


最近、「中国語を披露するテイラー・スウィフト」の動画が主要なソーシャルメディアで急速に人気を博し、その後「英語を披露する郭徳剛」などの同様の動画も登場しました。これらのビデオの多くは、「HeyGen」と呼ばれる人工知能アプリケーションによって作成されています
# ただし、HeyGen の現在の人気から判断すると、同様のビデオを作成するためにそれを使用したいと考えています。長い間列に並んで待ちます。幸いなことに、これが唯一の方法ではありません。テクノロジーを理解している友人は、音声からテキストへのモデル Whisper、テキスト翻訳 GPT、オーディオ so-vits-svc を生成するための音声クローン、オーディオ GeneFace dengdeng に一致する口の形のビデオの生成など、他の代替案を探すこともできます。
#書き換えられた内容は次のとおりです。 その中でも、Whisper は OpenAI によって開発されオープンソース化されている自動音声認識 (ASR) モデルであり、非常に使いやすいです。彼らは、Web から収集した 680,000 時間の多言語 (98 言語) およびマルチタスク監視データに基づいて Whisper をトレーニングしました。 OpenAI は、このような大規模で多様なデータセットを使用することで、アクセント、背景雑音、専門用語を認識するモデルの能力を向上できると考えています。 Whisper は音声認識に加えて、複数の言語を書き起こして英語に翻訳することもできます。現在、Whisper には多くのバリアントがあり、多くの AI アプリケーションを構築する際に必要なコンポーネントとなっています
