


(Nweon、2023 年 11 月 13 日) 人間のユーザーの姿勢に関する情報を仮想の多関節表現にマッピングできます。たとえば、仮想現実環境に参加する場合、仮想環境における人間のユーザーのパフォーマンスは、現実世界の姿勢と同様の姿勢を示します。ユーザーの実世界のポーズは、事前にトレーニングされたモデルによって仮想多関節表現のポーズに変換でき、最終レンダリング用に同じ仮想多関節表現のポーズを出力するようにモデルをトレーニングできます。
場合によっては、システムは非現実的なパフォーマンスを表示する必要があります。たとえば、ユーザーは体のプロポーション、骨、その他の側面が異なる漫画のキャラクターを選択できます。
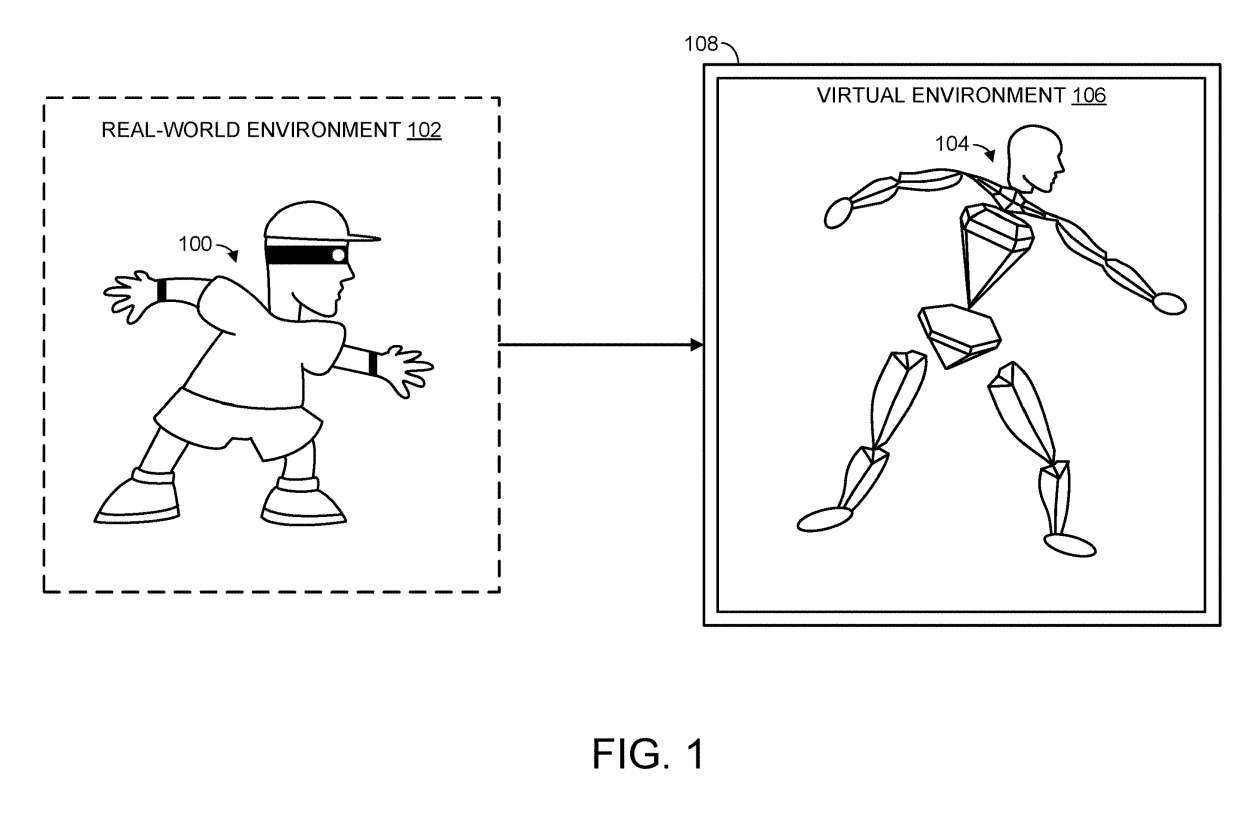 ####図1に示すように、現実世界環境102にいる人間のユーザ100が表示されている。図から分かるように、人間のユーザのジェスチャが多関節表現104に適用される。換言すれば、人間のユーザが現実世界の環境で活動を実行するとき、対応するアクションは仮想環境106における多関節表現104の動きに変換される。
####図1に示すように、現実世界環境102にいる人間のユーザ100が表示されている。図から分かるように、人間のユーザのジェスチャが多関節表現104に適用される。換言すれば、人間のユーザが現実世界の環境で活動を実行するとき、対応するアクションは仮想環境106における多関節表現104の動きに変換される。
具体的には、コンピューティングシステムは、1つまたは複数のセンサーからの入力に少なくとも部分的に基づいて、人間のユーザーの1つまたは複数の身体部分の詳細なパラメータに関する位置データを受信する。これらのセンサーには、ヘッドセットの慣性測定ユニットの出力だけでなく、適切なカメラの出力も含めることができます
書き換えられた内容は次のとおりです。システムは、ジョイント マッピング制約など、ターゲットのジョイント表現に関連付けられたモデルのジョイント表現の 1 つまたは複数のマッピング制約を同時に維持します。ポーズ最適化の機会では、位置決めデータとマッピング制約を使用して、モデル ジョイントによって表されるポーズとターゲット ジョイントによって表されるターゲット ポーズを同時に推定します。推定が完了すると、システムはターゲットの関節表現をターゲットのポーズとともに仮想表現として表示し、人間のユーザーが見ることができます
