


国内で自社開発された大型 AI モデルが再び大きな進歩をもたらしました。
10月16日のニュースによると、vivoは自社開発のAI大型モデルのマトリックスをリリースする予定です。これには、コアを完全にカバーする3つの異なるパラメータレベルを持つ5つの自社開発大型モデルが含まれます:十億、数百億、数千億アプリケーションシナリオ。 最新のデータによると、vivoの自社開発AI大型モデルはC-EvalとCMMLUの世界中国ランキングで第1位にランクされ、人文科学、社会科学などの分野でのパフォーマンスは同レベルの大型モデルをはるかに上回っています。 。
C-Eval リストは、清華大学、上海交通大学、エディンバラ大学が共同で構築した中国語モデルの包括的な試験評価セットで、52 の異なる分野をカバーし、合計 13,948 の多肢選択問題があります。現在、中国語モデルの最も包括的なテスト評価セットであり、権威ある中国語 AI 大型モデル評価リストです。 CMMLU データ セットは、MBZUAI、上海交通大学、マイクロソフト リサーチ アジアが共同で立ち上げた包括的な中国語評価ベンチマークであり、中国語の文脈における言語モデルの知識と推論能力を評価する上で非常に権威があります。
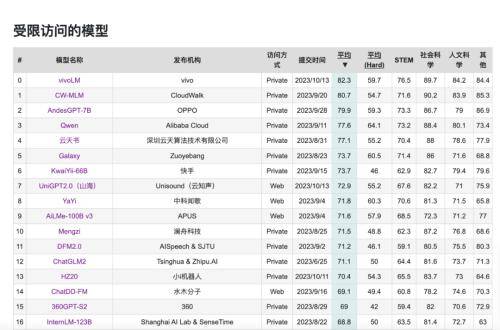
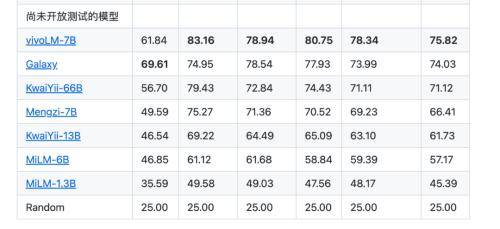
関連担当者によると、vivo が自社開発した AI 大型モデルは、次期 OriginOS 4 システムで初めて使用され、消費者によりインテリジェントで便利、安全な携帯電話体験をもたらします。
現在、AI ラージモデル技術は急速に発展しており、社会生産やライフスタイルの破壊的な変化を促進しており、携帯電話業界においても、メーカーにとって製品のイテレーションを加速し、ブルーオーシャントラックを開拓する重要な機会となることが期待されています。 。今回、vivoは自社開発のAI大型モデルマトリックスを作成し、それを新システムに適用し、大型モデルの探索が技術研究開発段階から応用・産業レイアウト段階に進んだことを証明し、効果的に推進するだけでなく、 vivo 自身のビジネスの成長とハイエンド戦略の導入は、業界全体に非常にプラスの推進効果をもたらします。
出典: オブザーバーネットワーク
以上が初め! Vivoの自社開発AI大型モデルがC-EvalとCMMLUで1位にランクインの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



