


最近、大規模な言語モデルは、さまざまな自然言語処理タスク、特に複雑な思考連鎖 (CoT) 推論を必要とする数学的問題において大きな進歩を遂げています
たとえば、GSM8KやMATHなどの難しい数学的タスクのデータセットでは、GPT-4やPaLM-2を含む独自のモデルが顕著な成果を上げています。この点で、オープンソースの大規模モデルにはまだ改善の余地がかなりあります。数学的タスク用のオープンソースの大規模モデルの CoT 推論機能をさらに向上させるための一般的なアプローチは、注釈付き/生成された質問と推論のデータ ペア (CoT データ) を使用してこれらのモデルを微調整することです。タスク中に CoT 推論を実行します。
最近、西安交通大学、マイクロソフト、北京大学の研究者らは、論文の中で、逆学習プロセス(つまり、大学の間違いから学ぶこと)による改善アイデアを検討しました。 LLM ) 推論能力をさらに向上させるために
#数学を学び始める生徒と同じように、まず教科書の知識ポイントと例を学習して理解を深めます。しかし同時に、学んだことを定着させるための演習も行っています。困難に遭遇したり、問題の解決に失敗したりすると、自分がどのような間違いを犯したかに気づき、それを修正する方法を学び、「間違った問題集」を形成します。間違いから学ぶことで、彼の推論能力はさらに向上します
このプロセスに触発されたこの研究では、間違いを理解して修正することで LLM の推論能力がどのように向上するかを探ります。

論文アドレス: https://arxiv.org/pdf/2310.20689.pdf
特定の具体的には、研究者らはまず誤り訂正データのペア (訂正データと呼ばれる) を生成し、次にその訂正データを使用して LLM を微調整しました。修正データを生成するとき: 何を書き直す必要があるか、複数の LLM (LLaMA および GPT ファミリのモデルを含む) を使用して不正確な推論パス (つまり、最終的な答えが不正確) を収集し、その後 GPT-4 を「修正者」として使用しました。 、これらの不正確な推論パスに対する修正を生成します
#生成された修正には、(1) 元の解決策の間違ったステップ、(2) そのステップが間違っていたという説明の 3 つの情報が含まれています。間違っている 正しい理由; (3) 正しい最終答えに到達するために元の解決策を修正する方法。不正確な最終回答を含む修正を除外した後、手動評価により、修正データがその後の微調整フェーズに十分な品質を示していることがわかりました。研究者らは、QLoRA を使用して CoT データと補正データの LLM を微調整し、それによって「エラーからの学習」(LEMA) を実行しました。