姿勢最適化マシンは、モデルの多関節表現のグラウンド トゥルース ラベルを含むトレーニング位置データを使用してトレーニングできます。ただし、トレーニング ローカリゼーション データには、ターゲットのアーティキュレーション表現のグラウンド トゥルース ラベルが不足している場合があります。
このアプローチを使用すると、さまざまな潜在的なターゲットごとに高価なトレーニング計算を必要とせずに、現実世界のポーズの正確な再現を効果的に達成できます。このテクノロジーの独創的な説明は、人間のユーザーにプラスの影響を与える可能性があります
ユーザーは仮想環境に参加するとき、自分自身を表す別のアバターを選択でき、コミュニケーション プロセス中いつでも自分の外観を変更できます。特定の表現に対してモデルを再トレーニングすることなく、新しいターゲットの多関節表現をユーザーが利用できる表現のメニューに追加できるため、計算コストを節約できます
本発明は、人間のユーザーの実世界のポーズを正確に再現し、その正確なポーズを複数の異なるターゲット関節表現のいずれかに適用できるようにしながら、計算リソースの消費を削減するという技術的利点を提供できる技術について説明します。具体的な方法としては、対象物とモデルの姿勢を同時に推定する方法がある。
人間の姿勢の仮想表現 200
の例を図 2 に示します。
### 202で、人間のユーザの1つまたは複数の体の部分の詳細なパラメータの位置データが、1つまたは複数のセンサからの入力に基づいて受信される。 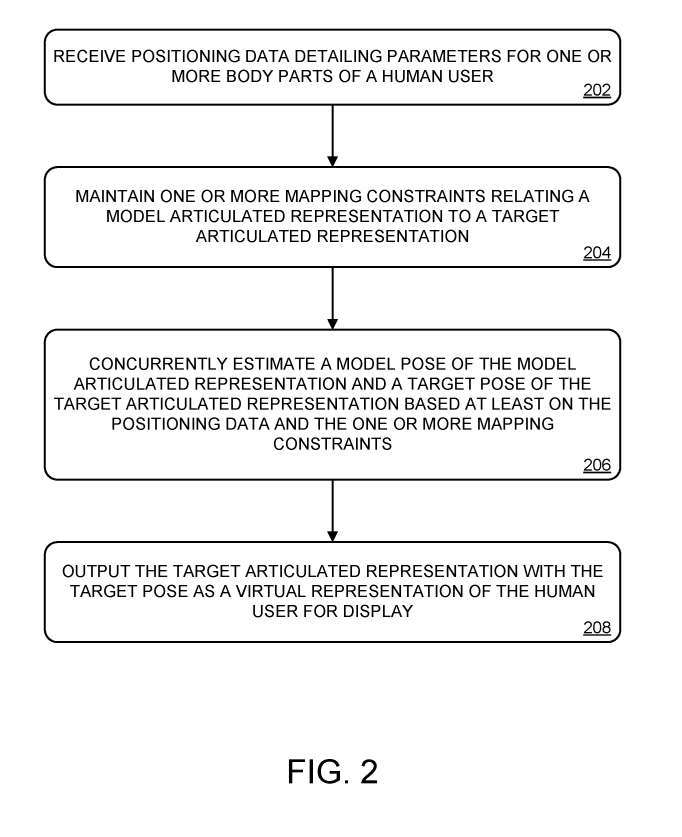
の例が示されています。
上で述べたように、ターゲット関節表現は仮想環境で表示するためにレンダリングされ、姿勢最適化マシンを通じてターゲット姿勢を出力することによって表示できます。例えば、ターゲット多関節表現は、任意の適切な外観および比率を有することができ、任意の適切な数の手足、関節、および/または他の可動身体部分を有することができる。
これは次のように書き換えることができます: ターゲットの関節表現は、人間以外の動物、架空のキャラクター、または任意の適切なアバターを表すことができます。モデルの多関節表現とターゲットの多関節表現は、1 つ以上のマッピング制約 402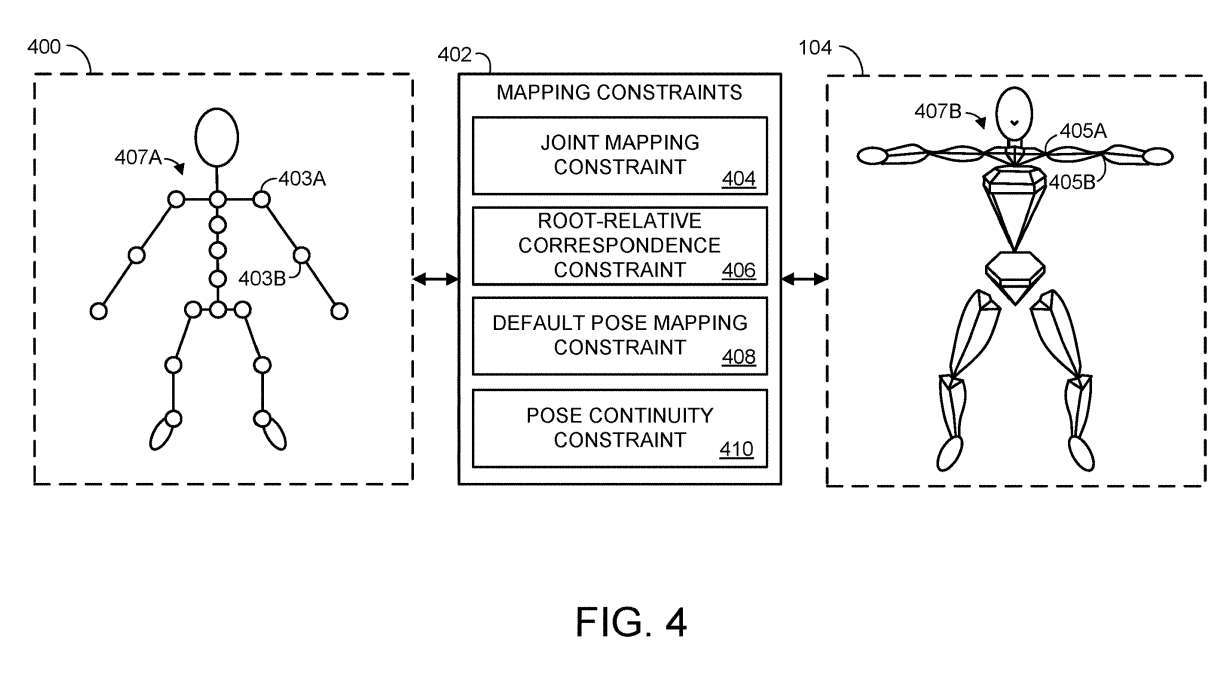 を通じて関連付けられます。
