


近年、大規模言語モデル (LLM) とその基盤となるトランスフォーマー アーキテクチャが会話型 AI の基礎となり、さまざまな消費者向けおよび企業向けアプリケーションを生み出してきました。かなりの進歩にもかかわらず、LLM で使用される固定長のコンテキスト ウィンドウは、長い会話や長い文書の推論への適用性を大幅に制限します。最も広く使用されているオープンソース LLM であっても、その最大入力長では、数十のメッセージ応答または短いドキュメント推論しかサポートできません。
同時に、トランスフォーマー アーキテクチャのセルフ アテンション メカニズムによって制限されるため、トランスフォーマーのコンテキスト長を単純に拡張すると、計算時間とメモリ コストが指数関数的に増加し、新しい長いコンテキストが作成されます。建築緊急の研究テーマ。
ただし、たとえコンテキスト スケーリングの計算上の課題を克服できたとしても、長いコンテキスト モデルでは追加のコンテキストを効果的に利用するのが難しいことが最近の研究で示されています。
これを解決するにはどうすればよいですか? SOTA LLM のトレーニングに必要な膨大なリソースと、コンテキスト スケーリングの利益が明らかに減少していることを考慮すると、長いコンテキストをサポートする代替手法が緊急に必要です。カリフォルニア大学バークレー校の研究者らは、この点で新たな進歩を遂げた。
この記事では、研究者は、固定コンテキスト モデルを使用し続けながら、無限のコンテキストの錯覚を提供する方法を検討します。彼らのアプローチは仮想メモリ ページングからアイデアを取り入れており、アプリケーションが利用可能なメモリをはるかに超えるデータ セットを処理できるようにします。
このアイデアに基づいて、研究者は LLM エージェント関数呼び出し機能の最新の進歩を利用して、仮想コンテキスト管理のための OS からインスピレーションを得た LLM システムである MemGPT を設計しました。

紙のホームページ: https://memgpt.ai/
arXiv アドレス: https://arxiv.org/pdf/2310.08560.pdf
このプロジェクトはオープンソース化されており、GitHub で 1.7,000 個のスターを獲得しています。
GitHub アドレス: https://github.com/cpacker/MemGPT
メソッドの概要
この研究は、コンテキスト ウィンドウ (オペレーティング システムの「メイン メモリ」に似ています) と外部ストレージの間で情報を効率的に「ページング」するために、従来のオペレーティング システムの階層メモリ管理からインスピレーションを得ています。 MemGPT は、メモリ、LLM 処理モジュール、ユーザー間の制御フローの管理を担当します。この設計により、単一タスク中にコンテキストを繰り返し変更できるため、エージェントは限られたコンテキスト ウィンドウをより効率的に利用できるようになります。
