



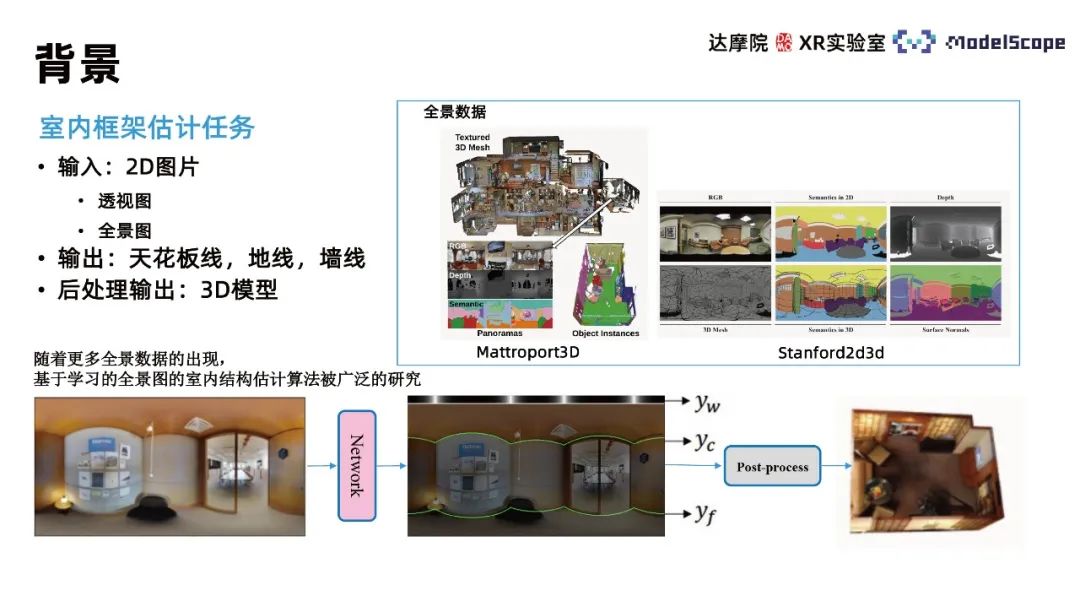
この手法は主に屋内推定レイアウト推定タスクに焦点を当てており、タスクは 2D 画像を入力します。 . 、画像によって記述されたシーンの 3 次元モデルを出力します。 3D モデルを直接出力する複雑さを考慮すると、この作業は一般に、2D 画像内の壁線、天井線、地面線の 3 つの線の情報を出力し、その後、事後処理を通じて部屋の 3D モデルを再構成することに分解されます。回線情報に基づいて演算を処理します。 3 次元モデルは、後の段階で屋内シーンの再現や VR ハウスの閲覧などの特定のアプリケーション シナリオでさらに使用できます。この方法は、奥行き推定法とは異なり、屋内の壁の線の推定に基づいて空間幾何構造を復元するため、壁の幾何構造をより平坦にできることが利点ですが、詳細な幾何情報を復元できないことが欠点です。屋内シーンのソファや椅子などのアイテム。
入力画像に応じて、パースベースの方法とパノラマベースの方法に分けられます。パース ビューと比較して、パノラマは視野角が広く、画像情報が豊富です。パノラマ取得機器の普及に伴い、パノラマデータがますます豊富になってきており、現在、パノラマ画像に基づく屋内フレーム推定アルゴリズムが多数研究されており、
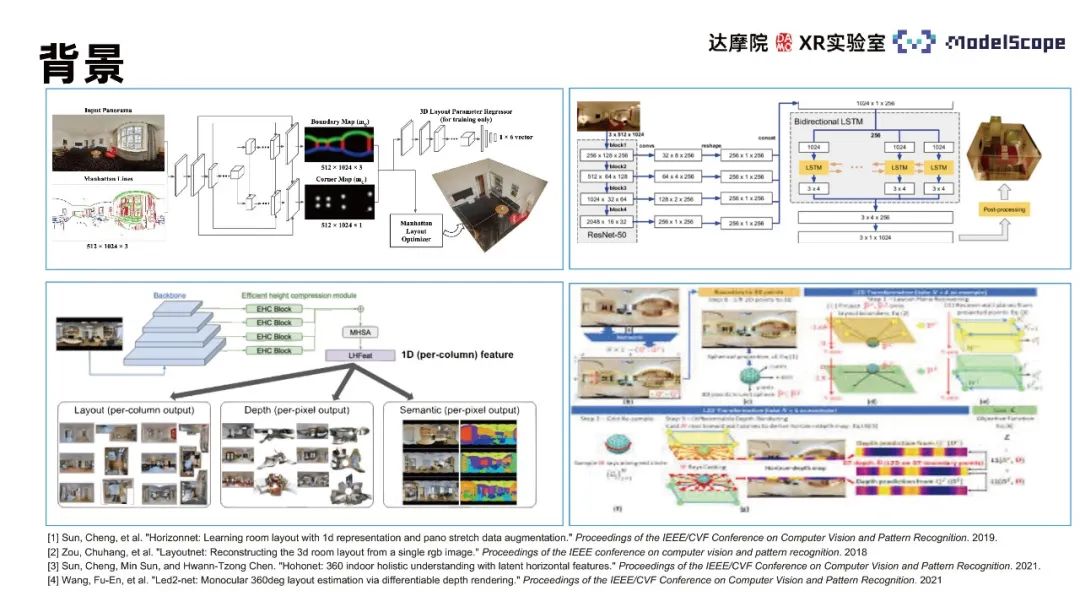