を通じて関連付けられます。
1つまたは複数のマッピング制約には、ジョイントマッピング制約404が含まれる場合があります。ターゲットの多関節表現内のジョイントの場合、ジョイント マッピング制約により、モデルの多関節表現内の 1 つまたは複数のジョイントのセットが指定されます。例えば、モデル多関節表現400は複数の関節を含み、そのうちの2つは肩関節および肘関節に対応する403Aおよび403Bとラベル付けされている。
ターゲット関節 No. 104 には、同様の関節 405A および 405B が含まれています。したがって、ターゲット表現のジョイント 405A および 405B は、複数の異なるジョイント マッピング制約を持つ可能性があり、これらのジョイントがモデル表現のジョイント 403A および 403B
にマップされることを示します。ジョイント マッピング コンストレイントでは、ターゲット ジョイント表現にマッピングするときに、各モデル ジョイントのウェイトをさらに指定できます。たとえば、モデルの多関節表現に、ターゲットの多関節表現の特定のジョイントにマッピングされたジョイントが 1 つだけある場合、そのモデルのジョイントのウェイトは 100% になる可能性があります。 2 つのモデル ジョイントがターゲット ジョイントにマッピングされている場合、2 つのモデル ジョイントのウェイトは 50% と 50%、30% と 70%、10% と 90% などになります。
### 図2において、方法200は、以前に訓練された姿勢を最適化することによって、モデルヒンジによって表されるモデル姿勢と、ターゲットヒンジによって表されるターゲット姿勢とを同時に推定する。モデルの姿勢とターゲットの姿勢の推定は、位置データに少なくとも部分的に依存します
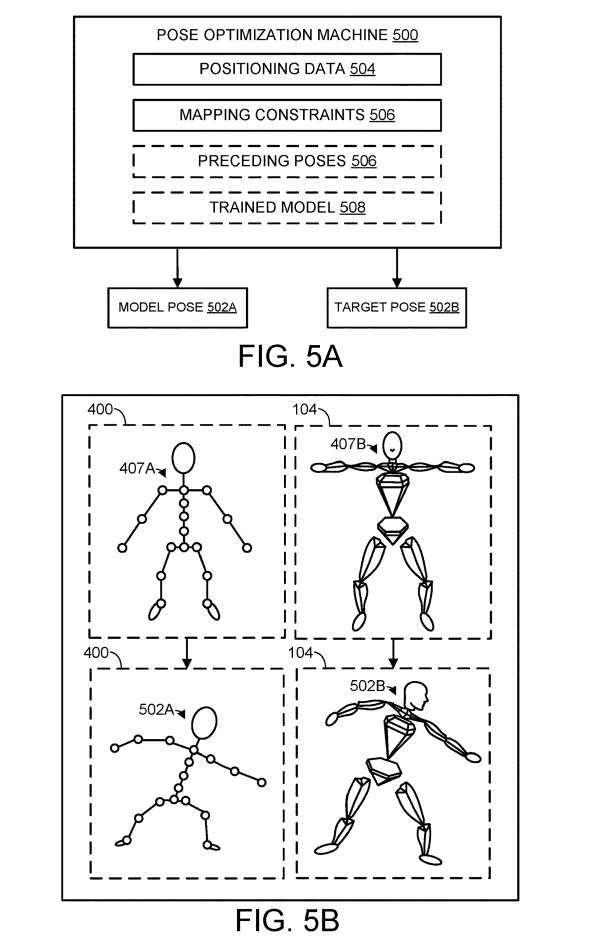 ### 図5Aは、姿勢最適化マシン500の一例を概略的に示しており、コンピュータ論理コンポーネントの任意の適切な組み合わせとして実装することができる。非限定的な例として、姿勢最適化マシン500は、図6に示されるような論理サブシステム602として実装され得る。
