


Transformer は、自然言語処理、コンピューター ビジョン、時系列予測などの分野におけるさまざまな学習タスクで成功を収めています。成功にもかかわらず、これらのモデルは依然としてスケーラビリティの厳しい制限に直面しています。その理由は、アテンション層を正確に計算すると、(シーケンス長で) 2 次の実行時間とメモリの複雑さが生じるためです。これは、Transformer モデルをより長いコンテキスト長に拡張する際に根本的な課題をもたらします
業界は、二次時間的注意層の問題を解決するためにさまざまな方法を模索してきましたが、その中で注目すべき方向性の 1 つは、次の近似を行うことです。注目層の中間行列。これを実現する方法には、スパース行列、低ランク行列、またはその両方の組み合わせによる近似が含まれます。
ただし、これらの方法では、アテンション出力行列の近似に対するエンドツーエンドの保証は提供されません。これらの方法は、注意の個々の構成要素をより速く近似することを目的としていますが、完全な内積注意のエンドツーエンドの近似を提供するものはありません。これらのメソッドは、最新の Transformer アーキテクチャの重要な部分である因果マスクの使用もサポートしていません。最近の理論的限界は、一般に二次時間以下でアテンション行列の区分的近似を実行することは不可能であることを示唆しています
しかし、KDEFormer と呼ばれる最近の研究では、 を提供できることが示されています。注意行列の項が制限されているという仮定の下で、二次時間での証明可能な近似。理論的には、KDEFormer の実行時間はほぼ確率です。ただし、現在の KDE アルゴリズムには実用的な効率が欠けており、理論的にも KDEFormer の実行時間と理論的に実現可能な O(n) 時間のアルゴリズムとの間にはギャップがあります。この記事の中で、著者は、同じ制限されたエントリの仮定の下で、ほぼ線形の時間 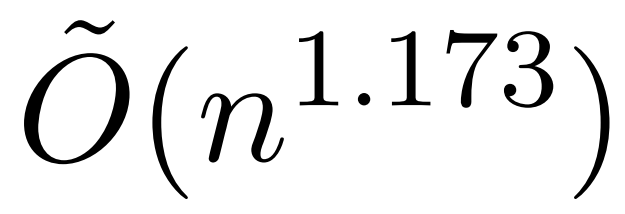 アルゴリズムが可能であることを証明しています。ただし、彼らのアルゴリズムには、ソフトマックスを近似するために多項式手法を使用することも含まれており、これは非現実的である可能性があります。
アルゴリズムが可能であることを証明しています。ただし、彼らのアルゴリズムには、ソフトマックスを近似するために多項式手法を使用することも含まれており、これは非現実的である可能性があります。 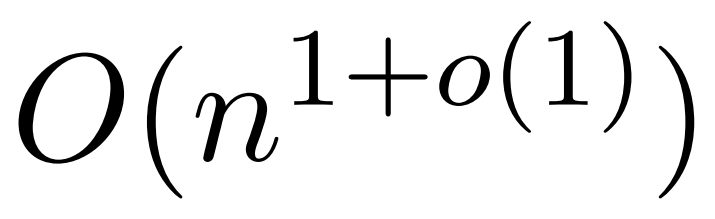 この記事では、イェール大学、Google Research、その他の機関の研究者が、実用的かつ効率的で、最適な近似結果を達成できる、両方の長所を備えたアルゴリズムを提供します。リニアタイムを確保します。さらに、この方法は、以前の研究では不可能であった因果マスキングをサポートします。
