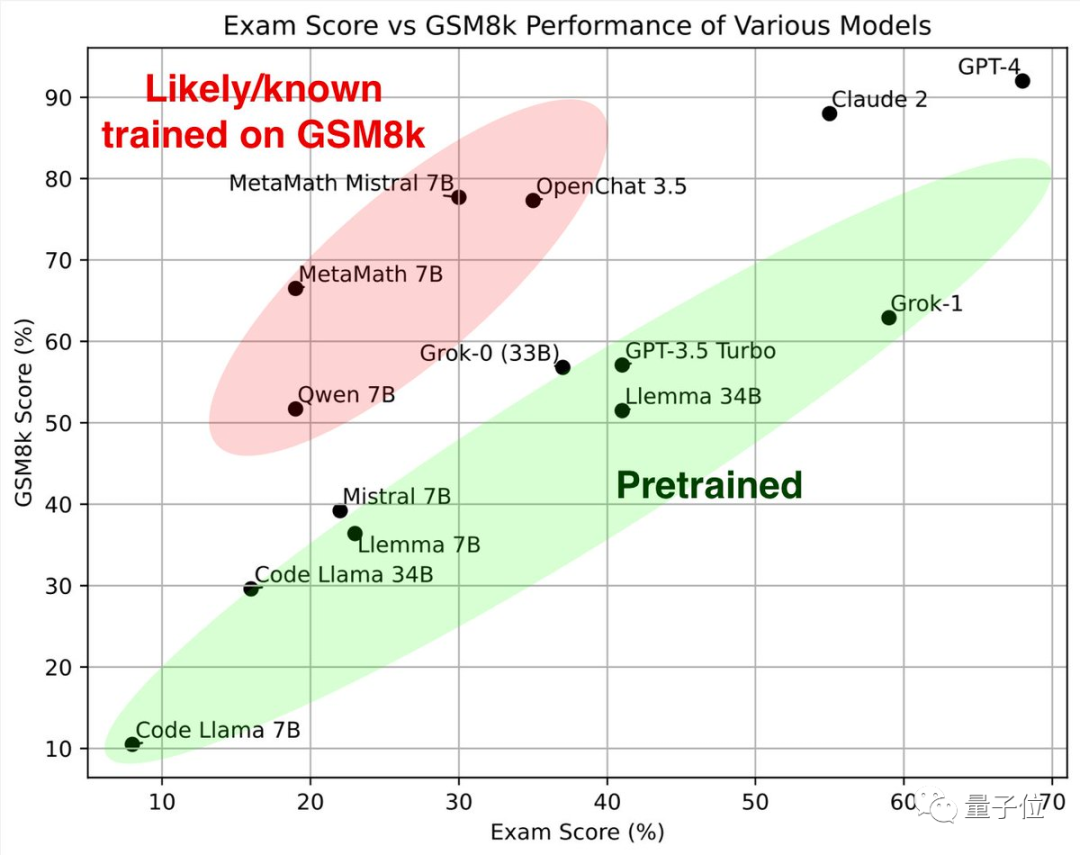
最初に緑色の部分を見てください。これらの大規模モデルは、古典的な数学テスト セット GSM8k と新しい論文で同様の結果を示しています。 一緒にそれらは参照標準 を形成します。
##赤い部分# を見ると、GSM8K での結果は、同じパラメータ スケールを持つ大型モデルの結果よりも大幅に高くなります。到着次第 新品紙のスコアは大幅に下がり、同サイズの大型モデルとほぼ同等でした。 研究者らは、彼らを 「GSM8k でトレーニングを受けた疑いがある、または既知である」
として分類しました。このテストを見た後、これまで見たことのない質問を評価し始めるべきだと言う人もいます。
この種のテストは、と考える人もいます。誰もが実際に大規模モデルを使用した経験が現在唯一信頼できる評価方法です

Musk Grok は GPT-4 に次いで 2 番目であり、オープンソースの Llemma は優れた結果を示しています
テスター
大きなモデルにハンガリーの国立高校数学の最終試験を受けさせてください。このトリックは
Musk の xAI
xAI の Grok 大規模モデルがネットワーク データ内のテスト問題を誤って認識したという問題を排除するために、いくつかの一般的なテスト セットに加えて、このテストも実施されました 今年のこの試験テストは 5 月末に完了したばかりで、現在の大型モデルでは基本的にこの一連のテスト問題を見る機会がありませんでした。 #xAI は、比較のために GPT-3.5、GPT-4、および Claude 2 がリリースされたときにその結果も発表しました。
この一連のデータに基づいて、Paster はさらなるテストを実施しました。テスト オブジェクトは、強力な数学的機能を備えた複数のオープン ソース モデルでした。およびテスト問題は、各モデルのテスト スクリプトと回答結果は、誰もが他のモデルを確認してさらにテストできるように、Huggingface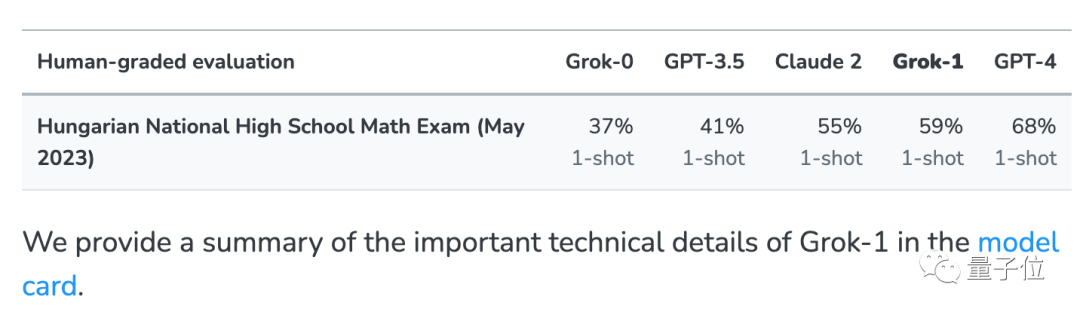 でオープンソース化されています。