関連するアルゴリズムとしては、主に LayoutNet、HorizonNet、HohoNet、Led2-Net などが挙げられますが、これらの手法の多くは畳み込みニューラル ネットワークに基づいており、ノイズなどの複雑な構造がある場所では壁面予測効果が低くなります。干渉、自己閉塞など。不連続な壁線や不正確な壁線位置などの予測結果。壁線位置推定タスクでは、局所的な特徴情報のみに着目するとこのような誤差が生じるため、パノラマ内のグローバル情報を利用して壁線全体の位置分布を考慮して推定する必要があります。 CNN メソッドはローカルな特徴を抽出するタスクで優れたパフォーマンスを発揮し、Transformer メソッドはグローバルな情報をキャプチャすることに優れているため、Transformer メソッドを屋内フレーム推定タスクに適用してタスクのパフォーマンスを向上させることができます。
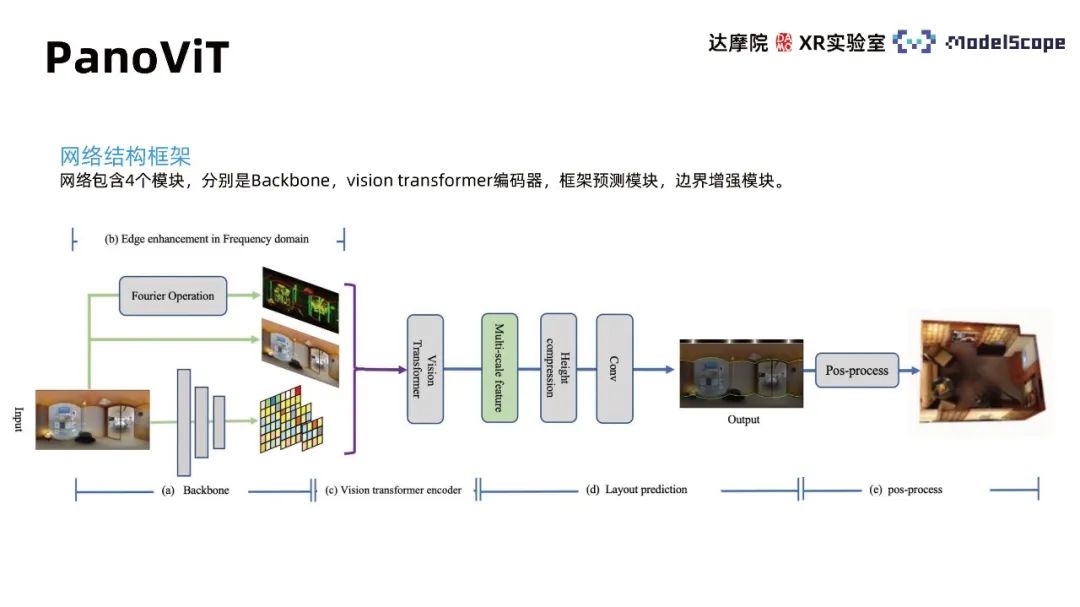
#トレーニング データの依存性により、パースペクティブの事前トレーニングのみに基づいて Transformer を適用してパノラマ屋内フレームを推定する効果は次のようになります。理想的ではありません。 PanoViT モデルは、事前にパノラマを特徴空間にマッピングし、Transformer を使用して特徴空間内のパノラマのグローバル情報を学習し、パノラマの見かけの構造情報を考慮して屋内フレーム推定タスクを完了します。