MemGPT は、コンテキスト ウィンドウを制限されたメモリ リソースとして扱い、従来のオペレーティング システムの階層メモリと同様の LLM の階層構造を設計します (Patterson et al.、1988)。より長いコンテキスト長を提供するために、この研究により、LLM は「LLM OS」 (MemGPT) を通じてコンテキスト ウィンドウに配置されたコンテンツを管理できるようになります。 MemGPT を使用すると、オペレーティング システムのページ フォールトと同様に、コンテキスト内で失われた関連する履歴データを LLM が取得できるようになります。さらに、プロセスが仮想メモリに繰り返しアクセスできるのと同じように、エージェントは単一のタスク コンテキスト ウィンドウの内容を繰り返し変更できます。
MemGPT を使用すると、コンテキスト ウィンドウが制限されている場合に、LLM が無制限のコンテキストを処理できるようになります。MemGPT のコンポーネントを以下の図 1 に示します。
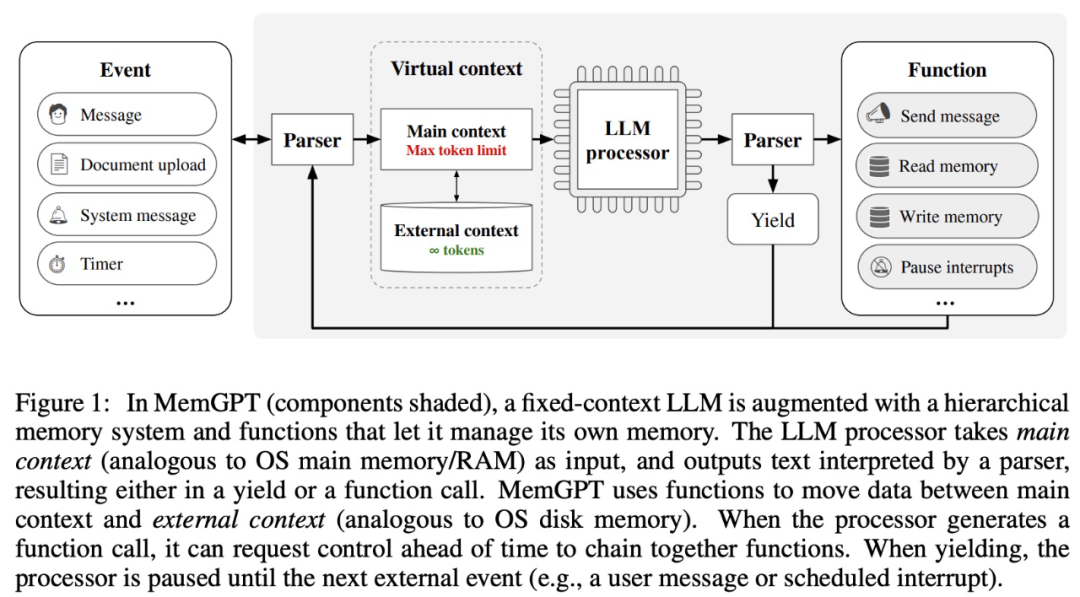
MemGPT は、関数呼び出しを通じてメイン コンテキスト (コンテキスト ウィンドウ内のコンテンツ) と外部コンテキストの間のデータの移動を調整し、現在のコンテキストに基づいて自律的に更新および取得します。


以下の図 3 に示すように、コンテキスト ウィンドウは制限を識別するために警告トークンを使用する必要があることに注意してください。

実験と結果
実験部分では、研究者らは、会話エージェントと文書処理という 2 つの長いコンテキスト ドメインで MemGPT を評価しました。会話型エージェントについては、既存のマルチセッション チャット データセット (Xu et al. (2021)) を拡張し、長い会話で知識を保持するエージェントの能力を評価する 2 つの新しい会話タスクを導入しました。文書分析については、質問応答や長い文書のキーと値の取得など、Liu et al. (2023a) によって提案されたタスクで MemGPT のベンチマークを行っています。
会話エージェント用の MemGPT
ユーザーと会話するとき、エージェントは次の 2 つの重要な基準を満たしている必要があります。
1 つ目は一貫性です。つまり、エージェントは会話の継続性を維持し、提供される新しい事実、参照、イベントはユーザーの以前の発言と一致している必要があります。そしてエージェント。
2 つ目は参加です。つまり、エージェントはユーザーの長期的な知識を利用して応答をパーソナライズする必要があります。以前の会話を参照すると、会話がより自然で魅力的なものになります。
したがって、研究者らは次の 2 つの基準に基づいて MemGPT を評価しました:
MemGPT はそのメモリを活用して会話の一貫性を向上させることができますか?一貫性を維持するために、過去のやりとりから関連する事実、引用、出来事を思い出すことができますか?
MemGPT メモリを使用して、より魅力的な会話を生成することは可能でしょうか?リモート ユーザー情報を自発的にマージして情報をパーソナライズしますか?