でオープンソース化されています。
結果は、GPT-4 と Claude-2 が最初の段階を形成し、GSM8k と新しい論文で非常に高いスコアを示していることを示しています。 これは、GPT-4 と Claude 2 のトレーニング データに GSM8k のリークされた質問がないという意味ではありませんが、少なくともそれらは優れた一般化機能を備えており、新しい質問を正しく解決できるため、リークされた質問は存在しません。お手入れ。
次に、Musk xAI の Grok-0 (33B) 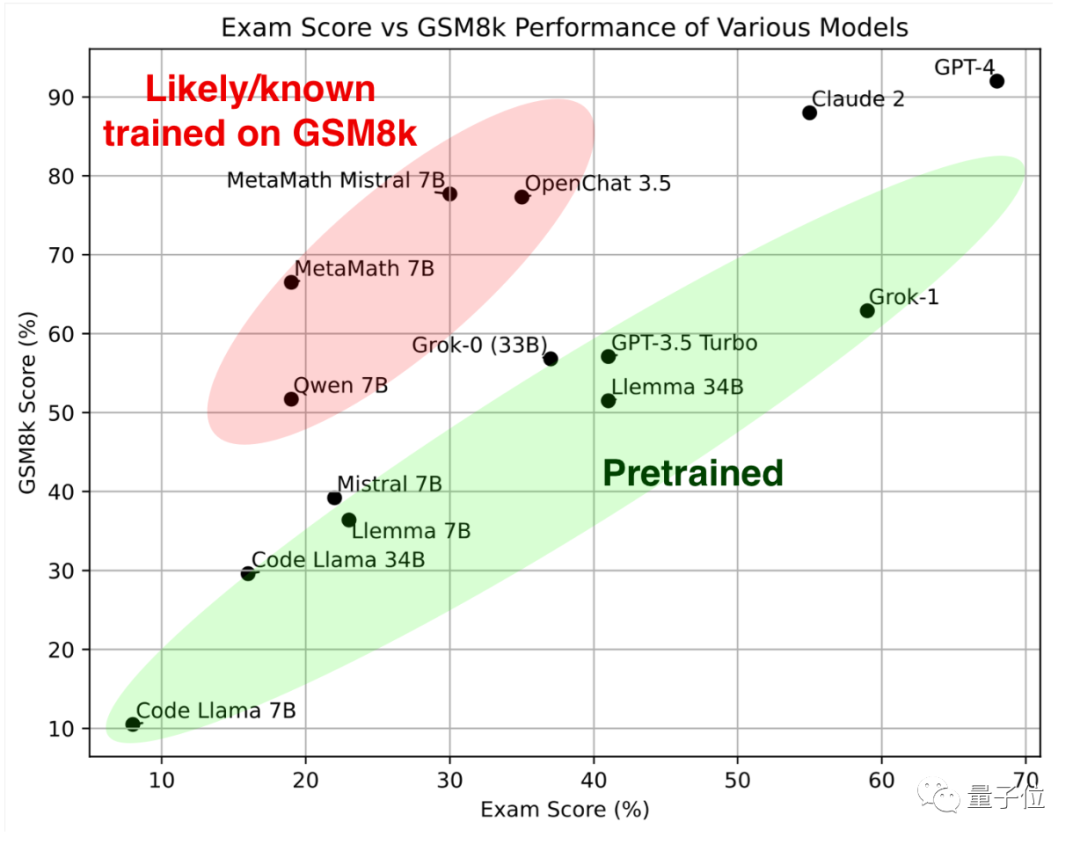 と Grok-1
と Grok-1
が良好なパフォーマンスを示しました。
Grok-1 は「不正行為をしないグループ」の中で最も高いスコアを持っており、彼の新しい論文のスコアは Claude 2 よりもさらに高くなっています。 GSM8k 上の Grok-0 のパフォーマンスは GPT3.5-Turbo に近く、新しい論文ではわずかに劣ります。
上記のクローズド モデルを除き、テスト内の他のモデルはすべてオープン ソースです。Code Llama シリーズ
は Meta の独自バージョンです。 Llama 2 の基本的には、自然言語に基づいてコードを生成することに重点を置いて微調整されています。
Code Llama に基づいて、多くの大学や研究機関が共同で Llemma シリーズ を立ち上げ、EleutherAI によってオープンソース化されました。 チームは、科学論文、数学を含むネットワーク データ、および数学的コードから Proof-Pile-2 データセットを収集しました。トレーニング後、Llemma はツールを使用して、それ以上の微調整を行わずに形式的な定理証明を行うことができます。