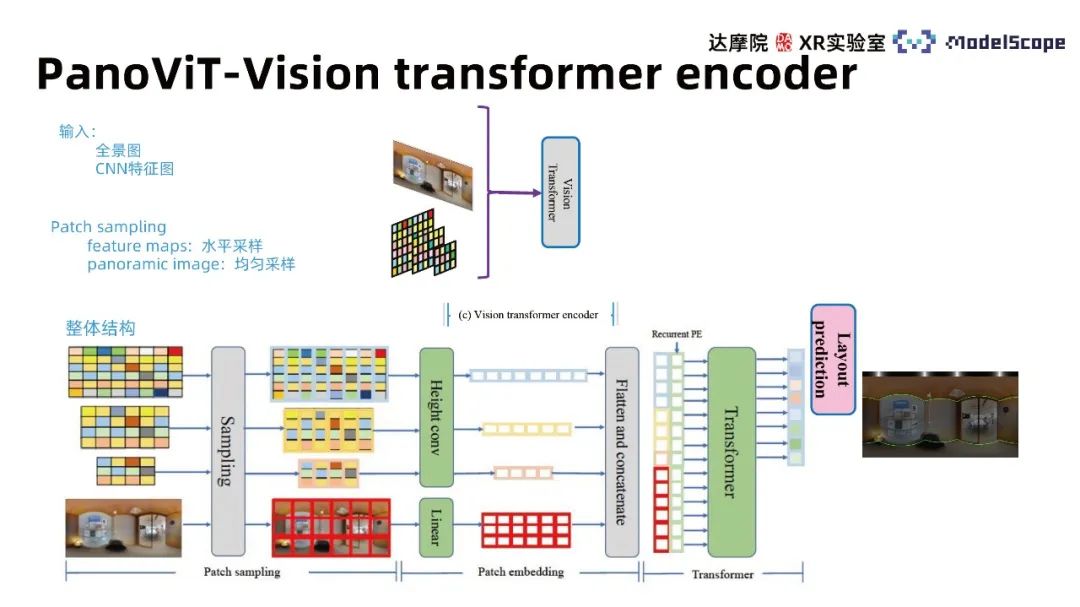
ネットワーク構造フレームワークには、バックボーン、ビジョン トランスフォーマー デコーダー、フレーム予測モジュール、境界強調モジュールの 4 つのモジュールが含まれています。バックボーン モジュールはパノラマを特徴空間にマッピングし、ビジョン トランスフォーマー エンコーダーは特徴空間内のグローバル相関を学習し、フレーム予測モジュールは特徴を壁線、天井線、地面線の情報に変換します。部屋とその境界の 3 次元モデル拡張モジュールは、屋内フレーム推定におけるパノラマ画像内の境界情報の役割を強調します。
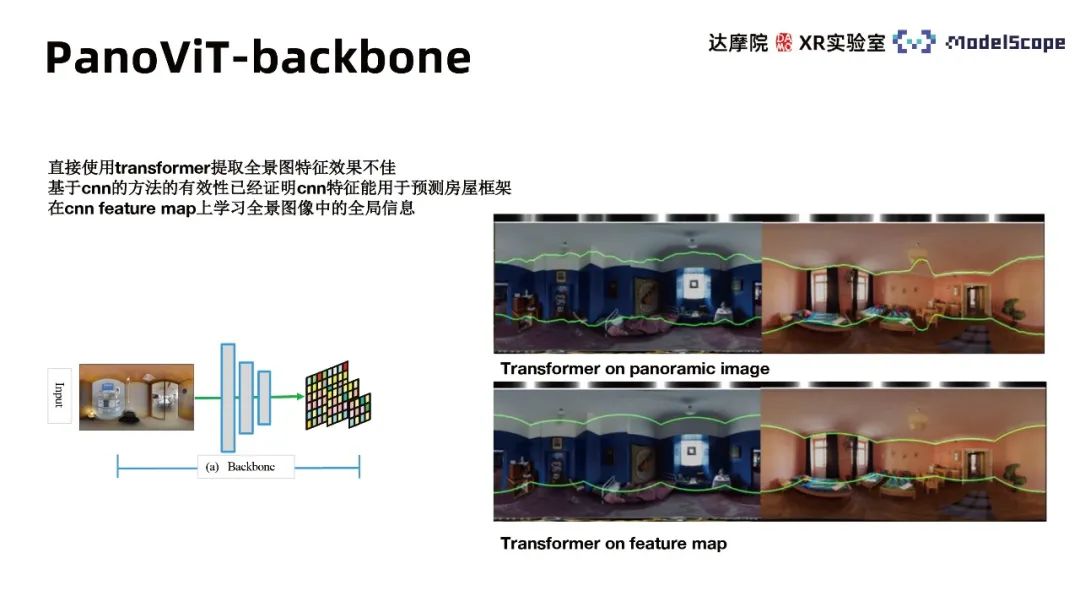
トランスを直接使用してパノラマ特徴を抽出することは効果的ではないため、 CNN ベースの手法が有効です 有効性、つまり、CNN の特徴を使用して住宅フレームを予測できます。したがって、CNN のバックボーンを使用して、パノラマのさまざまなスケールの特徴マップを抽出し、特徴マップ内のパノラマ画像のグローバル情報を学習します。実験結果は、特徴空間でトランスフォーマーを使用する方が、パノラマに直接適用するよりも大幅に優れていることを示しています
