


最近、Yuncong Technology の大規模モデルが視覚分野で再び重要な進歩を遂げました。視覚の基本的な大規模モデルに基づくターゲット検出器は、検出分野で設定された有名なベンチマーク COCO データで素晴らしい結果を達成しました。 Microsoft Research (MSR) と上海人工知能研究所、Zhiyuan Artificial Intelligence Research Institute、その他多くの有名な企業や研究機関が傑出し、新たな世界記録を樹立しました。


Yuncong Technology の COCO テスト セットにおける大規模モデルの平均精度 (以下、mAP、平均平均精度と呼びます) は 0.662 に達し、リストで 1 位にランクされました (下図を参照)。検証セットでは、単一スケールで 0.656 の mAP が達成され、マルチスケール TTA 後の mAP は 0.662 に達し、どちらも世界をリードするレベルに達しました。
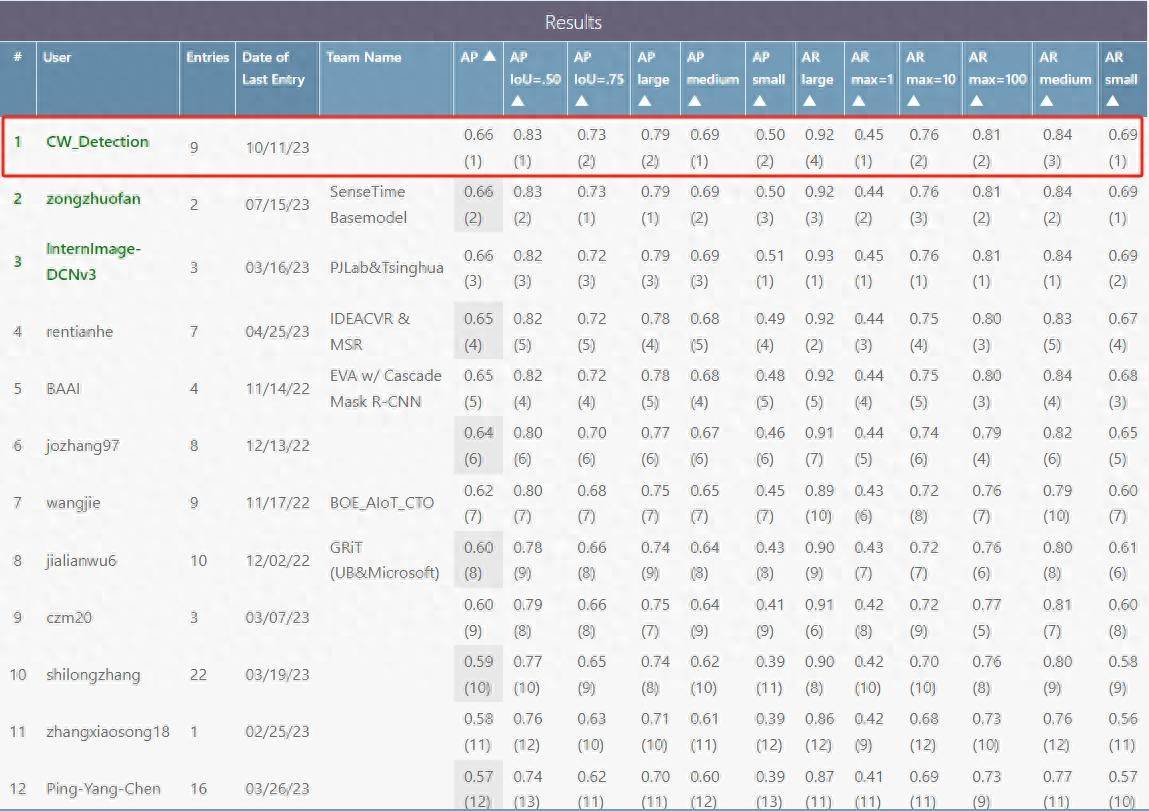
ビッグデータと自己教師あり学習を組み合わせてビジュアルコアテクノロジーを作成
GPTに代表されるビッグデータ自己教師あり事前学習は自然言語理解(NLP)分野で目覚ましい進歩を遂げており、視覚分野でもビッグデータと自己教師あり学習を組み合わせた基礎モデル学習も重要な進歩を遂げている。
一方で、幅広い視覚データは、モデルが共通の基本機能を学習するのに役立ちます。 YunCong Vision の大規模な基本モデルは、多数のラベルなしデータ セット、マルチモーダル画像およびテキスト データ セットを含む 20 億を超えるデータを使用します。データ セットの豊富さと多様性により、モデルは堅牢な特徴を抽出でき、大幅なコスト削減が可能になります。下流タスクの複雑さ、開発コスト。
一方、自己教師あり学習では手動によるアノテーションが不要なため、大量のラベルなしデータを使用してビジュアル モデルをトレーニングすることが可能になります。 Yunchong は自己教師あり学習アルゴリズムに多くの改良を加え、COCO 検出タスクでの良好な結果が示すように、検出やセグメンテーションなどのきめの細かいタスクにより適したものにしました。
オープンターゲット検出機能とゼロタイム学習検出機能により、研究開発コストが大幅に削減されます
ビジュアルベーシックモデルの優れたパフォーマンスのおかげで、Yuncong Rongrong の大規模モデルは、大規模な画像とテキストのマルチモーダル データに基づいてトレーニングされ、ゼロショット学習 (以下、ゼロショットと呼ばれる) 検出をサポートできます。エネルギー、輸送、製造、その他の業界をカバーする数千のカテゴリーのターゲット。
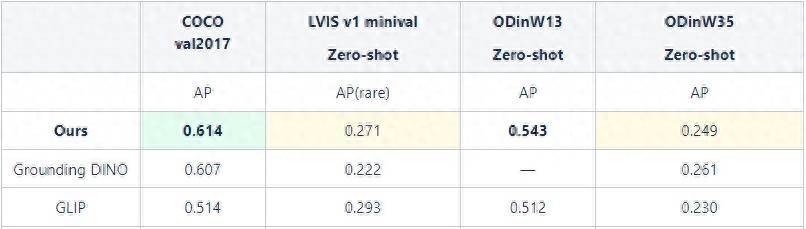 さまざまなデータセットに対する大規模モデルのゼロショット機能のパフォーマンス
さまざまなデータセットに対する大規模モデルのゼロショット機能のパフォーマンス
ゼロショットは人間の推論プロセスを模倣し、過去の知識を使用してコンピュータ内の新しいオブジェクトの特定の形式について推論することができ、コンピュータに新しいものを認識する能力を与えます。
ゼロショットを理解するにはどうすればよいですか?ロバと馬の形態的特徴がわかっていて、トラとハイエナが縞模様の動物、パンダとペンギンが白黒の動物であることもわかっているとします。シマウマは白と黒の縞模様を持つウマ科の動物であると定義します。シマウマの写真を見なくても、推測に頼るだけで、動物園のすべての動物の中からシマウマを見つけることができます。
Yunchong Vision の大規模な基本モデルは、強力な汎化パフォーマンスを示し、下流のタスクに必要なデータ依存性と開発コストを大幅に削減すると同時に、ゼロショットによりトレーニングと開発の効率が大幅に向上し、幅広いアプリケーションと迅速な導入を可能にします。可能。
以上がYunchong Technology の大規模モデルはベンチマーク COCO の世界記録を破り、AI アプリケーションのコストを大幅に削減の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