この記事では、イェール大学、Google Research、その他の機関の研究者が、実用的かつ効率的で、最適な近似結果を達成できる、両方の長所を備えたアルゴリズムを提供します。リニアタイムを確保します。さらに、この方法は、以前の研究では不可能であった因果マスキングをサポートします。
# 論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2310.05869
# #この記事では、大規模な言語モデルで長いコンテキストを使用することによって引き起こされる計算上の課題に対処するために、「HyperAttendant」と呼ばれる近似アテンション メカニズムを提案します。最近の研究では、注意行列のエントリが制限されているか、行列の安定順位が低い場合を除き、最悪の場合、二次時間が必要であることが示されています。
内容を次のように書き換えます。研究者らは、測定する 2 つのパラメータを導入しました: (1) 最大列ノルム正規化アテンション行列、(2) 大きなエントリを削除した後の非正規化アテンション行列における行ノルムの割合。これらのきめ細かいパラメータを使用して、問題の難易度を反映します。上記のパラメータが小さい限り、行列に無制限のエントリや大きな安定したランクがある場合でも、線形時間サンプリング アルゴリズムを実装できます。他の高速な低レベル実装、特に FlashAttendant を簡単に統合できます。経験的には、スーパー アテンションは、LSH アルゴリズムを使用して大きなエントリを識別する場合に既存の方法よりも優れたパフォーマンスを発揮し、FlashAttendant などの最先端のソリューションと比較して大幅な速度向上を実現します。研究者らは、さまざまな長さのさまざまなコンテキスト データセットで Hypertention のパフォーマンスを検証しました
#たとえば、Hypertention により、ChatGLM2 の推論時間が 32,000 のコンテキスト長で 50% 高速になり、困惑度が 5.6 から増加しました。 6.3まで。 HyperAttendant は、より大きなコンテキスト長 (例: 131k) と因果マスクを備えた単一のアテンション レイヤーで 5 倍高速です。
方法の概要
内積アテンションには、Q (クエリ)、K (キー)、V (値) の 3 つの入力行列の処理が含まれます。はすべてサイズ nxd です。ここで、n は入力シーケンス内のトークンの数、d は基礎となる表現の次元です。このプロセスの出力は次のとおりです:
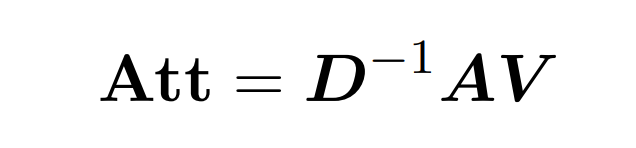