最近、HuggingFace チームは新しいバリアント Distil-Whisper を提案しました。このバリアントは Whisper モデルの改良版であり、小型、高速、非常に高い精度を特徴としており、低遅延が必要な環境やリソースが限られている環境での使用に非常に適しています。ただし、複数の言語を処理できる元の Whisper モデルとは異なり、Distil-Whisper は英語のみを処理できます。

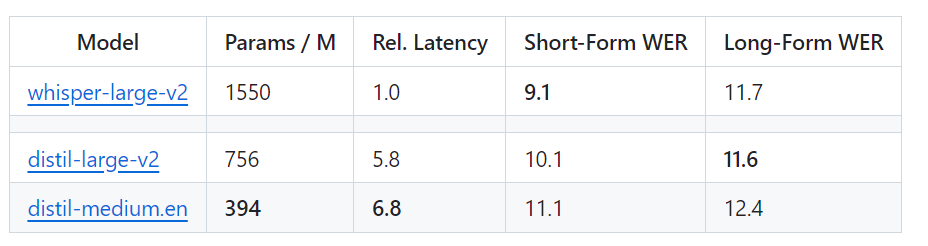
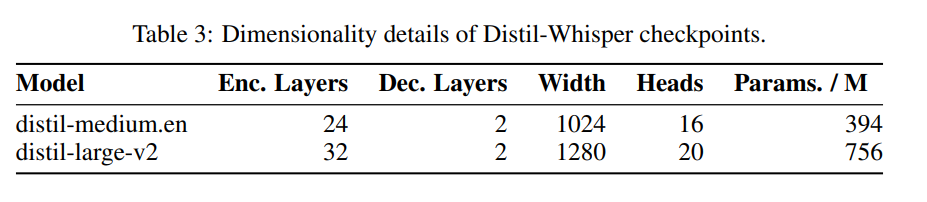
具体的には、Distil-Whisper には 2 つのバージョンがあり、パラメーター サイズは 756M (distil-large-v2) と 394M (distil-medium.en)
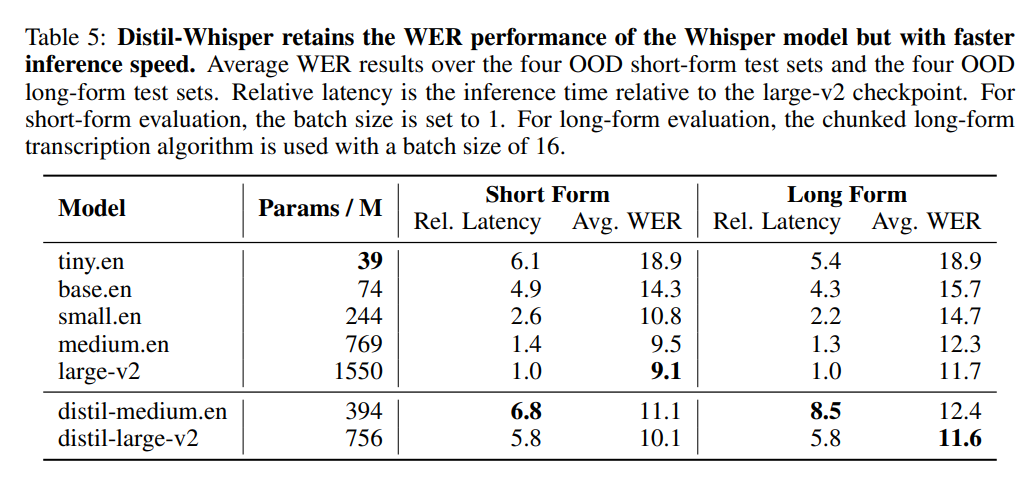
#OpenAI の Whisper-large-v2 と比較すると、756M バージョンの distil-large-v2 はパラメータが半分以上ありますが、6 倍の加速を達成し、精度は Whisper に非常に近くなります。 -large-v2. 短い音声の Word Error Rate (WER) の差は 1% 以内で、長い音声では Whisper-large-v2 よりも優れています。これは、慎重なデータの選択とフィルタリングにより、Whisper の堅牢性が維持され、錯覚が軽減されるためです。
 Whisper の Web バージョンの速度を Distil-Whisper の速度と視覚的に比較します。画像出典:https://twitter.com/xenovacom/status/1720460890560975103
Whisper の Web バージョンの速度を Distil-Whisper の速度と視覚的に比較します。画像出典:https://twitter.com/xenovacom/status/1720460890560975103