使用したデータセットに関して、研究者らは、MemGPT と、Xu et al. (2021) によって提案されたマルチセッション チャット (MSC) 上の固定コンテキスト ベースライン モデルを評価および比較しました。
まず一貫性の評価について説明します。研究者らは、会話型エージェントの一貫性をテストするために、MSC データセットに基づくディープ メモリ検索 (DMR) タスクを導入しました。 DMR では、ユーザーは会話型エージェントに質問をします。その質問は、回答範囲が非常に狭いことが予想されるため、以前の会話を明示的に参照しています。詳細については、以下の図 5 の例を参照してください。
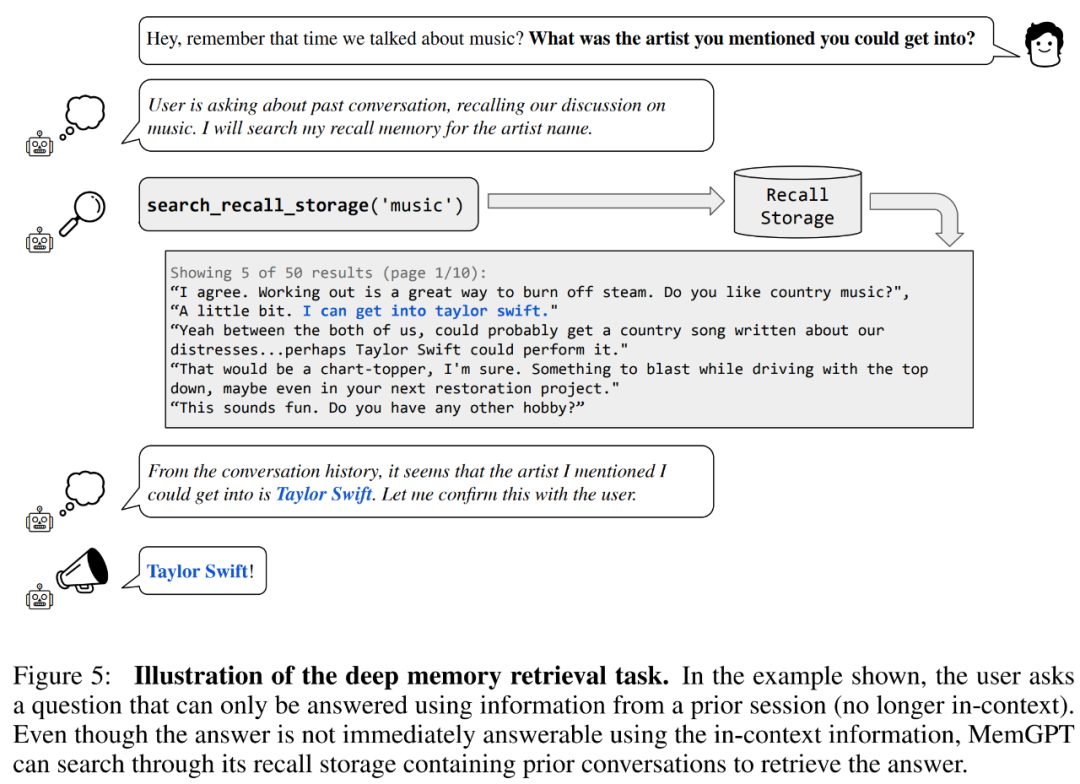
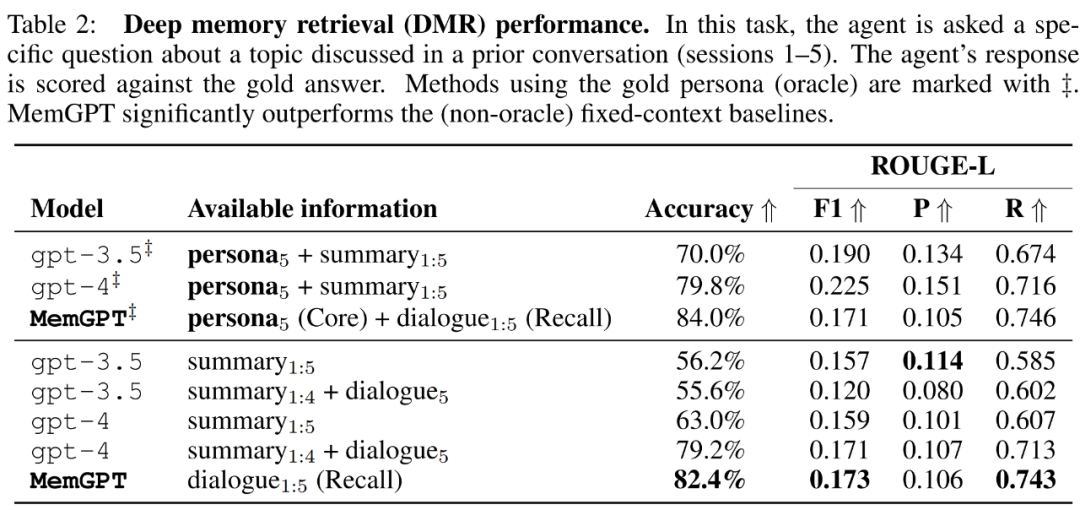
MemGPT はメモリを利用して一貫性を維持します。以下の表 2 は、GPT-3.5 や GPT-4 などの固定メモリ ベースライン モデルに対する MemGPT のパフォーマンスの比較を示しています。
LLM 判定精度と ROUGE-L スコアの点で、MemGPT は GPT-3.5 や GPT-4 に比べて大幅に優れていることがわかります。 MemGPT は、コンテキストを拡張するために再帰的な要約に依存するのではなく、Recall Memory を使用して過去の会話履歴をクエリし、DMR の質問に答えることができます。