研究によると、現在の LLM は段階的なアプローチを使用して問題を解決できることが示されていますが、この複数段階の生成プロセスは、LLM 自体が強力な推論能力を備えていることを意味するものではありません。これは、基礎的なロジックと必要なルールを真に理解せずに、人間の推論の表面的な動作を模倣するだけである可能性があるためです。
この理解の欠如は、推論プロセスでエラーを引き起こす可能性があるため、ヘルプ「世界モデル」は現実世界の論理とルールを先験的に認識しているため、「世界モデル」の理解が必要となります。この観点から、この記事の LEMA フレームワークは、単に段階的な動作を模倣するのではなく、より小さなモデルにこれらのロジックやルールに従うように教えるための「ワールド モデル」として GPT-4 を使用していると見ることができます。
##次に、この研究の具体的な実装手順を見てみましょう#方法の概要
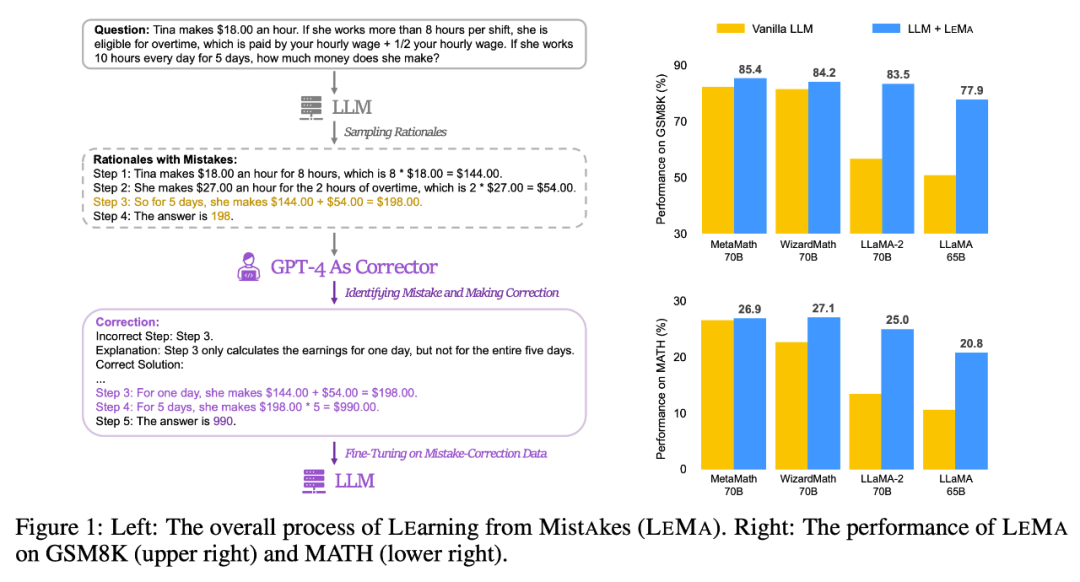
質問と回答の例 #不正確な推論パスの修正。研究者は、次の式(1)に示すように、まず推論モデル M_r を使って質問 q_i ごとに複数の推論パスをサンプリングし、最終的に正解 a_i に至らなかったパスのみを保持します。 エラーに対する修正 を生成します。質問 q_i と不正確な推論パス #具体的には、注釈付きの修正には、次の 3 つのカテゴリの情報が含まれます。 エラー ステップ: 元の推論パス どのステップが間違っていたか。 修正された人間の評価を生成します 。より大きなデータを生成する前に、まず生成された補正の品質を手動で評価しました。彼らは LLaMA-2-70B を M_r として、GPT-4 を M_c として使用し、GSM8K トレーニング セットに基づいて 50 個の誤り訂正されたデータ ペアを生成しました。 研究者らは、リビジョンを 3 つの品質レベル (優れた、良好、不良) に分類しました。以下は 3 つのレベルの例です
微調整が必要なのは LLM です 修正データを生成した後、書き直す必要があるものを研究者らは LLM を微調整し、モデルが間違いから学習できるかどうかを評価しました。主に、次の 2 つの微調整設定の下でパフォーマンスの比較を実行します。 1 つ目は、 思考連鎖 (CoT) データの を微調整することです。研究者は、疑問の根拠となるデータのみに基づいてモデルを微調整します。各タスクには注釈付きデータがありますが、さらに CoT データ拡張が採用されています。研究者らは GPT-4 を使用して、トレーニング セット内の各質問に対してさらに推論パスを生成し、不正確な最終回答を含むパスを除外しました。彼らは、CoT データ拡張を活用して、CoT データのみを使用する堅牢な微調整ベースラインを構築し、微調整を制御するデータ サイズに関するアブレーション研究を促進します。 2 つ目は、CoT データ補正データを 微調整することです。 CoT データに加えて、研究者らは微調整用の誤り訂正データ (つまり LEMA) も生成しました。また、データ サイズの増加による影響を軽減するために、データ サイズを制御したアブレーション実験も実施しました。
