



Big Data Digest 制作
人工知能 (AI) がチェス、囲碁、Dota を征服した後、家族の友人、私はこの記事を書いているこのスキルはAIロボットにも学ばれています。

上記のペン回しロボットは、NVIDIA とペンシルバニア大学が提供する Eureka と呼ばれるエージェントの恩恵を受けています。カリフォルニア工科大学とテキサス大学オースティン校。
エウレカの「指導」を受けると、ロボットは引き出しやキャビネットを開けたり、ボールを投げたりキャッチしたり、ハサミを使ったりすることもできます。 Nvidia によると、Eureka には 10 種類のタイプがあり、29 種類のタスクを実行できます。
過去には、人間の専門家による手動プログラミングではペン転送機能をこれほどスムーズに実現できなかったことを知っておく必要があります。

ロボット パンウォルナット
そして、Eureka はロボットを訓練するための報酬アルゴリズムを独自に作成でき、コーディングが可能です。 power 強力: 自作の報酬プログラムは、タスクの 83% において人間の専門家を上回り、ロボットのパフォーマンスを平均 52% 向上させます。
Eureka は、人間のフィードバックによる勾配のない新しい学習方法を作成し、人間が提供する報酬やテキスト フィードバックを容易に吸収することで、独自の報酬生成メカニズムをさらに改善します。
具体的には、Eureka は OpenAI の GPT-4 を利用して、ロボットの試行錯誤学習のための報酬プログラムを作成します。これは、システムが人間のタスク固有の合図や事前に設定された報酬パターンに依存しないことを意味します。
Eureka は、Isaac Gym で GPU 高速化された シミュレーションを使用して、多数の候補報酬のメリットを迅速に評価できるため、より効率的なトレーニングが可能になります。次に、Eureka はトレーニング結果の主要な統計の概要を生成し、LLM (言語モデル) をガイドして報酬関数の生成を改善します。このようにして、AI エージェントはロボットへの指示を独自に改善することができます。
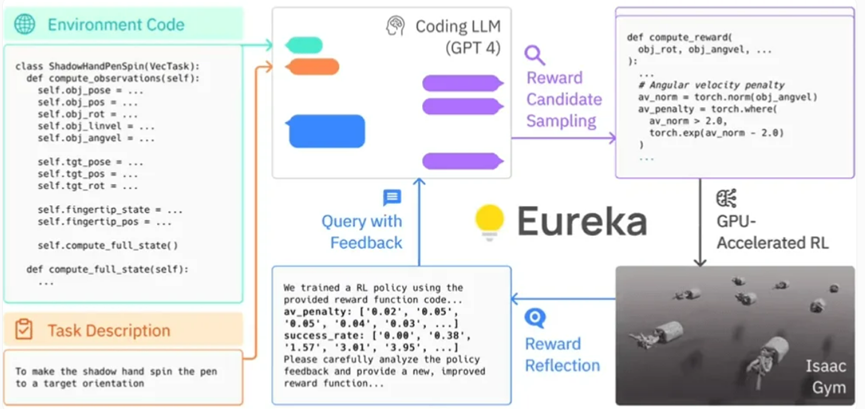
Eureka のフレームワーク
研究者らは、タスクが複雑になればなるほど、 GPT-4 の命令は、いわゆる「報酬エンジニア」による人間の命令よりも優れています。 この研究に関わった研究者らは、エウレカを「超人的な報酬エンジニア」とさえ呼んだ。
#Eureka は、高レベルの推論 (エンコード) と低レベルのモーター制御の間のギャップを埋めることに成功しました。これは、いわゆる「ハイブリッド グラディエント アーキテクチャ」を使用しており、純粋な推論ブラック ボックス LLM (言語モデル) が学習可能なニューラル ネットワークをガイドします。このアーキテクチャでは、外側のループは GPT-4 を実行して報酬関数 (勾配なし) を最適化し、内側のループは強化学習を実行してロボットのコントローラー (勾配ベース) をトレーニングします。
- Linxi "Jim" Fan、上級研究員、NVIDIA
Eureka は人間のフィードバックを統合してより良い調整を行うことができます開発者の期待とより密接に一致する報酬を提供します。 Nvidia は、このプロセスを「インコンテキスト RLHF」 (人間のフィードバックからのコンテキスト学習) と呼んでいます。
Nvidia の研究チームが Eureka の AI アルゴリズム ライブラリをオープンソース化したことは注目に値します。これにより、個人や機関は Nvidia Isaac Gym を通じてこれらのアルゴリズムを探索および実験できるようになります。 Isaac Gym は、Open USD フレームワークに基づいて 3D ツールとアプリケーションを作成するための開発フレームワークである Nvidia Omniverse プラットフォーム上に構築されています。

