


DeepMindは「Transformerはトレーニング前のデータを超えて一般化できない」と指摘したが、これに疑問を抱く人もいた。

Transformer は、「トレーニング データ」を超える新しい問題を解決できない運命にあるのでしょうか?
大規模な言語モデルによって実証される優れた機能について言えば、その 1 つはコンテキスト内でサンプルを提供し、モデルに応答を生成するよう要求することで、少数の言語モデルの能力を達成できることです。 -ショット学習。これは基盤となる機械学習技術「Transformer モデル」に依存しており、言語以外の領域でも文脈学習タスクを実行できます。
過去の経験に基づいて、事前トレーニングされた混合で適切に表現されているタスク ファミリまたは関数クラスの場合、コンテキスト学習に適切な関数クラスを選択するコストはほとんどかからないことが証明されています。したがって、一部の研究者は、Transformer はトレーニング データと同じ分布に分散されたタスクや関数をうまく一般化できると考えています。ただし、よくある未解決の疑問は、トレーニング データの分布と一致しないサンプルに対してこれらのモデルがどのように機能するのかということです。
最近の研究では、DeepMind の研究者が実証研究の助けを借りてこの問題を調査しました。彼らは一般化問題を次のように説明しています: 「モデルは、事前トレーニングされたデータの混合でどの基本関数クラスにも属さない関数を使用して、コンテキスト内の例で適切な予測を、どの基本関数にも含まれていない関数から生成できますか?」事前トレーニング データの混合に見られる関数クラスは? )>>
この記事の焦点は、事前トレーニング プロセスで使用されたデータのいくつかのサンプルを調査し、結果として得られる Transformer モデルの学習能力への影響を検討することです。この問題を解決するために、研究者らはまず、事前トレーニング プロセス中にモデル選択のためにさまざまな関数クラスを選択する Transformer の機能を研究し (セクション 3)、次にいくつかの主要なケースの OOD 一般化問題に答えました (セクション 4)

論文リンク: https://arxiv.org/pdf/2311.00871.pdf
彼らの研究では次の状況が判明しました: まず、Transformer の事前トレーニング事前トレーニングされた関数クラスから抽出された関数の凸の組み合わせを予測することは非常に困難です。第 2 に、Transformer は関数クラス空間のまれな部分を効果的に一般化できますが、タスクがその分布範囲を超えると、Transformer は依然として失敗します。エラーが発生しました
Transformer は事前トレーニング データを超えて認知に一般化できないため、認知を超えた問題を解決することはできません

一般的に、この記事の貢献は次のとおりです。 :
- # コンテキスト学習用にさまざまな関数クラスを混合して使用して Transformer モデルを事前トレーニングし、モデル選択動作の特性を説明します。;
- ##事前トレーニング データの関数クラスと「矛盾」する関数については、コンテキスト学習における事前トレーニングされた Transformer モデルの動作が研究されました #強力な証拠が示されましたモデルは、追加の統計コストをほとんど必要とせずに、コンテキスト学習中に事前トレーニングされた関数クラス間でモデル選択を実行できますが、モデルのコンテキスト学習動作が事前トレーニング データの範囲を超える可能性があるという限られた証拠もあります。
- この研究者は、これはセキュリティにとって良いニュースかもしれないと考えています。少なくともモデルは思うように動作しません。
 ただし、 、この論文で使用されているモデルは適切ではないと指摘する人もいます。「GPT-2 スケール」は、この論文のモデルに約 15 億のパラメータがあることを意味しており、一般化するのは確かに困難です。
ただし、 、この論文で使用されているモデルは適切ではないと指摘する人もいます。「GPT-2 スケール」は、この論文のモデルに約 15 億のパラメータがあることを意味しており、一般化するのは確かに困難です。

 #次に、論文の詳細を見てみましょう。
#次に、論文の詳細を見てみましょう。
さまざまな関数クラスのデータ混合物を事前トレーニングする場合、問題に直面します。モデルが事前トレーニングでサポートされている問題に遭遇したときです。コンテキスト サンプルを使用するときに、さまざまな関数クラスを選択するにはどうすればよいですか?