次に、「会話スターター」タスクで、研究者は、以前の会話の蓄積された知識から魅力的なメッセージを抽出してユーザーに配信するエージェントの能力を評価しました。
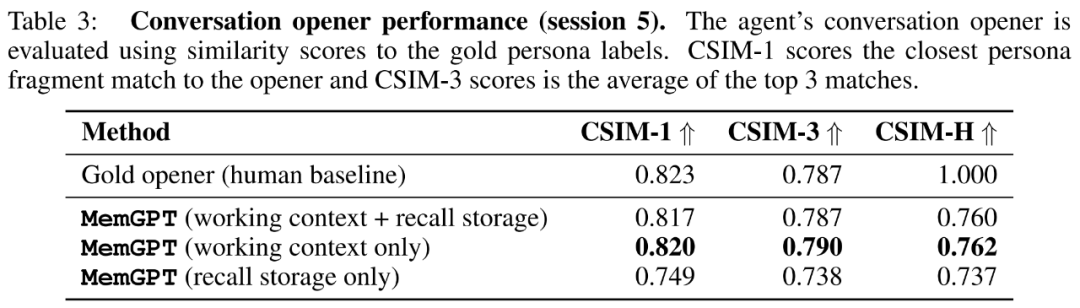
研究者らは、MemGPT の冒頭発言の CSIM スコアを以下の表 3 に示します。結果は、MemGPT が人間の手書きイントロと同等かそれ以上のパフォーマンスを発揮する魅力的なイントロを生成できることを示しています。また、MemGPT は人間のベースラインよりも長く、より多くの文字情報をカバーする開口部を生成する傾向があることも観察されています。以下の図 6 は一例です。

#文書分析用の MemGPT
MemGPT の文書分析能力を評価するために、ベンチマークを実施しました。 MemGPT と、Liu et al. (2023a) のレトリーバーリーダー文書 QA タスクに関する固定コンテキスト ベースライン モデル。 結果は、MemGPT がアーカイブ ストレージにクエリを実行することで、取得者への複数の呼び出しを効率的に行うことができ、有効なコンテキスト長をより大きくすることができることを示しています。 MemGPT は、アーカイブ ストアからドキュメントをアクティブに取得し、結果を反復的にページングできるため、利用可能なドキュメントの総数は、該当する LLM プロセッサ コンテキスト ウィンドウ内のドキュメント数によって制限されなくなります。 埋め込みベースの類似性検索には制限があるため、ドキュメントの QA タスクはすべての方法に大きな課題をもたらします。