ここでは、行列 A := exp (QK^T) を QK^T の要素インデックスとして定義します。 D は、A の行の合計から導出される n×n の対角行列です (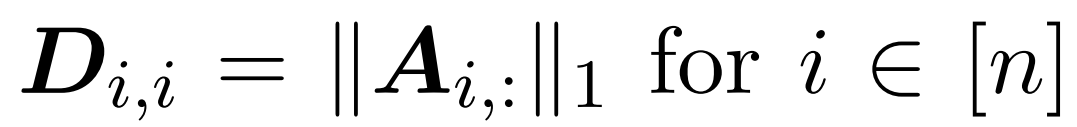 )。この場合、行列 A は「注目行列」と呼ばれ、(D^-1) A は「ソフトマックス行列」と呼ばれます。アテンション行列 A を直接計算するには Θ(n²d) の演算が必要ですが、それを保存するには Θ(n²) のメモリが消費されることに注意してください。したがって、Att を直接計算するには、Ω(n²d) のランタイムと Ω(n²) のメモリが必要です。
)。この場合、行列 A は「注目行列」と呼ばれ、(D^-1) A は「ソフトマックス行列」と呼ばれます。アテンション行列 A を直接計算するには Θ(n²d) の演算が必要ですが、それを保存するには Θ(n²) のメモリが消費されることに注意してください。したがって、Att を直接計算するには、Ω(n²d) のランタイムと Ω(n²) のメモリが必要です。
研究者の目標は、スペクトル特性を維持しながら出力行列 Att を効率的に近似することです。彼らの戦略は、対角スケーリング行列 D のほぼ線形の時間効率の高い推定器を設計することで構成されています。さらに、サブサンプリングによってソフトマックス行列 D^-1A の行列積を迅速に近似します。より具体的には、彼らの目標は、有限数の行 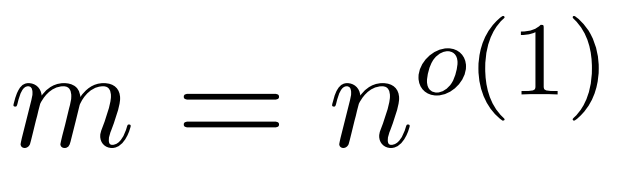 と対角行列
と対角行列 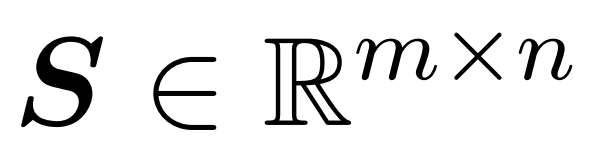 を含むサンプリング行列
を含むサンプリング行列 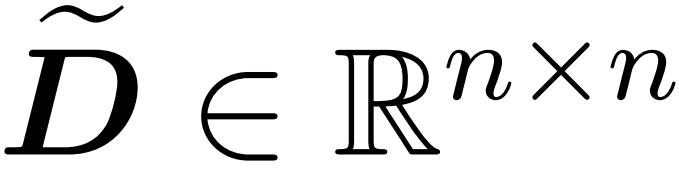 を見つけることです。エラーの演算子仕様の次の制約を満たす:
を見つけることです。エラーの演算子仕様の次の制約を満たす:
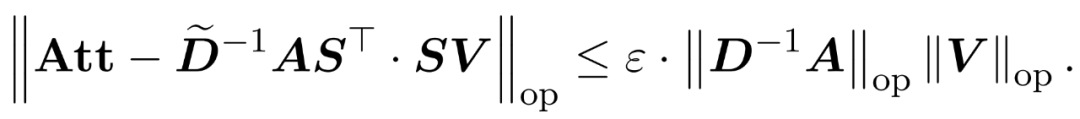
研究者らは、V の行仕様に基づいてサンプリング行列 S を定義することによって、それを示しました。式 (1) のアテンション近似問題の行列乗算部分を効率的に解くことができます。より困難な問題は、対角行列 D の信頼できる近似をどのように取得するかということです。最近の結果では、Zandieh は高速 KDE ソルバーを効果的に活用して、D の高品質な近似値を取得しました。私たちは KDEformer プログラムを簡略化し、カーネル密度ベースの重要度サンプリングを必要とせずに、均一なサンプリングで必要なスペクトル保証を達成するのに十分であることを実証しました。この大幅な単純化により、実用的で証明可能な線形時間アルゴリズムを開発できるようになりました。
以前の研究とは異なり、私たちの方法は制限されたエントリや制限された安定したランクを必要としません。さらに、注目行列のエントリまたは安定したランクが大きい場合でも、時間計算量を分析するために導入されるきめの細かいパラメータは依然として小さい可能性があります。
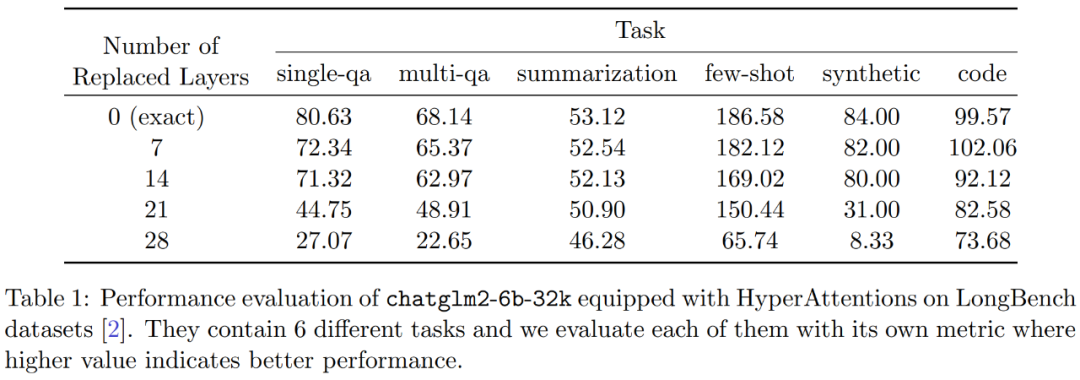