研究では、モデルが事前トレーニング データ内の関数クラスに関連するコンテキスト サンプルにさらされると、最良 (または最良に近い) 予測を行うことができることがわかりました。研究者らはまた、どの単一コンポーネント関数クラスにも属さない関数に対するモデルのパフォーマンスも観察しました。セクション 4 では、事前トレーニング データとまったく無関係な関数について説明します
まず、一次関数の研究から始めますが、一次関数は文脈学習の分野で広く注目を集めていることがわかります。昨年、スタンフォード大学のパーシー・リアンらは「トランスフォーマーはコンテキストで何を学ぶことができるか?」という論文を発表した。単純な関数クラスのケース スタディでは、事前トレーニングされたトランスフォーマーが新しい線形関数コンテキストの学習において非常にうまく機能し、ほぼ最適レベルに達していることが示されています。
彼らは特に 2 つのモデルを検討しました。1 つは密な A モデルです。もう 1 つは線形関数でトレーニングされたモデル (線形モデルのすべての係数がゼロ以外)、もう 1 つはスパース線形関数でトレーニングされたモデル (20 個の係数のうち 2 つだけがゼロではない) です。各モデルは、新しい密線形関数および疎線形関数に対して、それぞれ線形回帰および Lasso 回帰と同等のパフォーマンスを示しました。さらに研究者らは、これら 2 つのモデルを、疎な線形関数と密な線形関数の混合で事前トレーニングされたモデルと比較しました。
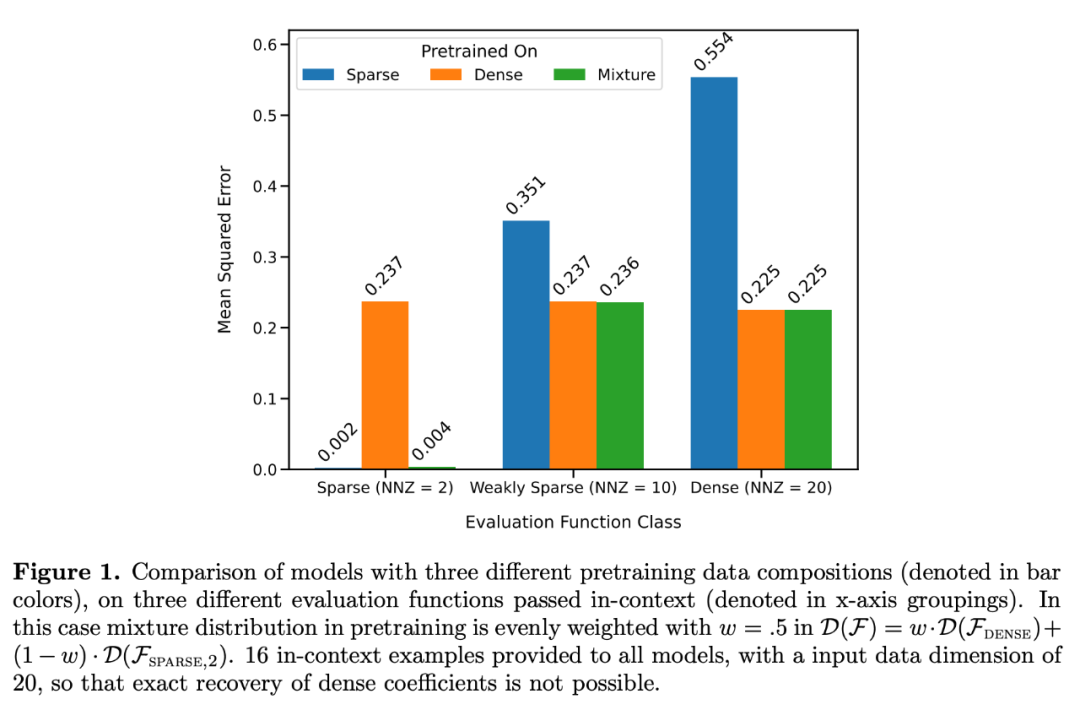
図 1 に示すように、コンテキスト学習における 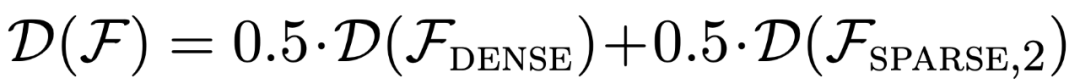 混合物に対するモデルのパフォーマンスは、1 つの関数クラスのみで事前学習されたモデルと同様です。ハイブリッド事前トレーニング モデルのパフォーマンスは Garg ら [4] の理論上の最適モデルと類似しているため、研究者らはこのモデルも最適に近いものであると推測しています。図 2 の ICL 学習曲線は、このコンテキスト モデルの選択能力が、提供されるコンテキスト例の数と比較的一致していることを示しています。図 2 では、特定の関数クラスに対して、自明ではないさまざまな重みが使用されていることもわかります。
混合物に対するモデルのパフォーマンスは、1 つの関数クラスのみで事前学習されたモデルと同様です。ハイブリッド事前トレーニング モデルのパフォーマンスは Garg ら [4] の理論上の最適モデルと類似しているため、研究者らはこのモデルも最適に近いものであると推測しています。図 2 の ICL 学習曲線は、このコンテキスト モデルの選択能力が、提供されるコンテキスト例の数と比較的一致していることを示しています。図 2 では、特定の関数クラスに対して、自明ではないさまざまな重みが使用されていることもわかります。 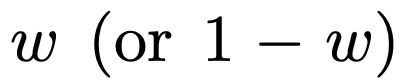
