


この記事は、自動運転の心臓部公開アカウントの許可を得て転載しています。転載については、原文提供元にご連絡ください。
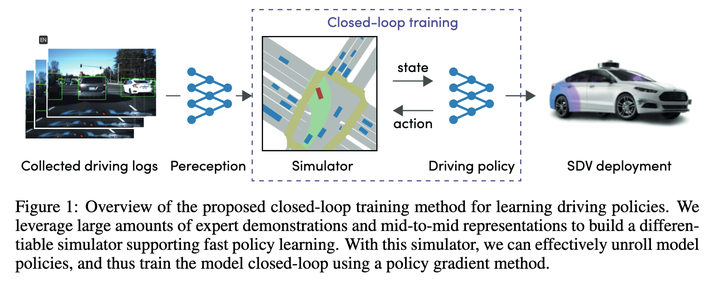
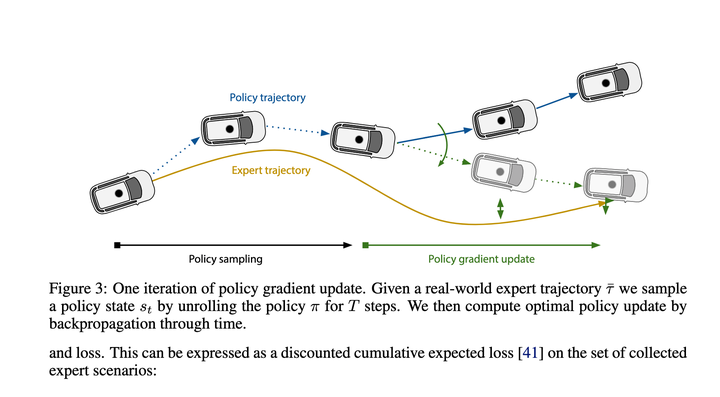 ## 大まかに見てみると、主な目的は、Policy Gradients を使用して、State->Recent Action のマッピング関数を学習することです。全体の実行軌跡は段階的に推定できますが、最終的に損失となるのは、推定によって与えられる軌跡をエキスパートの軌跡にできるだけ近づけることです。
## 大まかに見てみると、主な目的は、Policy Gradients を使用して、State->Recent Action のマッピング関数を学習することです。全体の実行軌跡は段階的に推定できますが、最終的に損失となるのは、推定によって与えられる軌跡をエキスパートの軌跡にできるだけ近づけることです。
現時点では効果はかなり優れているはずなので、新しいアルゴリズムのベースラインになる可能性があります。
2. 南洋理工大学プログラム 1 逆強化学習による条件付き予測行動計画 2023.04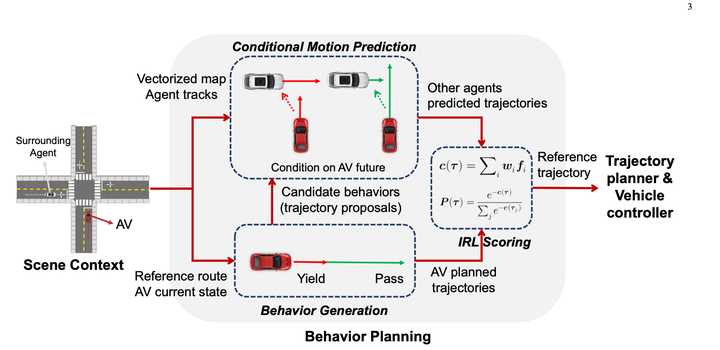 最初にルールを使用してこれを多数列挙します動作により 10 ~ 30 の軌道が生成されます。 (予測結果は使用されません)
最初にルールを使用してこれを多数列挙します動作により 10 ~ 30 の軌道が生成されます。 (予測結果は使用されません)
条件付き結合予測モデルは次のようになります:
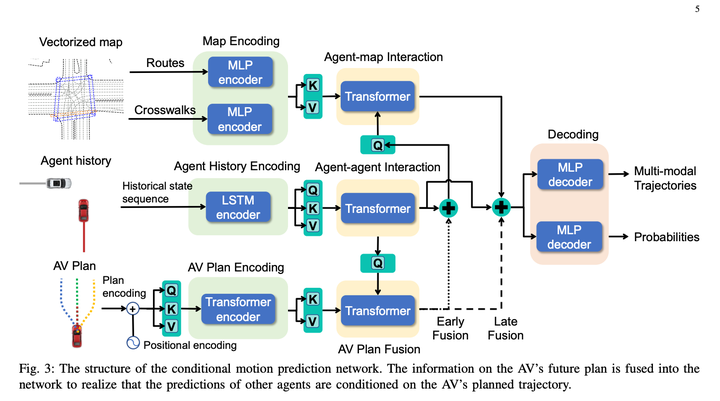 このメソッドの基本的な優れた点は、条件付き結合予測を使用して良好な対話性を実現していることです。予測により、アルゴリズムに特定のゲーム能力が与えられます。
このメソッドの基本的な優れた点は、条件付き結合予測を使用して良好な対話性を実現していることです。予測により、アルゴリズムに特定のゲーム能力が与えられます。
ただし、次元が1つ多いため、その後の展開回数が多すぎると、依然として解空間が大きくなり、計算量が膨大になってしまいます。ノードが多すぎたらランダムに破棄する 計算量を制御できるようにいくつかのノードを追加する (ノードが多すぎるとnレベル後になって影響が小さくなる可能性があるという意味のような気がする)
この記事の主な貢献は、このツリー形状を通じて連続解空間を渡すことです。サンプリング ルールはマルコフ決定プロセスを変換し、その後 dp を使用して解決します。
4. 2023 年 10 月の南洋理工大学と NVIDIA の最新共同計画: DTPP: 自動運転におけるツリー政策計画のための微分可能な結合条件付き予測とコスト評価1. 条件付き予測は特定のゲーム効果を保証します
2. これは導出可能であり、勾配全体を戻すことができるため、予測を IRL と一緒にトレーニングできます。また、エンドツーエンドの自動運転を構築できるようにするための必要条件でもあります。3. 特定のインタラクティブな演繹機能を持つ可能性のあるツリー ポリシー プランニング
注意深く読んだ後、これがわかりました。この記事は非常に有益であり、その方法は非常に巧妙です。
 NVIDIA の TPP と南洋工科大学の条件付き予測行動計画を逆強化学習で組み合わせて改善した結果、前回の南洋工科大学の論文で候補者の軌道が不十分であるという問題を解決することができました。