その結果、HyperAttendant は大幅に高速になり、シーケンス長 n= 131k での前方伝播と後方伝播が 50 倍以上高速になります。この方法は、因果マスクを処理する場合でも 5 倍の大幅な高速化を達成します。さらに、このメソッドを事前トレーニング済み LLM (chatqlm2-6b-32k など) に適用し、ロング コンテキスト ベンチマーク データセット LongBench で評価すると、微調整を必要としなくても、元のモデルに近いパフォーマンス レベルを維持します。 。研究者らはまた、特定のタスクを評価し、要約タスクとコード補完タスクが、問題解決タスクよりもおおよその注意層に大きな影響を与えることを発見しました。
#Att を近似するときにスペクトル保証を得るために、この記事の最初のステップは 1 ± ε 近似を実行することです。続いて、A と V の行列積は、V の正方行 ℓ₂ ノルムに従ってサンプリング (D^-1) することによって近似されます。
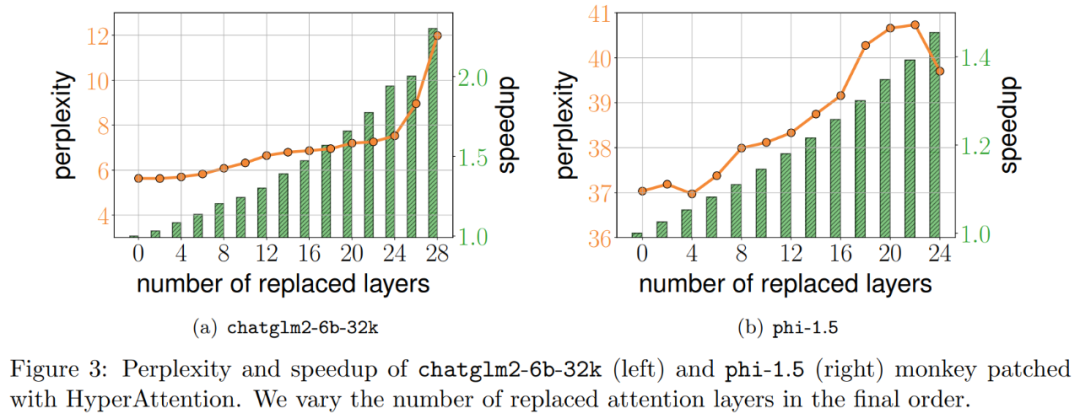
D を近似するプロセスは 2 つのステップで構成されます。まず、定義 1 に示すように、ハミングのソート LSH に基づいたアルゴリズムを使用して、アテンション マトリックスの主要エントリを識別します。 2 番目のステップは、K の小さなサブセットをランダムに選択することです。この論文では、行列 A と D に関する特定の穏やかな仮定の下で、この単純な方法で推定された行列のスペクトル境界を確立できることを示します。研究者の目標は、次の条件を満たすのに十分な精度の近似行列 D を見つけることです。 この記事の前提は、ソフトマックス行列の列ノルムが比較的均一な分布を示すということです。より正確には、研究者は、任意の i ∈ [n] t に対して、 アルゴリズムの最初のステップは、ハミング ソート LSH (sortLSH) を使用してキーとクエリを均一サイズのバケットにハッシュすることにより、アテンション マトリックス A 内の大きなエントリを識別することです。アルゴリズム 1 はこのプロセスの詳細を示し、図 1 はそれを視覚的に示しています。 アルゴリズム 1 の機能は、アテンション行列の主要なエントリを分離するために使用されるスパース マスクを返すことです。このマスクを取得した後、研究者は、式 (2) のスペクトル保証を満たすアルゴリズム 2 の行列 D の近似値を計算できます。このアルゴリズムは、マスクに対応するアテンション値を、アテンション マトリックス内のランダムに選択された列のセットと組み合わせることによって実装されます。この論文のアルゴリズムは広く適用でき、事前定義されたマスクを使用してアテンション マトリックスの主要エントリの位置を指定することで効率的に使用できます。このアルゴリズムの主な保証は、定理 1 ## A に示されています。