Transformer の主要なアーキテクチャは、パッチ サンプリング、パッチ エンベディング、Transformer のマルチヘッド アテンションを含む 3 つのモジュールに主に分割できます。入力では、パノラマ画像の特徴マップと元の画像の両方が考慮され、入力ごとに異なるパッチ サンプリング方法が使用されます。元の画像は均一サンプリング法を使用し、特徴マップは水平サンプリング法を使用します。 HorizonNet の結論では、壁線推定タスクでは水平方向の特徴がより重要であると考えられており、この結論を参照すると、特徴マップの特徴は埋め込みプロセス中に垂直方向に圧縮されます。 Recurrent PE 法を使用して、異なるスケールの特徴を結合し、多頭注意のトランス モデルで学習して、元の画像の水平方向と同じ長さの特徴ベクトルを取得します。異なるデコーダヘッド。
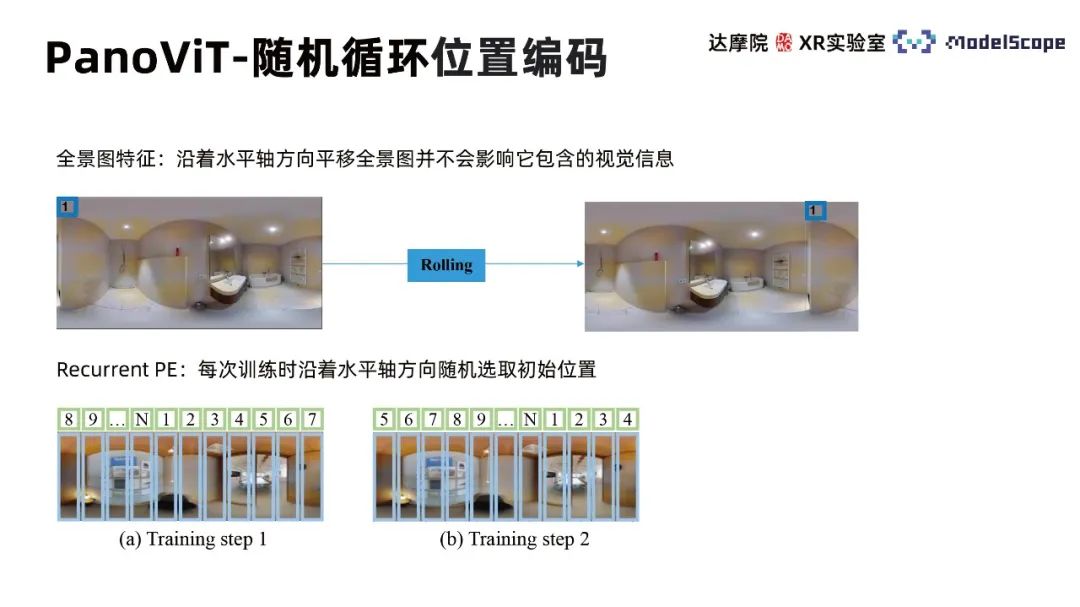
ランダム循環位置エンコーディング (反復位置埋め込み) では、水平方向に沿ったパノラマの変位によってパノラマの特性が変化しないことが考慮されています。画像の視覚情報を利用するため、各トレーニングでは初期位置が水平軸に沿ってランダムに選択されるため、トレーニング プロセスでは絶対位置ではなく、異なるパッチ間の相対位置に注意が払われます。
パノラマの幾何情報を最大限に活用することで、屋内フレーム推定タスクのパフォーマンス向上に貢献します。 PanoViT モデルの境界強化モジュールは、パノラマ内の境界情報の使用方法を強調し、3D 損失はパノラマの歪みの影響を軽減するのに役立ちます。