 新しい論文によると、Llemma 34B のパフォーマンスは GPT-3.5 Turbo レベルに近いです
新しい論文によると、Llemma 34B のパフォーマンスは GPT-3.5 Turbo レベルに近いです
Mistral シリーズ は、フランスの AI ユニコーンである Mistral AI によってトレーニングされています。Apache2.0 のオープンソース契約は Llama よりも緩和されており、羊 Tuo ファミリーに次いで、オープンソース コミュニティで最も人気のある基本モデル。 ##OpenChat 3.5 および MetaMath Mistral はすべてミストラル エコシステムに基づいて微調整されています。 および MAmmoTH Code は、Code Llama エコシステムに基づいています。 オープンソースの大規模モデルを実際のビジネスに採用することを選択する人は、このグループを避けるように注意する必要があります。なぜなら、これらのモデルはランキングを上げるためだけに優れたパフォーマンスを発揮する可能性が高いためですが、実際の機能はそれほど強力ではない可能性があります。同じスケールの他のモデル 多くのネチズンは、この実験がまさにモデルの実際の状況を理解するために必要なものであると信じて、この実験に対してパスター氏に感謝の意を表しました。 懸念を表明した人もいます: この日から、大規模モデルをトレーニングする全員が、過去のハンガリーの数学試験問題を追加することになります。 同時に、解決策は、独自のテストを行う # を設立することであると考えています。 

専門の大規模モデル評価会社  #テスト ベンチマークを確立することです。
#テスト ベンチマークを確立することです。
以上が大規模不正モデルを見分ける1つのトリック、医師の弟のオープンソースAI数学「デーモンミラー」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