値行列 V を使用して、近似対角 図 2 に示す 2 つの対角ブロック と 実験と結果 #元の意味を変更しないようにするには、内容を中国語に書き直す必要がありますが、元の文を表示する必要はありません Researcher Hypertention は、最初に 2 つの事前トレーニングされた LLM で評価され、実際のアプリケーションで広く使用されている異なるアーキテクチャを持つ 2 つのモデル (chatglm2-6b-32k と phi-1.5) が選択されます。 操作では、最後の ℓ アテンション レイヤーを HyperAttendant に置き換えることでパッチを適用します。ここで、 ℓ の数は 0 から各 LLM のすべてのアテンション レイヤーの合計数まで変化します。どちらのモデルでも注意には因果マスクが必要であり、入力シーケンスの長さ n が 4,096 未満になるまでアルゴリズム 4 が再帰的に適用されることに注意してください。すべてのシーケンスの長さについて、バケット サイズ b とサンプリングされた列の数 m を 256 に設定します。彼らは、このようなモンキーパッチを適用したモデルのパフォーマンスを、複雑さと加速度の観点から評価しました。 同時に、研究者らは、長いコンテキストのベンチマーク データ セットのコレクションである LongBench を使用しました。これには、単一/複数文書の質問回答、要約、小規模サンプルという 6 つの異なるタスクが含まれています。学習と合成 タスクとコードの補完。彼らは、コーディング シーケンスの長さが 32,768 を超えるデータセットのサブセットを選択し、長さが 32,768 を超えた場合はそれを枝刈りました。次に、各モデルの複雑度 (次のトークンを予測する際の損失) を計算します。長いシーケンスのスケーラビリティを強調するために、Hypertention または FlashAttend によって実行されるかどうかにかかわらず、すべてのアテンション レイヤーにわたる合計の高速化も計算しました。 上記の図 3 に示す結果は次のとおりです。chatglm2-6b-32k が HyperAttendant モンキー パッチを通過したとしても、依然として適度な混乱が見られます。たとえば、レイヤー 20 を置き換えた後、パープレキシティは約 1 増加し、レイヤー 24 に到達するまでゆっくりと増加し続けます。アテンション レイヤーの実行時間は約 50% 改善されました。すべてのレイヤーを置き換えると、複雑度は 12 に上昇し、実行速度が 2.3 倍になります。 phi-1.5 モデルも同様の状況を示していますが、HyperAttendant の数が増加するにつれて、混乱は直線的に増加します。 さらに、研究者らは、また、LongBench データセット上でモンキーパッチを適用した chatglm2-6b-32k のパフォーマンスを評価し、単一/複数文書の質問応答、要約、小規模サンプル学習、合成タスク、コード補完などの各タスクの評価スコアを計算しました。