


大規模な言語モデルはパフォーマンスに優れており、ゼロまたは数ショットのヒントで新しいタスクを解決できます。しかし、LLM はメモリ利用効率が低く、大量のコンピューティング リソースを必要とするため、実際のアプリケーション展開ではあまり実用的ではありません。たとえば、1,750 億個のパラメータを持つ言語モデル サービスを実行するには、少なくとも 350 GB のビデオ メモリが必要です。現在の最先端の言語モデルには 5,000 億を超えるパラメーターがあり、多くの研究チームにはそれらを実行するための十分なリソースがなく、実際のアプリケーションでの低遅延パフォーマンスを満たすことができません。
手動でラベル付けされたデータや、LLM で生成されたラベルを使用した蒸留を使用して、より小規模なタスク固有のモデルをトレーニングする研究もいくつかありますが、LLM と同等のパフォーマンスを達成するには、微調整と蒸留に大量のトレーニング データが必要です。 。
大規模モデルのリソース要件の問題を解決するために、ワシントン大学と Google は協力して、「ステップバイステップ蒸留」と呼ばれる新しい蒸留メカニズムを提案しました。段階的な蒸留により、蒸留されたモデルのサイズは元のモデルより小さくなりますが、パフォーマンスは向上し、微調整および蒸留プロセス中に必要なトレーニング データの量は少なくなります
 #論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2305.02301
#論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2305.02301
分配蒸留メカニズムは、LLM から予測理由を抽出します (理論的根拠 ) は、マルチタスク フレームワーク内で小規模モデルをトレーニングするための追加の監視情報として使用されます。
4 つの NLP ベンチマークの実験後、次のことがわかりました: 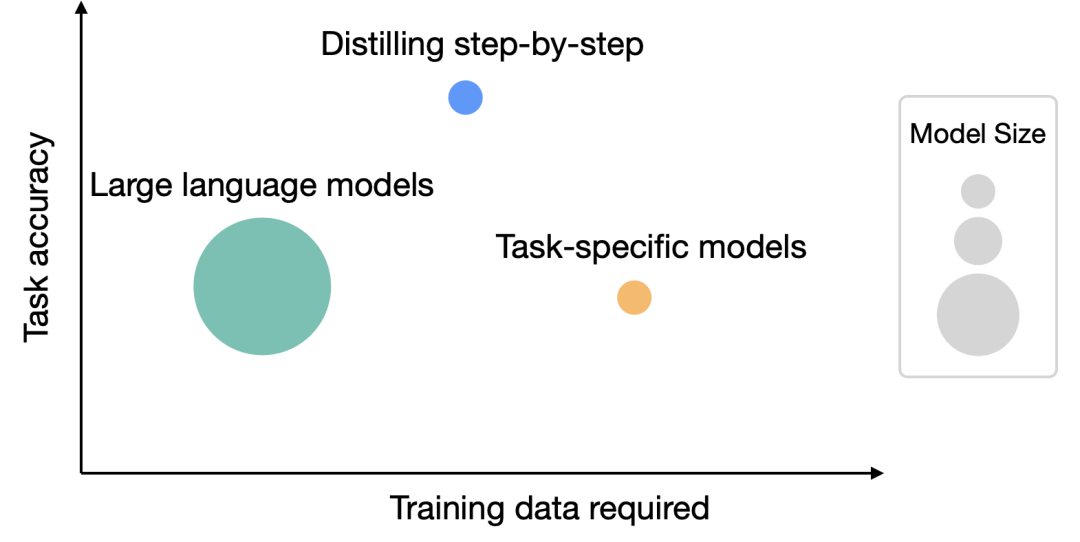
分配蒸留には主に 2 つの段階が含まれます: 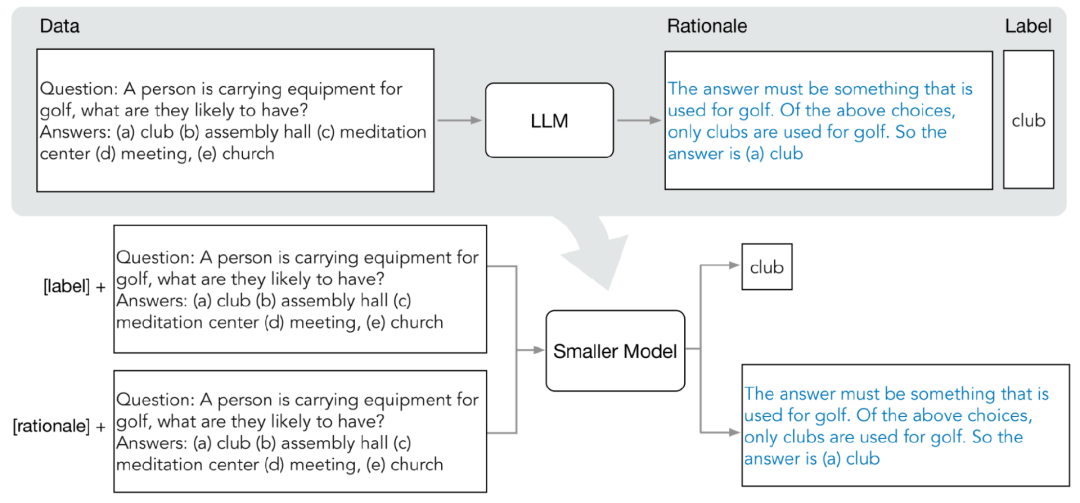
#研究者は、少数サンプルの思考連鎖 (CoT) プロンプトを使用して、LLM から予測中間ステップを抽出します。