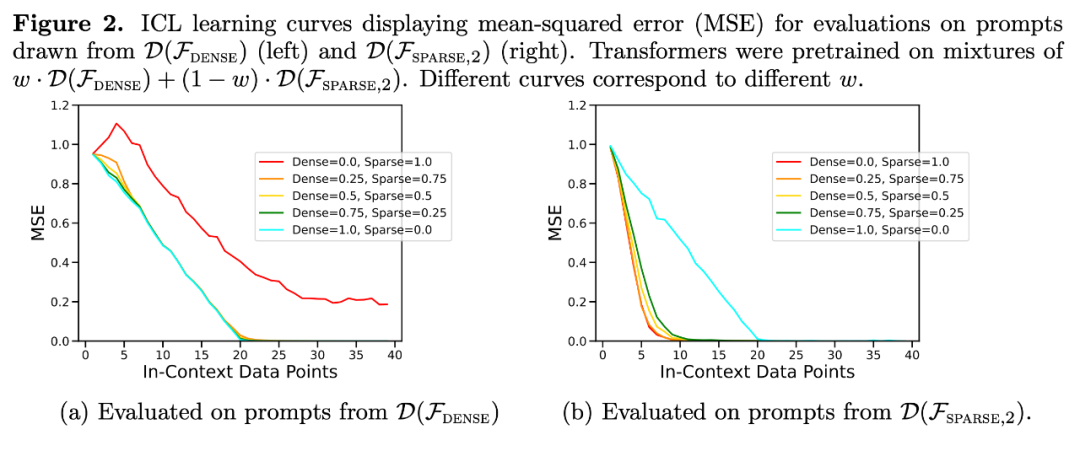
 実際、図 3b は、コンテキストで提供されたサンプルが非常に疎な関数または非常に密な関数からのものである場合、予測結果は、疎なデータのみを使用して、または密なデータのみを使用して事前学習されたモデルの予測結果とほぼ同じであることを示しています。 . .ただし、その中間で、非ゼロ係数の数が ≈ 4 の場合、ハイブリッド予測は、純粋に密な、または純粋にスパースの事前学習済み Transformer の予測から逸脱します。
実際、図 3b は、コンテキストで提供されたサンプルが非常に疎な関数または非常に密な関数からのものである場合、予測結果は、疎なデータのみを使用して、または密なデータのみを使用して事前学習されたモデルの予測結果とほぼ同じであることを示しています。 . .ただし、その中間で、非ゼロ係数の数が ≈ 4 の場合、ハイブリッド予測は、純粋に密な、または純粋にスパースの事前学習済み Transformer の予測から逸脱します。
これは、混合物で事前トレーニングされたモデルが、予測する単一の関数クラスを単に選択するのではなく、その間の結果を予測することを示しています。
モデル選択能力の限界次に、研究者らはモデルの ICL 一般化能力を 2 つの観点から検討しました。まず、トレーニング中にモデルが公開されていない関数の ICL パフォーマンスがテストされ、次に、モデルが事前トレーニング中に公開された関数の極端なバージョンの ICL パフォーマンスが評価されます。これら 2 つのケースでは、研究では分布外の一般化の証拠はほとんど見つかりません。関数が事前トレーニング中に見られた関数と大きく異なる場合、予測は不安定になります。関数が事前トレーニング データに十分に近い場合、モデルは適切に近似できます
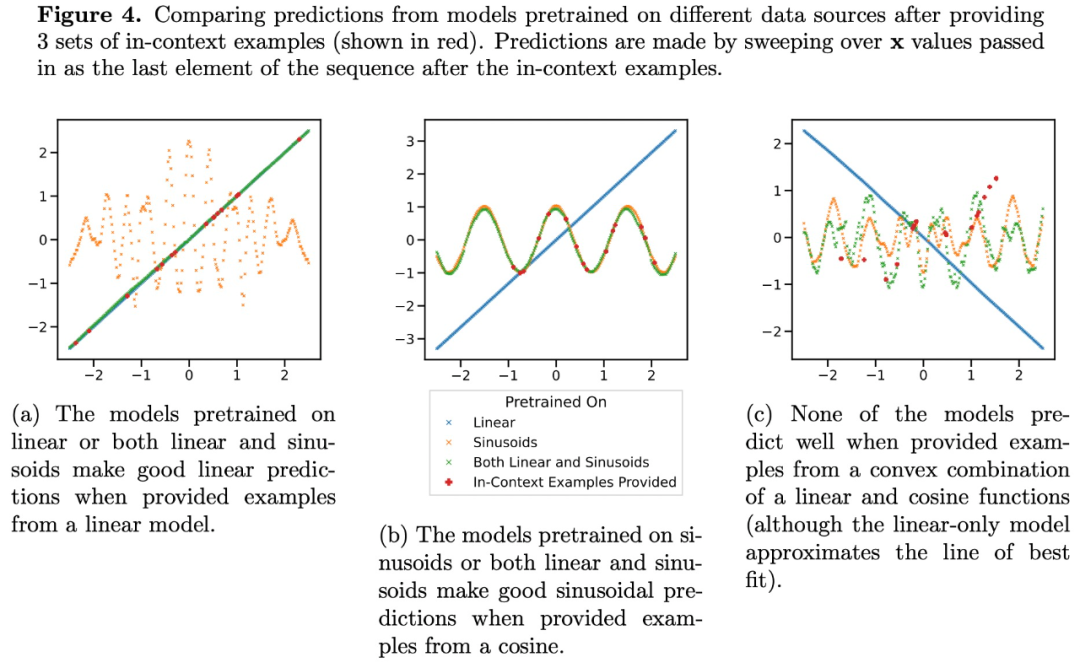
中程度のスパース レベル (nnz = 3 ~ 7) での Transformer の予測は、事前トレーニングによって提供される関数クラスの予測とは似ていませんが、図 3a に示すように、その中間に位置します。したがって、モデルには、事前にトレーニングされた関数クラスを自明ではない方法で組み合わせることができる、ある種の帰納的バイアスがあると推測できます。たとえば、モデルが事前トレーニング中に見られた関数の組み合わせに基づいて予測を生成できるのではないかと考えられます。この仮説を検証するために、線形関数、正弦波、およびこれら 2 つの凸状の組み合わせに対して ICL を実行できるかどうかを調査しました。彼らは、非線形関数クラスの評価と視覚化を容易にするために 1 次元のケースに焦点を当てています。