評価結果を以下の表 1 に示します。 Hypertention を置き換えると、一般にパフォーマンスが低下しますが、その影響は当面のタスクに応じて変化することが観察されました。たとえば、要約とコード補完は、他のタスクに比べて最も堅牢です。 重要な点は、注意層の半分 (つまり 14 層) にパッチを適用した場合、研究者はほとんどのタスクのパフォーマンスが低下したことを確認したことです。 13%を超えることはありません。特にサマリー タスクのパフォーマンスはほとんど変化せず、このタスクがアテンション メカニズムの部分的な変更に対して最も堅牢であることを示しています。 n=32kの場合、注目層の計算速度は1.5倍となる。 #単一の自己注意層 彼らは、Hypertention で以前と同じパラメータを選択します。図 4 に示すように、因果マスクを適用しない場合、HyperAttendant の速度は 54 倍に向上し、因果マスクを適用すると 5.4 倍に高速化されます。因果マスキングと非マスキングの時間的混乱は同じですが、因果マスキングの実際のアルゴリズム (アルゴリズム 1) では、Q、K、V の分割、アテンション出力のマージなどの追加の操作が必要となり、実際の実行時間の増加につながります。シーケンスの長さ n が増加すると、加速度が高くなります。 研究者らは、これらの結果は推論に適用できるだけでなく、LLM のトレーニングや微調整にも使用できると考えています。より長いシーケンスに適応し、自己注意を拡張する新たな可能性を開きます
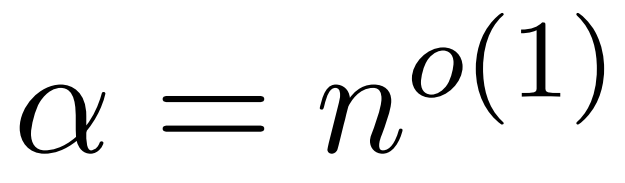 のようないくつかの
のようないくつかの 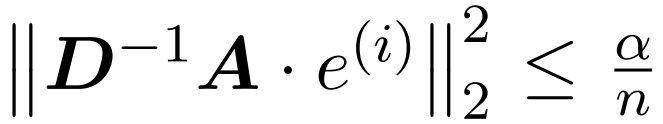 が存在すると仮定します。
が存在すると仮定します。 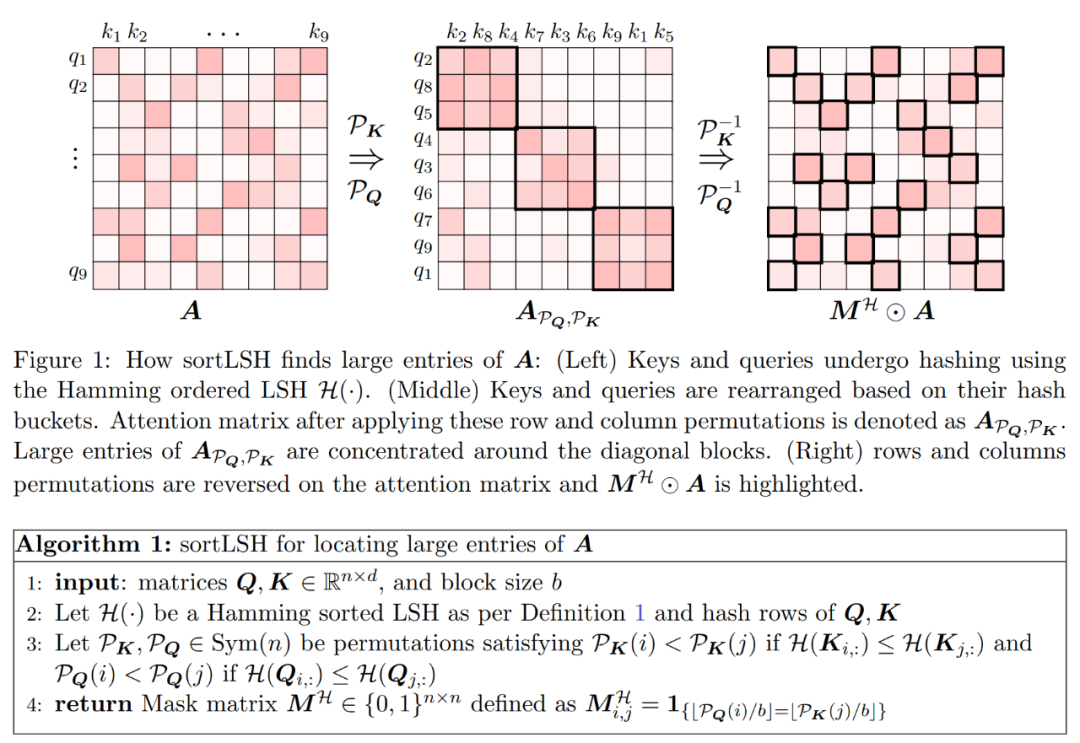


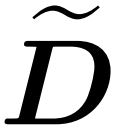 と近似
と近似 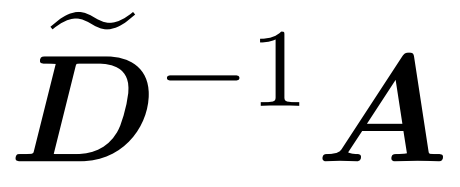 の間の行列積を積分するサブルーチン。そこで、研究者らは、式(1)のスペクトル保証を備えたアテンションメカニズムをほぼ線形時間で近似できる効率的なアルゴリズムであるHypertentionを導入した。アルゴリズム 3 は、アテンション マトリックス内の主要なエントリの位置を定義するマスク MH を入力として受け取ります。このマスクは、sortLSH アルゴリズム (アルゴリズム 1) を使用して生成することも、[7] のアプローチと同様に、事前定義されたマスクにすることもできます。大きなエントリ マスク M^H は設計によりスパースであり、その非ゼロ エントリの数は制限されていると仮定します。