### 図5Aは、姿勢最適化マシン500の一例を概略的に示しており、コンピュータ論理コンポーネントの任意の適切な組み合わせとして実装することができる。非限定的な例として、姿勢最適化マシン500は、図6に示されるような論理サブシステム602として実装され得る。
#### 姿勢推定は、1つまたは複数の以前の時間フレームで推定された1つまたは複数の以前のモデル姿勢および以前のターゲット姿勢に基づいて、少なくとも部分的に達成され得る。したがって、ポーズ最適化マシン500は、各モデル関節に対する複数の局所回転として表すことができる複数の以前のポーズ506を記憶する。
1 つまたは複数のマッピング制約には、ポーズ連続性制約が含まれる場合があります。ポーズ連続性制約は、特定のジョイントのローカル回転がフレーム間でどの程度変化するかについてフレーム間の制約を課します。 一連のマッピング制約をポーズの連続性に適用して、フレーム間の変化の程度を制限することで特定のジョイントのローカル回転を制約できます。
図 5B は、推定されたモデルとターゲットのポーズをモデルとターゲットの多関節表現に適用するプロセスを概略的に示しています。具体的には、図5Bは、モデル多関節表現400およびターゲット多関節表現104に対応するデフォルト姿勢407Aおよび407Bを再度示す。次に、関節の方向を変えることにより、モデル関節表現400はモデル姿勢502Aをとり、目標関節表現104は目標姿勢502B###をとる。姿勢最適化では、モデルの姿勢とターゲットの姿勢を同時に推定する必要があります。つまり、他の方法とは異なり、姿勢最適化マシンは最初にモデルの姿勢表現を出力し、それからそれをターゲットの姿勢表現に変換しません。対照的に、姿勢推定は、一連の制約を満たすモデルの姿勢とターゲットの姿勢を同時に見つけるプロセスです。
たとえば、モデルの多関節表現のポーズは、位置データのセットが与えられた場合に考えられる人間のポーズを出力する姿勢最適化マシンの事前トレーニングによって制約できます。また、ターゲットの多関節表現のポーズは、モデルを使用したターゲットの関節表現。1 つ以上の関連するマッピング制約を表す制約。### さらに、前のトレーニングでは、姿勢推定は、姿勢最適化を実行する機械学習モデル508によって実装することができる。一例では、ポーズ最適化マシンは、まばらな入力位置決めデータに基づいてポーズを出力するように構成され得る。言い換えれば、姿勢最適化マシンは、実行時に受け取るより多くの入力パラメータに応じて、より正確な姿勢推定値を出力するようにトレーニングできます。