つまり、リリースされてまだ2、3日ですが、Distil-Whisperはすでに1000を超えています出演者。
テストリンクは次のとおりです: https://github.com/Vaibhavs10/insanely-fast-whisper#insanely-fast-whisper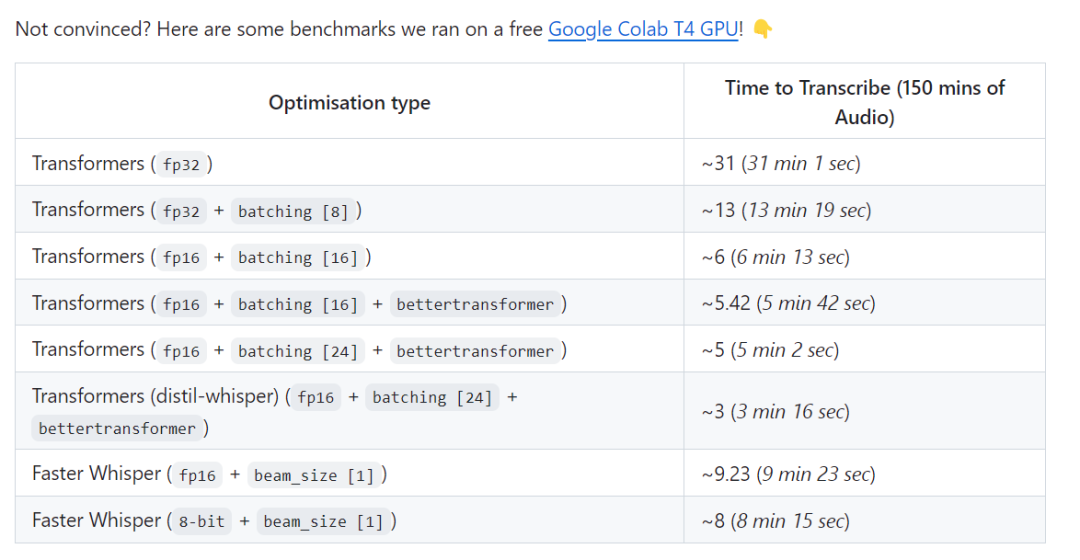
では、このような良い結果はどのようにして達成されるのでしょうか?論文の著者らは、擬似ラベル技術を使用して大規模なオープンソース データセットを構築し、このデータセットを使用して Whisper モデルを Distil-Whisper に圧縮したと述べています。シンプルな WER ヒューリスティックを使用し、トレーニング用に最高品質の疑似ラベルのみを選択します
以下は元の内容を書き直したものです。 Distil-Whisper のアーキテクチャを以下の図 1 に示します。研究者らは、教師モデルからエンコーダー全体をコピーすることで学生モデルを初期化し、トレーニング中にそれをフリーズさせました。彼らは、OpenAI の Whisper-medium.en モデルと Whisper-large-v2 モデルから最初と最後のデコーダー層をコピーし、蒸留後に distil-medium.en と ditil-medium.en という名前の 2 つのデコーダー チェックポイントを取得しました。 v2
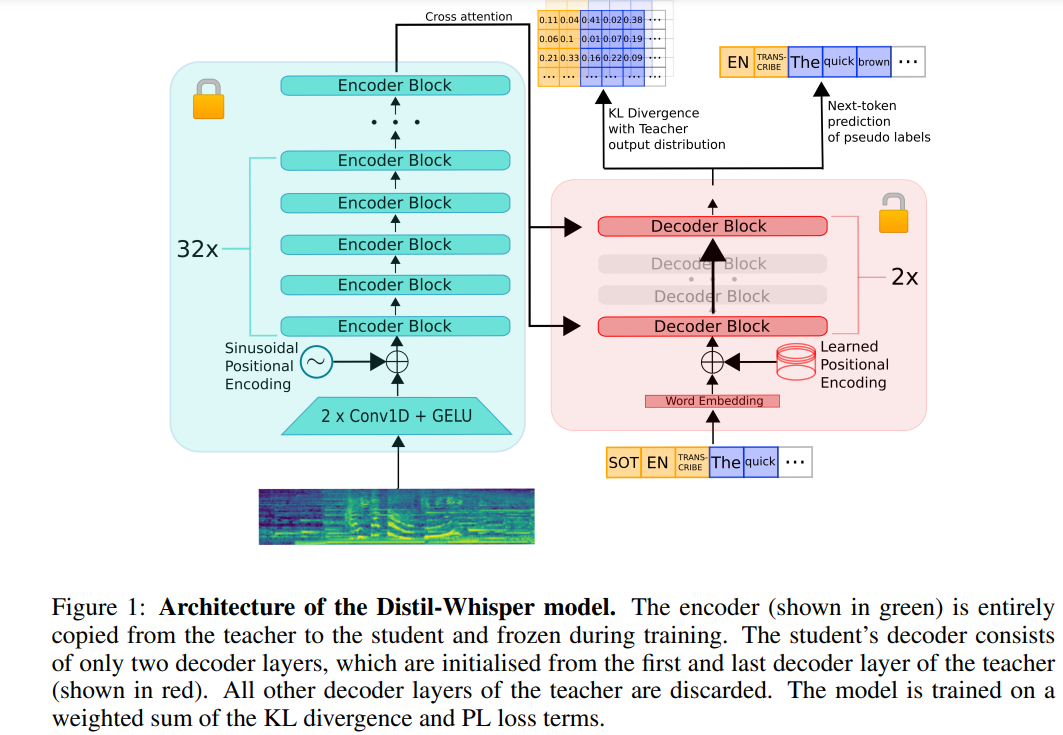
を表 3 に示します。
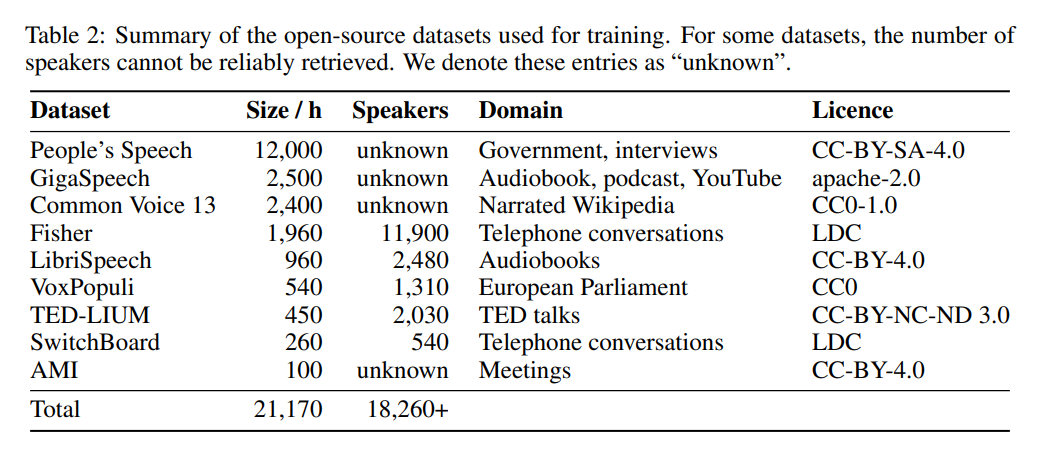