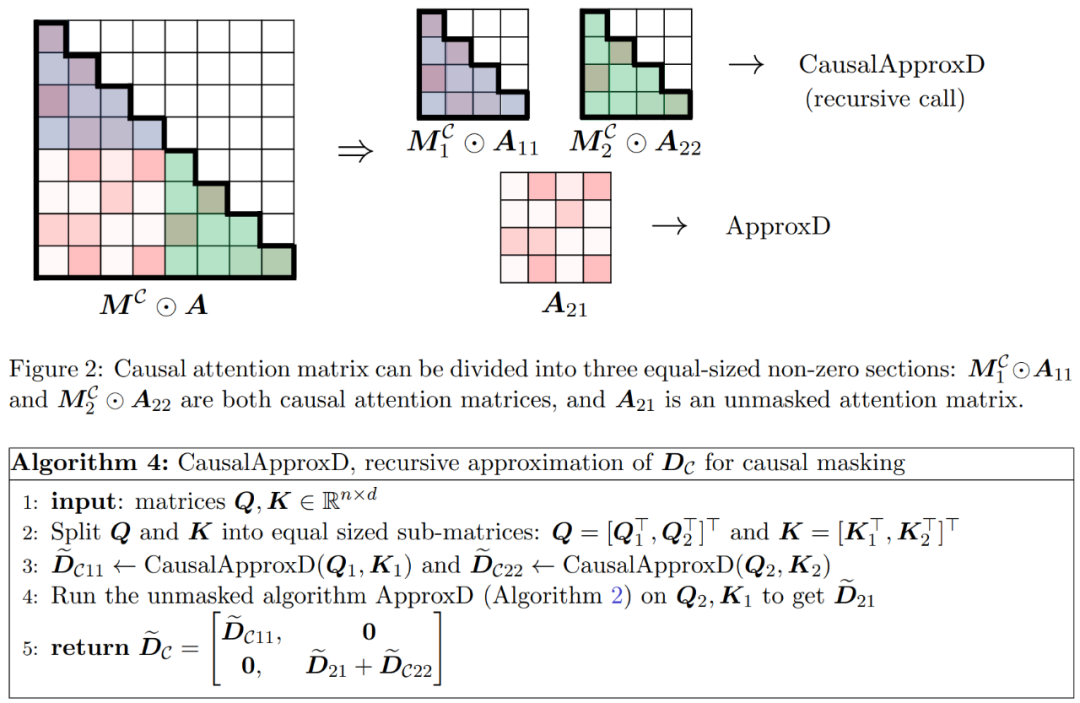
の間の行列積を積分するサブルーチン。そこで、研究者らは、式(1)のスペクトル保証を備えたアテンションメカニズムをほぼ線形時間で近似できる効率的なアルゴリズムであるHypertentionを導入した。アルゴリズム 3 は、アテンション マトリックス内の主要なエントリの位置を定義するマスク MH を入力として受け取ります。このマスクは、sortLSH アルゴリズム (アルゴリズム 1) を使用して生成することも、[7] のアプローチと同様に、事前定義されたマスクにすることもできます。大きなエントリ マスク M^H は設計によりスパースであり、その非ゼロ エントリの数は制限されていると仮定します。 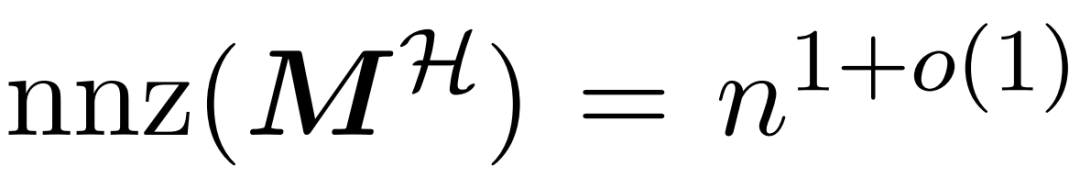 図 2 に示すように、この論文の方法は重要な観察に基づいています。マスクされたアテンション M^C⊙A は、それぞれが元のアテンション行列の半分のサイズである 3 つの非ゼロ行列に分解できます。対角線の完全に下のブロック A_21 は、マスクされていない注目の対象です。したがって、アルゴリズム 2 を使用してその行合計を近似できます。
図 2 に示すように、この論文の方法は重要な観察に基づいています。マスクされたアテンション M^C⊙A は、それぞれが元のアテンション行列の半分のサイズである 3 つの非ゼロ行列に分解できます。対角線の完全に下のブロック A_21 は、マスクされていない注目の対象です。したがって、アルゴリズム 2 を使用してその行合計を近似できます。  は因果的注意であり、そのサイズは全体の半分のみです。オリジナルサイズ。これらの因果関係に対処するために、研究者らは再帰的アプローチを使用し、それらをさらに小さなチャンクに分割し、プロセスを繰り返しました。このプロセスの疑似コードはアルゴリズム 4 に示されています。
は因果的注意であり、そのサイズは全体の半分のみです。オリジナルサイズ。これらの因果関係に対処するために、研究者らは再帰的アプローチを使用し、それらをさらに小さなチャンクに分割し、プロセスを繰り返しました。このプロセスの疑似コードはアルゴリズム 4 に示されています。 
研究者らは、既存の大規模言語モデルを拡張することによって長距離シーケンスを処理しました。そしてアルゴリズムのベンチマークを行います。すべての実験は単一の 40GB A100 GPU で実行され、正確なアテンションの計算に FlashAttendant 2 が使用されました。
以上が新しい近似アテンション メカニズム HyperAttendant: 長いコンテキストに適しており、LLM 推論を 50% 高速化します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