言い換えれば、姿勢最適化マシンが受信した位置データには、人間のユーザーの n 個の関節の回転パラメーターが含まれている可能性があります。前回のトレーニングでは、姿勢最適化マシンは n m 個の関節の回転パラメーターを入力として受け取りました。ここで、m は 1 より大きくなります。次に、モデルの関節によって表現される n m 個のモデル関節の回転パラメータを推定することで、推定されたモデルの姿勢を決定できます。少なくとも n 個の関節に基づく回転パラメータが必要ですが、m 個の関節に基づく回転パラメータは必要ありません。さらに、姿勢最適化マシンをトレーニングするときに、ターゲットの多関節表現のグラウンド トゥルース ラベルを含める必要はありません。代わりに、ターゲットの多関節表現は、1 つ以上のマッピング制約を通じてモデルの多関節表現と関連付けられ、通常はターゲットのポーズがモデルのポーズと実質的に類似するように制約されます。
Microsoft は、上記のテクノロジを使用すると、プロセスの速度を 2 桁向上させることができると指摘しています。これにより、特殊なハードウェア アクセラレーションを必要とせずに、モデルとターゲットのポーズをリアルタイムで同時に推定できるようになります。
### 図2において、方法200は、表示のために人間のユーザの仮想表現としてターゲット姿勢を有するターゲット多関節表現を出力することを含み、このステップは208で行われる。例えば、図1では、ターゲットの多関節表現104が電子表示装置108を通じて表示される。ターゲットの多関節表現を表示するために使用される表示装置は、任意の適切な形式をとることができ、任意の適切な基礎となる表示技術を使用することができる
関連特許: Microsoft Patent | 仮想表現のための人間の同時姿勢推定「仮想表現のための同時人間姿勢推定」というタイトルの Microsoft 特許出願は、もともと 2022 年 4 月に提出され、最近米国特許商標庁によって公開されました。
以上が並列人間姿勢推定特許:Microsoft AR/VR技術で仮想表現を実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