研究者は、クローラー データベースが使い果たされる前に、MemGPT がクローラー結果のページ分割を停止することを観察しました。 さらに、以下の図 7 に示すように、MemGPT のより複雑な操作によって作成される検索ドキュメントの容量にはトレードオフがあり、その平均精度は GPT-4 よりも低くなります (GPT-3.5 よりも高くなります)。 ) ですが、簡単に拡張することができます。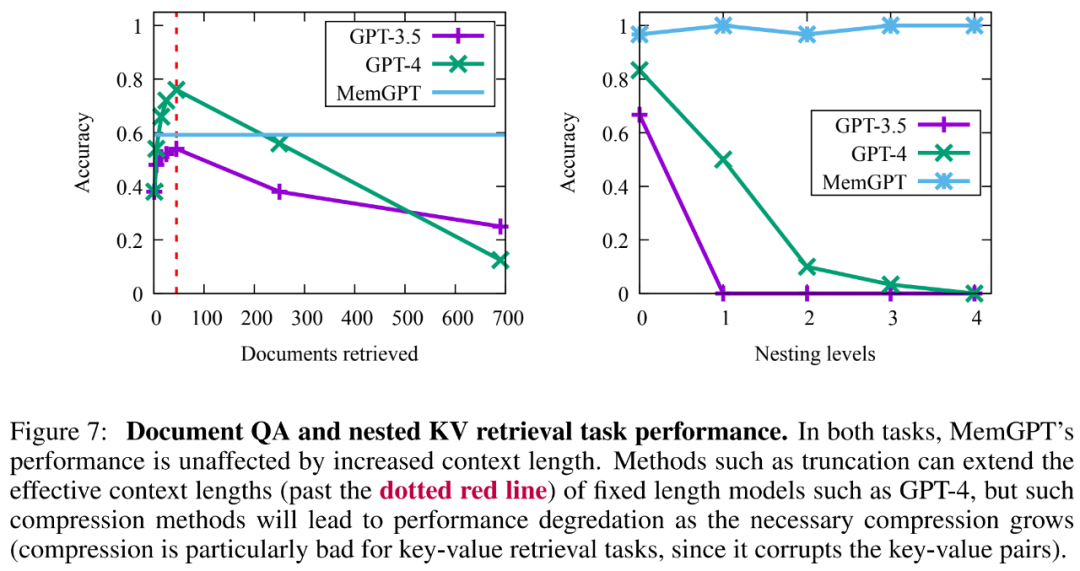
結果から、GPT-3.5 と GPT-4 は元のキーと値のタスクでは良好なパフォーマンスを示しましたが、ネストされたキーと値の取得タスクではパフォーマンスが低下しました。 MemGPT はネスト レベルの数の影響を受けず、関数クエリを通じてメイン メモリに格納されているキーと値のペアに繰り返しアクセスすることで、ネストされたルックアップを実行できます。
MemGPT のネストされたキーと値の取得タスクにおけるパフォーマンスは、複数のクエリを組み合わせて複数の検索を実行できることを示しています。
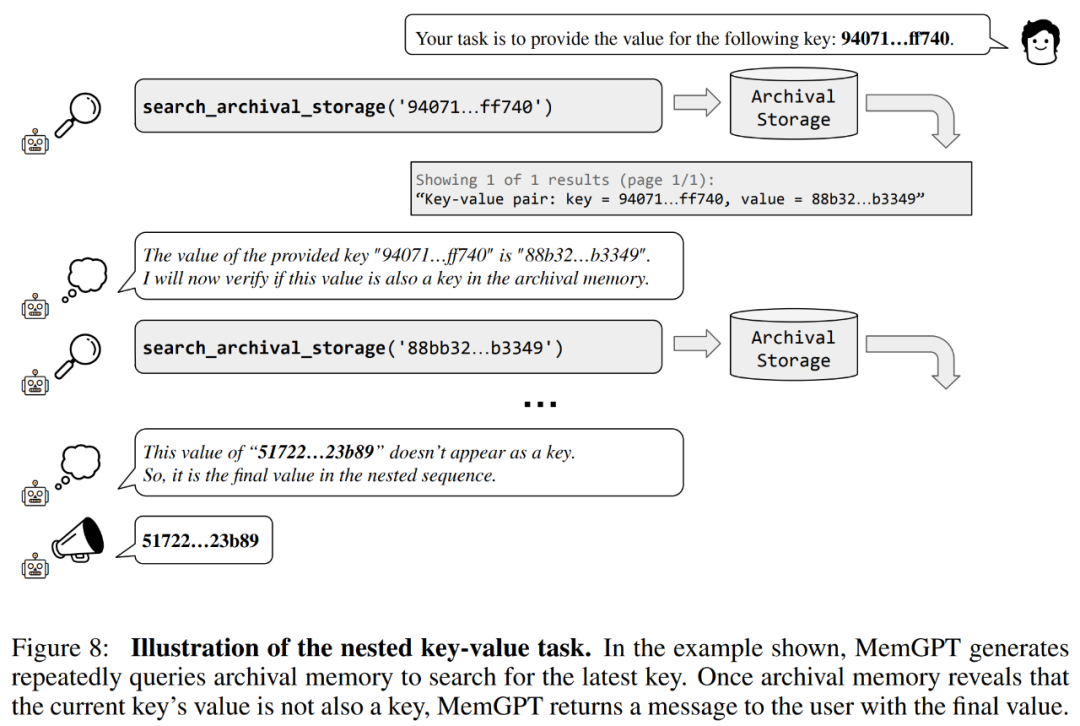
技術的な詳細と実験結果については、元の論文を参照してください。
以上がLLM をオペレーティング システムと考えてください。LLM には無制限の「仮想」コンテキストがあり、Berkeley の新作は 1.7,000 個の星を獲得していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