その後のアブレーション研究では、LEMA が同じ量のデータで CoT のみの微調整よりも優れたパフォーマンスを示していることが示されています。これは、両方のデータ ソースを組み合わせた方が単一のデータ ソースを使用するよりも大きな改善が得られるため、CoT データと修正データの効果が同等ではないことを示唆しています。これらの実験結果と分析は、LLM 推論機能を強化するためにエラーから学習する可能性を強調しています。 研究の詳細については、元の論文を参照してください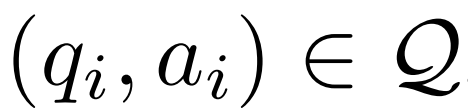 、修正モデル M_c と推論モデル M_r を考慮して、研究者は誤り修正データのペアを生成しました。
、修正モデル M_c と推論モデル M_r を考慮して、研究者は誤り修正データのペアを生成しました。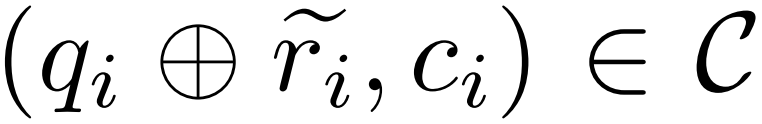 、
、 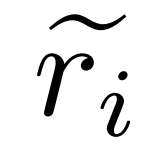 は質問 q_i の不正確な推論パスを表し、c_i は
は質問 q_i の不正確な推論パスを表し、c_i は 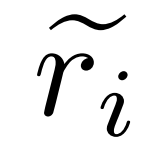 に対する修正を表します。
に対する修正を表します。 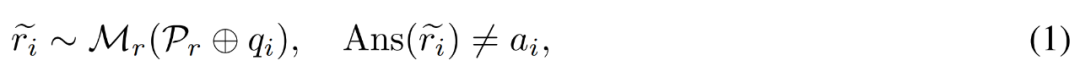
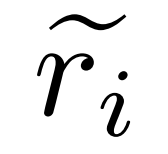 について、研究者は、以下の式 (2) に示すように、修正モデル M_c を使用して修正を生成し、修正内の正解を確認します。
について、研究者は、以下の式 (2) に示すように、修正モデル M_c を使用して修正を生成し、修正内の正解を確認します。 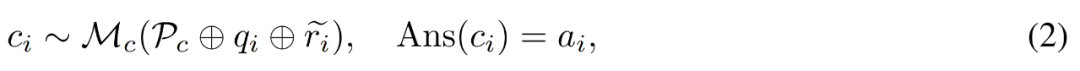


 ##評価の結果、次のことがわかりました。 , 50 件のビルド修正のうち、35 件は優れた品質、11 件は良好、4 件は低品質でした。この評価に基づいて、研究者らは、GPT-4 を使用して生成された補正の全体的な品質は、さらなる微調整段階に十分であると結論付けました。したがって、より大規模な修正を生成し、最終的に微調整が必要な LLM の正解につながるすべての修正を使用しました。