対象タスクを決定したら、まず LLM 入力プロンプトでいくつかのサンプルを準備します。各例は、入力、原理、出力を含むトリプレットで構成されています。 プロンプトを入力した後、LLM はトリプレットのデモンストレーションを模倣して、他の新しい問題を生成できます。たとえば、予測原理などです。常識的な質問と回答のタスクで、 という入力質問が与えられた場合:
という入力質問が与えられた場合:
サミーは群衆が集まる場所に行きたいと考えています。彼はどこを選ぶでしょうか?オプションは次のとおりです: (a) 人口密集地域、(b) 競馬場、(c) 砂漠、(d) アパート、(e) 道路障害物
(サミーは人々がいる場所に行きたかった。彼はどこへ行くのでしょう? 回答の選択肢: (a) 人口密集地域、(b) 競馬場、(c) 砂漠、(d) アパート、(e) 道路封鎖)
段階的な改良の後、LLM あなたは「(a) 人口密集地」の設問に正解し、「答えは人の多い場所でなければなりません。上記の選択肢のうち、人が多いのは人口密集地だけです。」の設問にその理由を述べることができる。 徐々に改良を加えた結果、LLM は正解は「(a) 人口密集地域」であると結論付けることができ、質問の回答理由を「答えは多くの人が集まる場所でなければなりません。上記の選択肢のうち、人口密集地域のみです」と回答しました。たくさんの人がいます。「人。」
プロンプトで根拠と組み合わせた CoT 例を提供することにより、コンテキスト学習機能により、LLM は、遭遇していない質問タイプに対して適切な回答理由を生成できるようになります
2. トレーニング ミニ モデル
トレーニング プロセスをマルチタスク問題として構築することで、予測の理由を抽出し、トレーニング用の小規模モデルに組み込むことができます。
標準のラベル予測タスクに加えて、研究者らはまた、新しい理由生成タスクを使用して小規模モデルをトレーニングしました。これにより、モデルは予測のための中間推論ステップを生成する方法を学習し、結果ラベルをより適切に予測できるようにモデルをガイドできるようになりました。
入力プロンプトにタスクのプレフィックス「label」と「rationale」を追加して、ラベル予測タスクと理由生成タスクを区別します。
実験では、研究者らはLLMベースラインとして5,400億個のパラメータを持つPaLMモデルを選択し、タスク関連の下流小規模モデルとしてT5モデルを使用しました。