境界強調モジュールは、壁線検出タスクにおいて壁線の線形特性を考慮します。画像内の線情報は非常に重要であるため、強調表示する必要があります。ネットワークが画像の中心線の分布を理解できるようにするための境界情報。周波数領域で境界強調手法を使用してパノラマの境界情報を強調表示し、高速フーリエ変換に基づいて画像の周波数領域表現を取得し、マスクを使用して周波数領域空間でサンプリングし、強調表示された境界を持つ画像に変換し直します。逆フーリエ変換に基づく情報。モジュールの核心はマスク設計にあり、境界が高周波情報に対応することを考慮して、マスクは最初にハイパスフィルターを選択し、異なるラインの異なる方向に従って異なる周波数領域方向をサンプリングします。この方法は、従来の LSD 方法よりも実装が簡単で効率的です。 
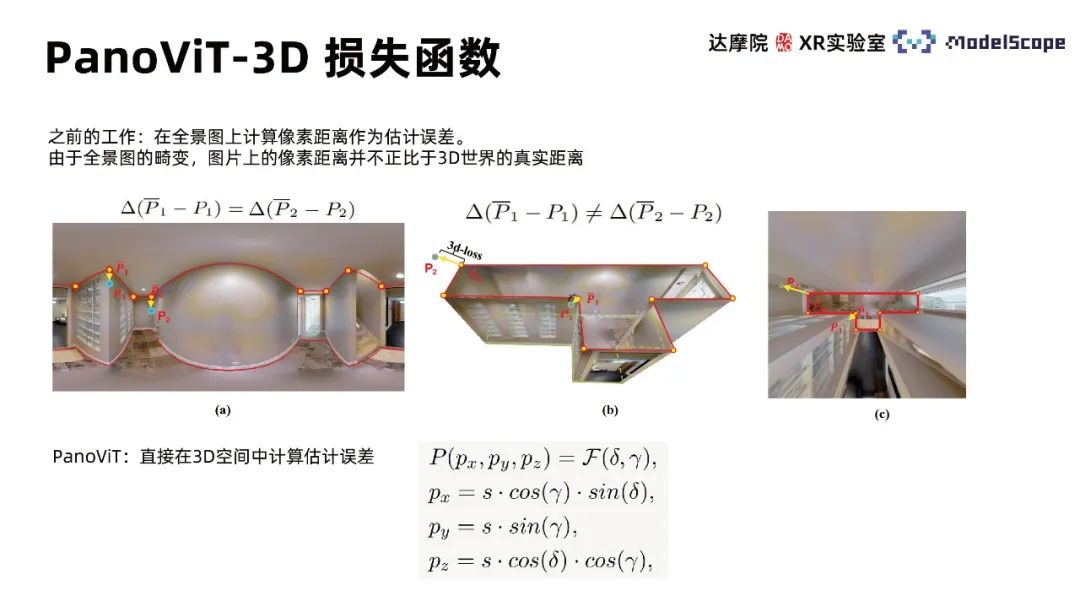
以前の作業では、パノラマ上のピクセル距離を推定誤差として計算していましたが、パノラマの歪みにより、画像上のピクセル距離は実際の距離に比例しませんでした。 3Dの世界で。 PanoViT は 3D 損失関数を使用して、3D 空間で推定誤差を直接計算します。
Martroport3D および PanoContext パブリック データ セットを使用して、評価指標として 2DIoU および 3DIoU を使用して実験を実施します。 SOTA手法との比較。