過去 10 年間、強化学習は大きな成功を収めてきましたが、依然として課題があることを認識しなければなりません。以前にも同様のテクノロジーを導入する試みはありましたが、報酬設計を支援する言語モデル (LLM) を使用する L2R (Learning to Reward) と比較して、タスク固有のプロンプトの必要性を排除する Eureka の方が注目されています。 Eureka が L2R よりも優れているのは、自由に表現された報酬アルゴリズムを作成し、背景情報として環境ソース コードを活用できることです。
NVIDIA の研究チームは、人間の報酬関数によるプライミングに何らかの利点があるかどうかを調査するために調査を実施しました。実験の目的は、元の人間の報酬関数を最初の Eureka 反復の出力でうまく置き換えられるかどうかを確認することです。
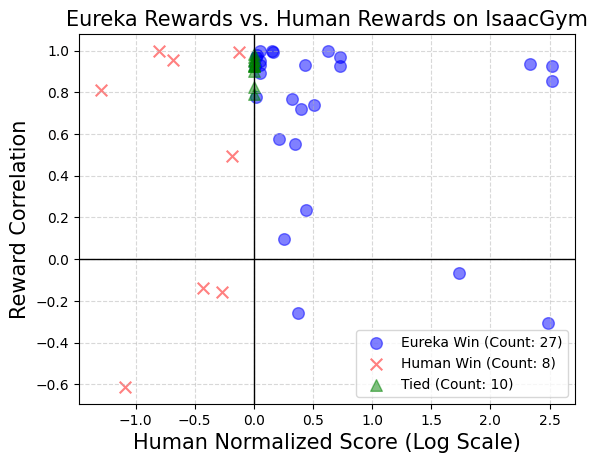
NVIDIA の研究チームは、テストで、各タスクのコンテキスト内のすべてのタスクに同じ強化学習アルゴリズムと同じハイパーパラメータを使用しました。報酬関数が最適化されます。これらのタスク固有のハイパーパラメータが、人為的に設計された報酬の有効性を確保するために適切に調整されているかどうかをテストするために、以前の研究に何の変更も加えずに基づいた、適切に調整された近接ポリシー最適化 (PPO) 実装が採用されました。研究者らは報酬ごとに 5 回の独立した PPO トレーニングを実施し、報酬パフォーマンスの尺度としてポリシー チェックポイントで到達した最大タスク メトリック値の平均を報告しました。
結果は、人間の設計者は多くの場合、関連する状態変数を十分に理解しているものの、効果的な報酬を設計する際には一定の熟練度が不足している可能性があることを示しています。
Nvidia によるこの画期的な研究は、強化学習と報酬設計の新たな境地を開きます。彼らの普遍的な報酬設計アルゴリズムである Eureka は、大規模な言語モデルと文脈進化的探索の力を利用して、タスク固有のプロンプトや人間の介入を必要とせずに、ロボットのタスク領域の広範囲にわたって人間レベルの報酬を生成し、人間のロボットに対する理解を大きく変えます。 AIと機械学習。
以上がロボットはペンを回したり、クルミを皿に盛り付けたりすることを学びました。 GPT-4 の祝福、タスクが複雑であればあるほど、パフォーマンスが向上しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