データに関しては、モデルは 9 つの異なるオープンソース データセットで 22,000 時間トレーニングされています (表 2 を参照)。疑似タグは Whisper によって生成されます。 WER フィルターを使用し、WER スコアが 10% を超えるタグのみが保持されたことは注目に値します。著者は、これがパフォーマンスを維持するための鍵であると述べています。
以下の表 5 は、Distil-Whisper の主なパフォーマンス結果を示しています。
#著者によると、エンコーダの動作をフリーズすることで、Distil-Whisper はノイズに対して非常に堅牢に動作するとのことです。以下の図に示すように、Distil-Whisper はノイズの多い条件下で Whisper と同様の堅牢性曲線に従い、Wav2vec2
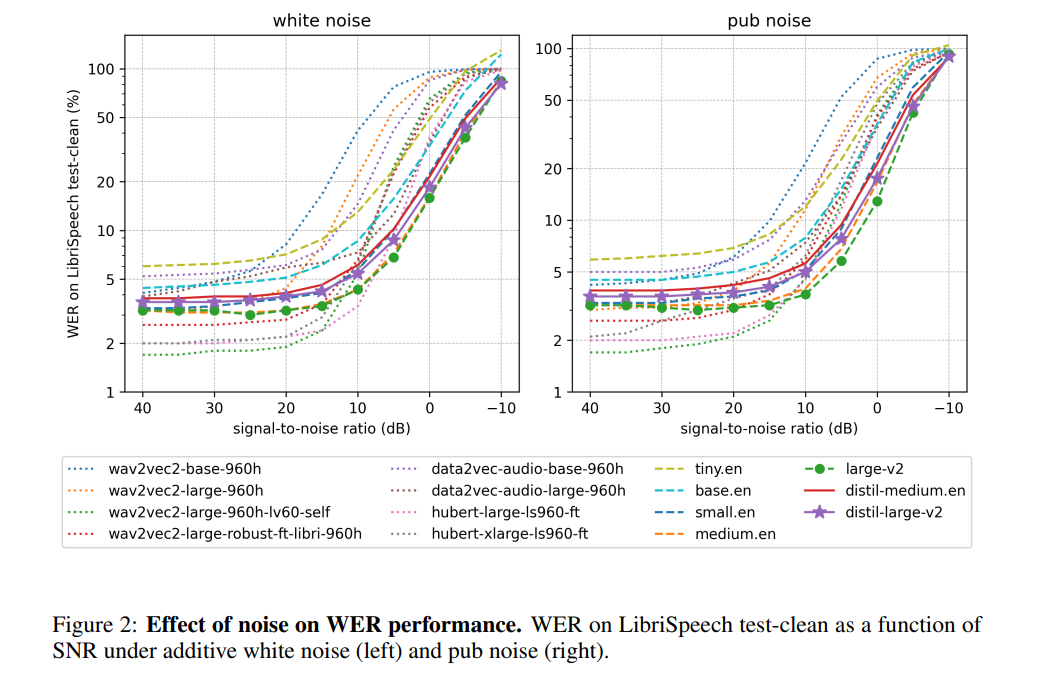
# # などの他のモデルよりも優れたパフォーマンスを発揮します。比較的長い音声ファイルを処理する場合、Whisper と比較して、Distil-Whisper は幻覚を効果的に軽減します。著者によれば、これは主に WER フィルタリングによるものです。
同じエンコーダを共有することで、Distil-Whisper を Whisper と組み合わせて、投機的デコードを行うことができます。 (投機的デコード)。これにより、Whisper とまったく同じ出力を生成しながら、パラメータを 8% 増加させるだけで 2 倍のスピードアップが実現します。
詳細については、原文をご覧ください。
以上がOpenAIのWhisper蒸留後、音声認識速度が大幅に向上:星の数は2日で1,000を超えたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