結果は、2 つのデータセットに対する PanoViT のモデル評価インジケーターが基本的に最適レベルに達しており、特定のインジケーターに関しては LED2 よりわずかに劣っているだけであることを示しています。モデルの可視化結果を Hohonet と比較すると、PanoViT は複雑なシーンでも壁の線の方向を正確に識別できることがわかります。アブレーション実験で Recurrent PE、境界強化、および 3D Loss モジュールを比較することで、これらのモジュールの有効性を検証できます。
より優れたモデル データ セットを実現するために、100,000 枚を超える屋内パノラマ画像が収集され、さまざまな複雑な屋内シーンを含む自己構築パノラマ画像データ セットが構築され、カスタム ベースの注釈が付けられました。このルールから 5053 個の画像がテスト データ セットとして選択されました。 PanoViT モデルと SOTA モデル手法のパフォーマンスを、自身で構築したデータセットでテストしたところ、データ量が増加するにつれて、PanoViT モデルのパフォーマンスが大幅に向上することがわかりました。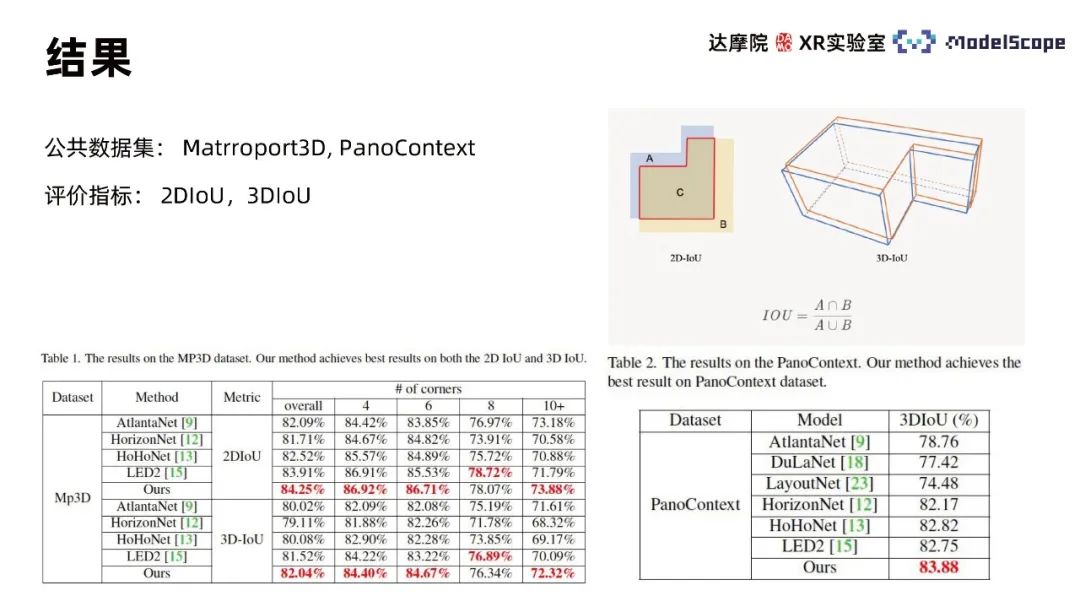

以上がパノラマ視覚自注目モデルを用いた屋内フレーム推定手法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