##評価の結果、次のことがわかりました。 , 50 件のビルド修正のうち、35 件は優れた品質、11 件は良好、4 件は低品質でした。この評価に基づいて、研究者らは、GPT-4 を使用して生成された補正の全体的な品質は、さらなる微調整段階に十分であると結論付けました。したがって、より大規模な修正を生成し、最終的に微調整が必要な LLM の正解につながるすべての修正を使用しました。 

研究者らは、実験結果を通じて、5 つのオープンソース LLM と 2 つの困難な数学的推論タスクに対する LEMA の有効性を実証しました
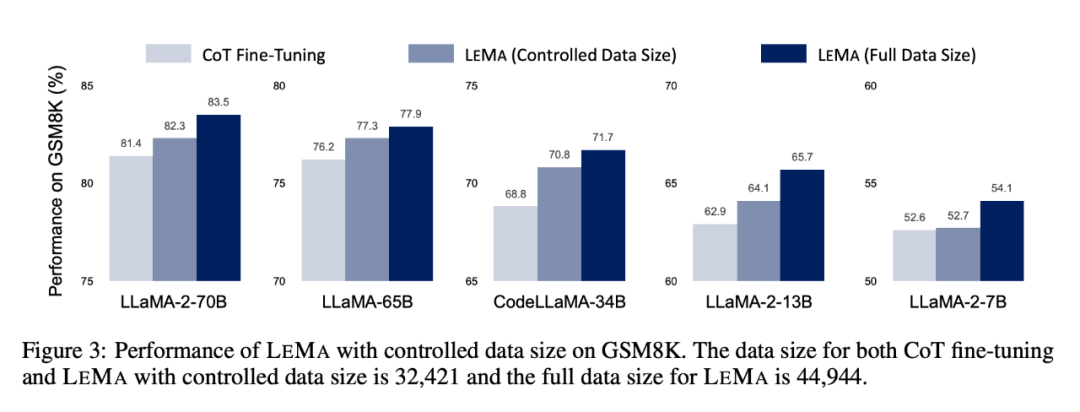 #LEMA は、CoT データを微調整するだけの場合と比較して、さまざまな LLM およびタスク全体のパフォーマンスを一貫して向上させます。たとえば、LLaMA-2-70B を使用した LEMA は、GSM8K と MATH でそれぞれ 83.5% と 25.0% を達成しましたが、CoT データのみの微調整ではそれぞれ 81.4% と 23.6% を達成しました
#LEMA は、CoT データを微調整するだけの場合と比較して、さまざまな LLM およびタスク全体のパフォーマンスを一貫して向上させます。たとえば、LLaMA-2-70B を使用した LEMA は、GSM8K と MATH でそれぞれ 83.5% と 25.0% を達成しましたが、CoT データのみの微調整ではそれぞれ 81.4% と 23.6% を達成しました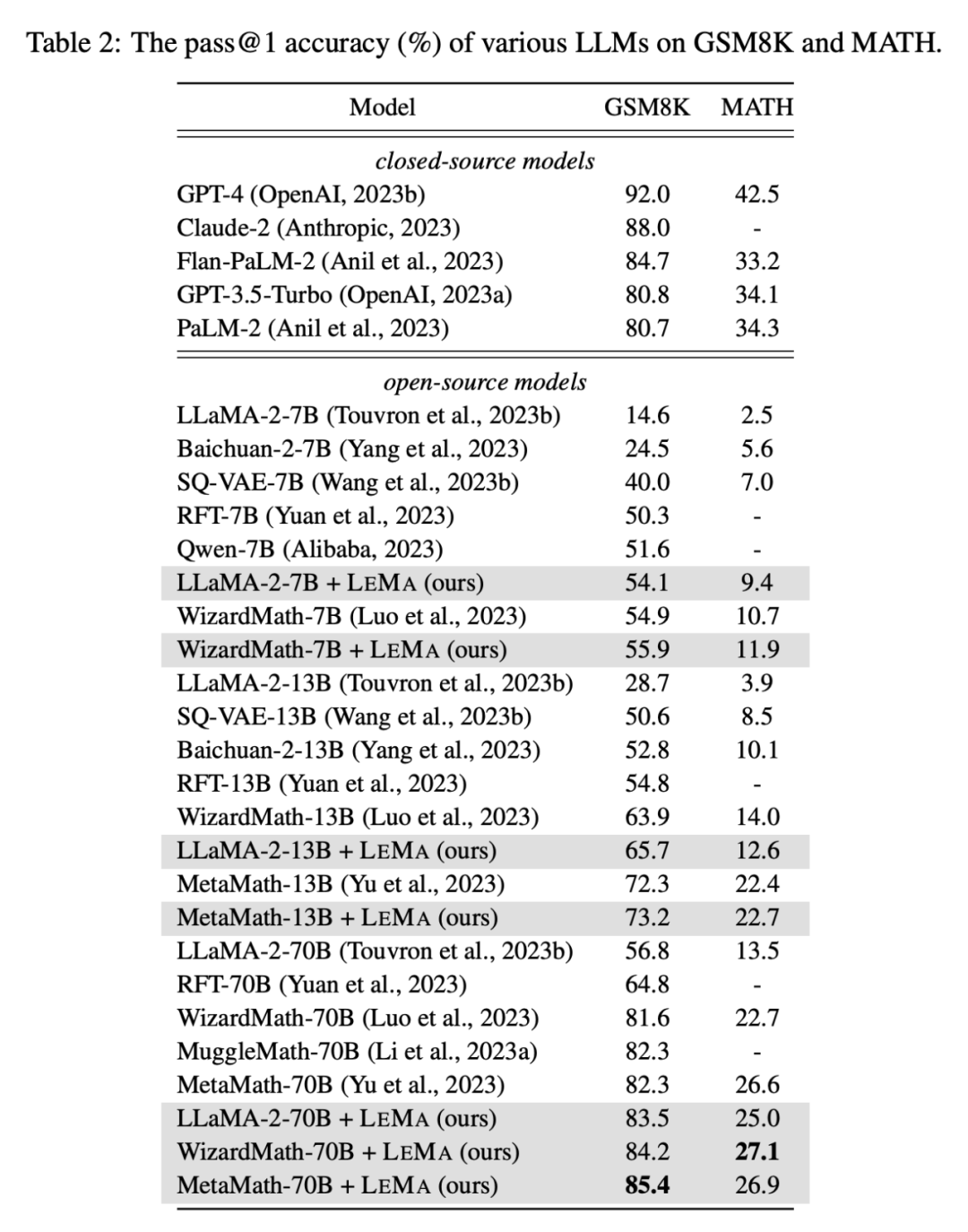 さらに、LEMA は独自の LLM と互換性があります。WizardMath-70B/MetaMath-70B を搭載した LEMA は、GSM8K 精度で 84.2%/85.4% pass@1 を達成し、27.1%/26.9 の pass@1 精度を達成します。 MATH では % を達成しており、これらの困難なタスクで多くのオープンソース モデルが達成する SOTA パフォーマンスを上回っています。
さらに、LEMA は独自の LLM と互換性があります。WizardMath-70B/MetaMath-70B を搭載した LEMA は、GSM8K 精度で 84.2%/85.4% pass@1 を達成し、27.1%/26.9 の pass@1 精度を達成します。 MATH では % を達成しており、これらの困難なタスクで多くのオープンソース モデルが達成する SOTA パフォーマンスを上回っています。
以上がGPT-4 は「世界モデル」を作成し、LLM が「間違った質問」から学習し、推論能力を大幅に向上できるようにします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