この研究では、自然言語推論用の e-SNLI と ANLI、常識的な質問応答用の CQA、および算術数学のアプリケーション問題用の SVAMP という 4 つのベンチマーク データセットで実験を実施しました。これら 3 つの異なる NLP タスクについて実験を行いました。
トレーニング データが少ない
段階的蒸留法の方が、標準の微調整よりもパフォーマンスが高く、必要なトレーニング データが少なくなります
e-SNLI データセットでは、完全なデータセットの 12.5% を使用したときに標準の微調整よりも優れたパフォーマンスが達成されますが、ANLI では、わずか 75%、25%、および 20% を使用した場合に達成されます。トレーニング データは CQA と SVAMP でそれぞれ必要です。
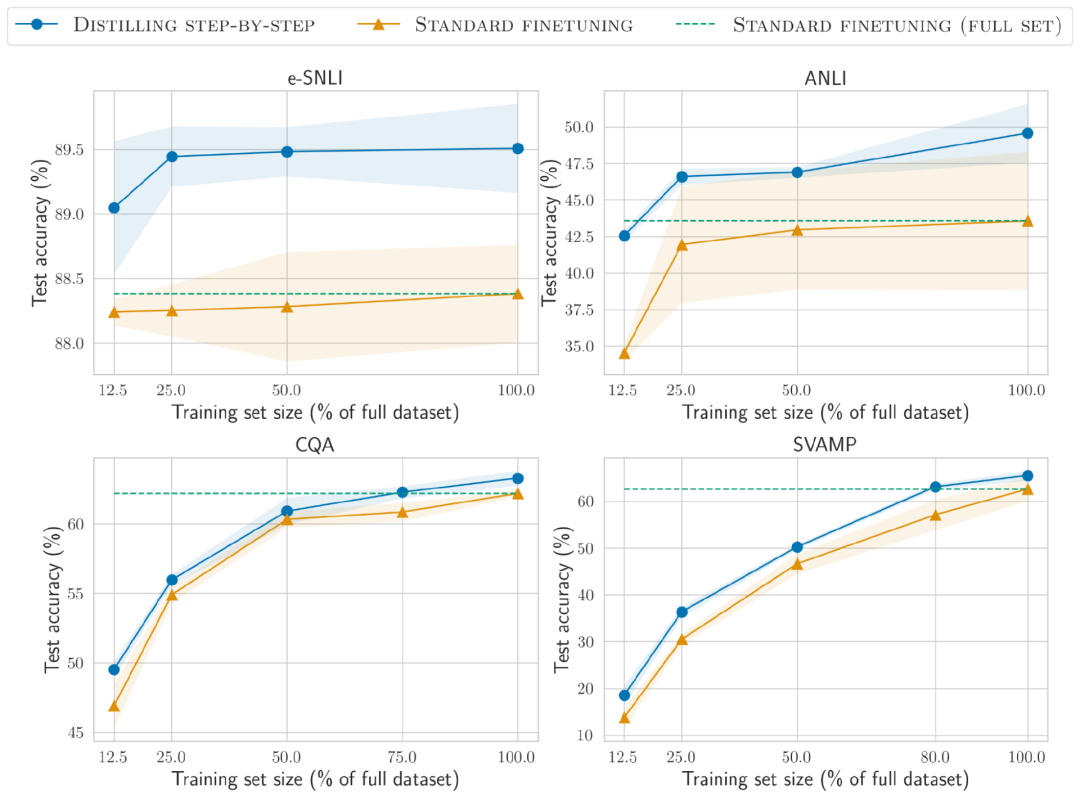
手動でラベル付けされたさまざまなサイズのデータセットに対して 220M T5 モデルを使用した標準的な微調整と比較して、すべてのデータセットで使用するトレーニング サンプルの数が少ない場合、分布の抽出が優れています。少数ショットの CoT 蒸留によって LLM を実行すると、サイズははるかに小さくなりますが、パフォーマンスは向上します。
e-SNLI データ セットでは、220M T5 モデルを使用すると 540B PaLM よりも優れたパフォーマンスが得られます。ANLI では、770M T5 モデルを使用すると、540B PaLM よりも優れたパフォーマンスが得られます。モデル サイズはわずか 1/700 #より小さなモデル、より少ないデータ
モデルのサイズとトレーニング データを削減しながら、数ショット PaLM# を超えるパフォーマンスを達成することに成功しました。 ## ANLI では、データセット全体の 80% のみを使用しながら、770M T5 モデルを使用して 540B PaLM を上回りました
##標準的な微調整では、完全な 100% データセットでも PaLM のパフォーマンス レベルを維持できます。これは、段階的な蒸留によってモデル サイズとトレーニング データの量を同時に削減できるため、LLM を超えるパフォーマンスを達成できることを示しています。
以上がパラメータ数は7億7千万、5,400億PaLMを突破! UW Google、トレーニング データの 80% のみが必要な「段階的蒸留」を提案 | ACL 2023の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