図 4 は、モデルが線形関数と正弦波の混合物 (つまり  ) で事前学習されているのを示しています。これら 2 つの関数のいずれかを個別に適切に予測するには、2 つの凸組み合わせを当てはめることはできません。これは、図 3b に示す線形関数補間現象が、Transformer コンテキスト学習の一般化可能な誘導バイアスではないことを示唆しています。ただし、コンテキスト サンプルが事前トレーニングで学習した関数クラスに近い場合、モデルは予測に最適な関数クラスを選択できるというより狭い仮定を引き続きサポートします。
) で事前学習されているのを示しています。これら 2 つの関数のいずれかを個別に適切に予測するには、2 つの凸組み合わせを当てはめることはできません。これは、図 3b に示す線形関数補間現象が、Transformer コンテキスト学習の一般化可能な誘導バイアスではないことを示唆しています。ただし、コンテキスト サンプルが事前トレーニングで学習した関数クラスに近い場合、モデルは予測に最適な関数クラスを選択できるというより狭い仮定を引き続きサポートします。
研究の詳細については、元の論文を参照してください
以上がDeepMindは「Transformerはトレーニング前のデータを超えて一般化できない」と指摘したが、これに疑問を抱く人もいた。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7364
7364
 15
1628
14
1353
52
1265
25
1214
29
15
1628
14
1353
52
1265
25
1214
29

 「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
現代の製造において、正確な欠陥検出は製品の品質を確保するための鍵であるだけでなく、生産効率を向上させるための核心でもあります。ただし、既存の欠陥検出データセットには、実際のアプリケーションに必要な精度や意味論的な豊富さが欠けていることが多く、その結果、モデルが特定の欠陥カテゴリや位置を識別できなくなります。この問題を解決するために、広州香港科技大学と Simou Technology で構成されるトップの研究チームは、産業欠陥に関する詳細かつ意味的に豊富な大規模なアノテーションを提供する「DefectSpectrum」データセットを革新的に開発しました。表 1 に示すように、他の産業データ セットと比較して、「DefectSpectrum」データ セットは最も多くの欠陥注釈 (5438 個の欠陥サンプル) と最も詳細な欠陥分類 (125 個の欠陥カテゴリ) を提供します。
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
オープンな LLM コミュニティは百花繚乱の時代です Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 などがご覧いただけます。優秀なパフォーマーモデル。しかし、GPT-4-Turboに代表される独自の大型モデルと比較すると、オープンモデルには依然として多くの分野で大きなギャップがあります。一般的なモデルに加えて、プログ