NVIDIA の TPP と南洋工科大学の条件付き予測行動計画を逆強化学習で組み合わせて改善した結果、前回の南洋工科大学の論文で候補者の軌道が不十分であるという問題を解決することができました。
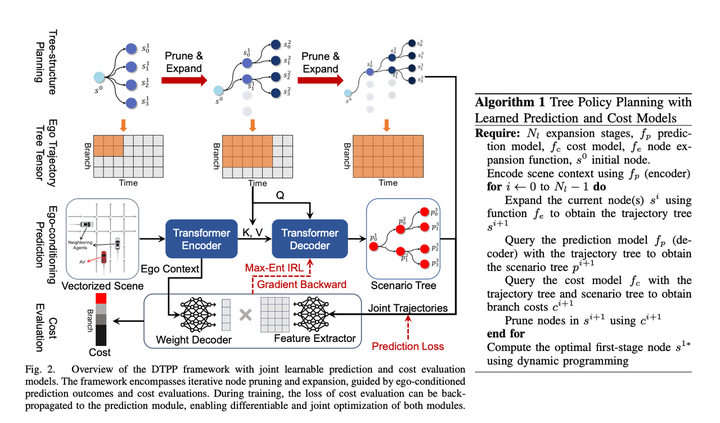
紙の計画の主なモジュールには次のものが含まれます:
1. 条件付き予測モジュール、主車両の履歴軌跡、プロンプト軌跡および障害車両の履歴軌跡を入力し、主車両の予測軌跡を与えるプロンプト軌道に近づく、および障害車両の予測軌道がホスト車両の挙動と一致する。
2. スコアリング モジュールは、主車両障害物車両の軌跡をスコアリングして、その軌跡が専門家の行動に似ているかどうかを確認できます。学習方法は IRL です。3. 多数の候補軌道を生成するために使用されるツリー ポリシー検索モジュール
ツリー検索アルゴリズムを使用して、主要車両の実行可能なソリューションを探索します。探索プロセスの各ステップでは、探索された軌跡を入力として受け取り、条件付き予測アルゴリズムを使用して、主要車両と障害物車両の予測軌跡を生成します。軌道を評価するためにスコアリング モジュールを呼び出します。メリットとデメリットは、拡張ノードの次の検索の方向に影響します。この方法により、他のソリューションとは異なるいくつかの主な車両の軌道を生成し、軌道を生成する際に障害車両との相互作用を考慮することができます
従来の IRL は多くの機能を手動で作成します。モデルを微分可能にするために、この記事では、予測のエゴ コンテキスト MLP を直接使用して、軌跡時間次元 (size = 1 * C) で障害物の束の Weight 配列 (相対 s、l、ttc など) を生成します。 、ホスト車両の周囲の環境情報を暗黙的に表し、MLP を使用してホスト車両の軌跡に対応するマルチモーダル予測結果を特徴配列に直接変換します (サイズ = C * N、N は軌跡の候補数を指します) )、次に 2 つの行列を乗算して、最終的な軌道スコアを取得します。次に、IRL は専門家に最高点を獲得させます。個人的には、これは計算効率を考えてデコーダをできるだけシンプルにするためではないかと感じていますが、それでも主要な車両情報がある程度失われます。計算効率を重視しない場合は、もう少し複雑なネットワークを使用して、 Ego Context と Predicted Trajectory を接続すると、効果レベルが向上するはずです。または、微分可能性をあきらめた場合でも、手動で設定された特徴を追加することを検討できます。これにより、モデルの効果も向上するはずです。
時間的には、このソリューションでは 1 回の再エンコードと複数回の軽量デコードという手法を採用しており、計算遅延の削減に成功しています。この記事では、遅延を 98 ミリ秒に圧縮できると指摘しています。
これは、学習ベースのプランナーの中で SOTA ランクに属しており、閉ループ効果は、記事で言及されている nuplan の No.1 ルールベース スキーム PDM に近いです。前の記事。
これを見た後、このパラダイムは非常に良いアイデアだと感じました。特定のプロセスは自分で調整できます。

書き直す必要があります内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/ZJtMU3zGciot1g5BoCe9Ow
以上が自動運転のためのエンドツーエンドの計画手法のレビューの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



