



書き直す必要があるコンテンツは次のとおりです: Editor|Ziluo
過去数年間、さまざまな異なるデータセットを使用してトレーニングすることにより、視覚的で自然な言語処理のための機械学習 (NLP) の分野は目覚ましい進歩を遂げました。これにより、NLP のルネッサンスのきっかけとなった「大規模言語モデル」などの「基本モデル」の出現につながり、特化したモデルをゼロからトレーニングするのではなく、汎用モデルの微調整やプロンプトを行うことが現在では標準的な手法となっています。
しかし、科学データセットへの機械学習の適用には、同様のパラダイムシフトがまだ起こっていません。
これは、「Polymathic AI」(Polymathic AI) 研究プログラムが対処しようとしている、実現されていない機会です。
チューリング賞受賞者であり、Meta の主任科学者であるヤン・ルカン氏は、「新しい AI for Science プロジェクト (Polymathic AI) のコンサルタントになれることをとてもうれしく思います。」と述べました。
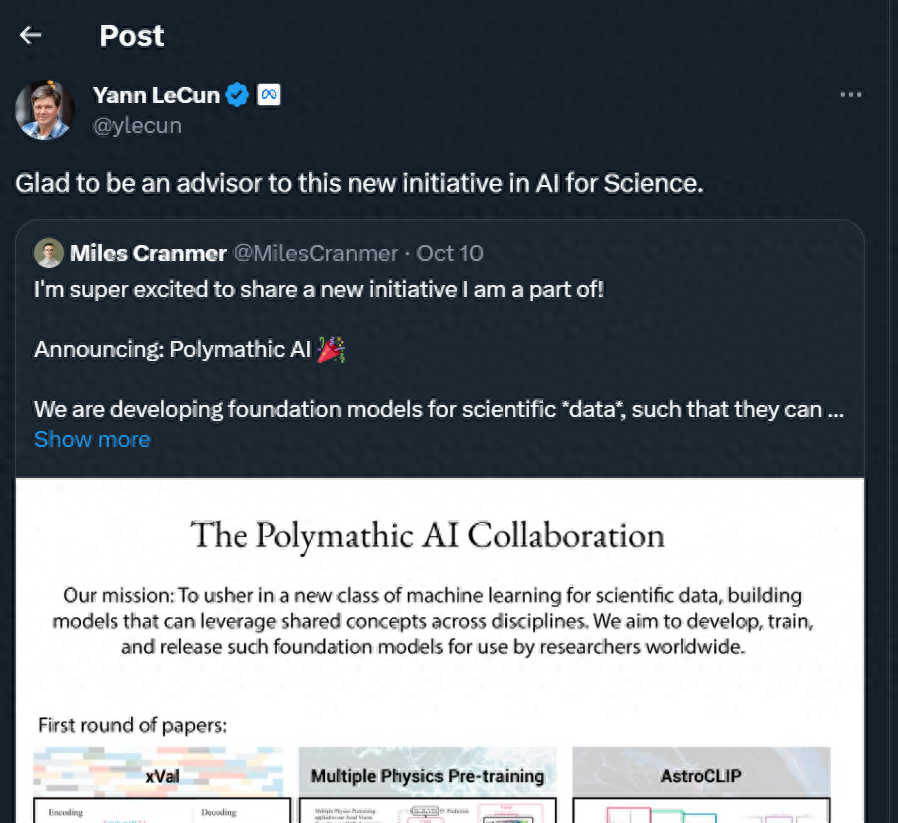 ケンブリッジ大学 AI 天文学/物理学の助教授、マイルズ クランマー氏は、自身が携わっている新しいプロジェクト、Polymathic AI! を Twitter で共有しました。
ケンブリッジ大学 AI 天文学/物理学の助教授、マイルズ クランマー氏は、自身が携わっている新しいプロジェクト、Polymathic AI! を Twitter で共有しました。
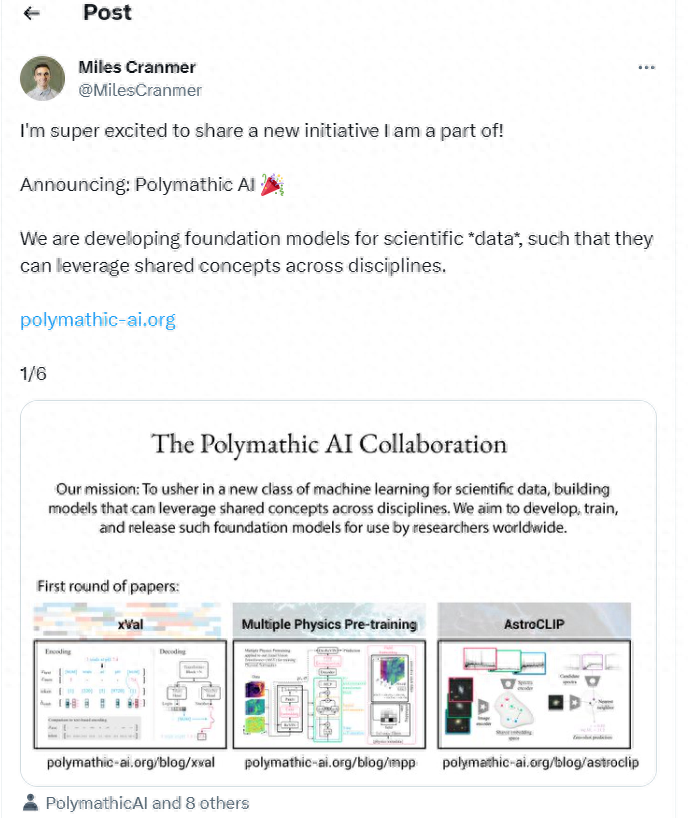
「私たちは科学[データ]の基本モデルを開発しており、分野を超えて共通の概念を活用できるようにしています。」
 ネチズンは次のように述べています。 「すごいです! 楽しそうです! この研究は素晴らしいです...」科学機械学習タスクのカスタマイズの基本モデル
ネチズンは次のように述べています。 「すごいです! 楽しそうです! この研究は素晴らしいです...」科学機械学習タスクのカスタマイズの基本モデル
課題は、異種データセットやさまざまな科学分野からの情報を活用する人工知能モデルを構築することです。自然言語処理などの分野とは対照的に、これらのモデルは統一された表現 (つまり、テキスト) を共有しません。
研究チームから指導を受けてください。
 科学諮問グループ。
科学諮問グループ。
 次のように書き直しました: 機関の関与
次のように書き直しました: 機関の関与
真に科学に基づいたモデルを構築するには、大量の予備調査が必要です。私たちの研究プログラムは、この分野の基礎に焦点を当てています。これまでに、私たちは主要なアーキテクチャコンポーネントに関する研究を発表してきました。私たちの研究は、言語モデルを数値データに適応させ、さまざまな物理システムでトレーニングされたサロゲート モデルの転送可能性を実証し、マルチモーダルな科学データの共有埋め込みを学習するまで多岐にわたります。
この研究プログラムは、再定義するために重要です。その可能性については大きな興奮があります。 Polymathic AI は、この目標に向けた野心的な一歩を表しています。 
以下を参照してください: https ://polymathic-ai.org/blog/payment/https://polymathic-ai.org/https://twitter.com/MilesCranmer/status/1711429121220465037
以上がAI for Science の新しいオープンソース プロジェクト「Polymathic AI」、Yann LeCun がコンサルタントを務めるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

![PHP 実践開発入門: PHP クイック作成 [中小企業フォーラム]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



