


この記事は自動運転ハート公式アカウントの許可を得て転載しておりますので、転載については出典元にご連絡ください。
[RenderOcc、2D ラベルのみを使用してマルチビュー 3D 占有モデルをトレーニングするための最初の新しいパラダイム] 著者は、マルチビュー画像から NeRF スタイルの 3D ボリューム表現を抽出し、ボリューム レンダリング技術を使用して 2D 再構成を構築します。したがって、2D セマンティックおよび深度ラベルからの直接 3D 監視が可能になり、高価な 3D 占有アノテーションへの依存が軽減されます。広範な実験により、RenderOcc が 3D ラベルを使用した完全教師モデルと同等のパフォーマンスを発揮することが示されており、現実世界のアプリケーションにおけるこのアプローチの重要性が強調されています。すでにオープンソースです。
タイトル: RenderOcc: 2DRendering Supervision によるビジョン中心の 3D 占有予測
著者の所属: 北京大学、Xiaomi Automobile、Hong Kong Chinese MMLAB
必要なコンテンツ書き換えられた内容は次のとおりです。 オープンソースのアドレス: GitHub - pmj110119/RenderOcc
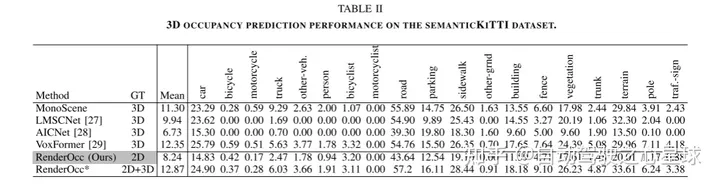
3D 占有予測は、3D シーンを意味ラベル付きのグリッド セルに定量化する、ロボットの認識と自動運転の分野で重要な可能性を秘めています。最近の研究では、主に 3D ボクセル空間内の完全な占有ラベルを監視に利用しています。ただし、高価な注釈プロセスと、場合によってはあいまいなラベルにより、3D 占有モデルの使いやすさと拡張性が大幅に制限されます。この問題を解決するために、著者らは、2D ラベルのみを使用して 3D 占有モデルをトレーニングするための新しいパラダイムである RenderOcc を提案します。具体的には、マルチビュー画像から NeRF スタイルの 3D ボリューム表現を抽出し、ボリューム レンダリング技術を使用して 2D 再構成を構築し、2D セマンティックおよび深度ラベルからの直接 3D 監視を可能にします。さらに、著者らは、自動運転シーンにおける視点のまばらさの問題を解決するために、連続フレームを利用して各ターゲットの包括的な 2D レンダリングを構築する補助光線法を導入しています。 RenderOcc は、2D ラベルのみを使用してマルチビュー 3D 占有モデルをトレーニングする初めての試みであり、高価な 3D 占有アノテーションへの依存を軽減します。広範な実験により、RenderOcc が 3D ラベルを使用した完全教師モデルと同等のパフォーマンスを発揮することが示されており、現実世界のアプリケーションにおけるこのアプローチの重要性が強調されています。
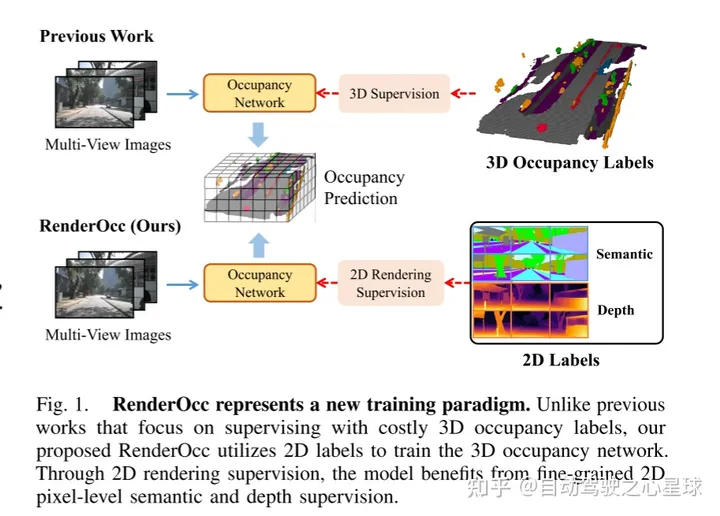
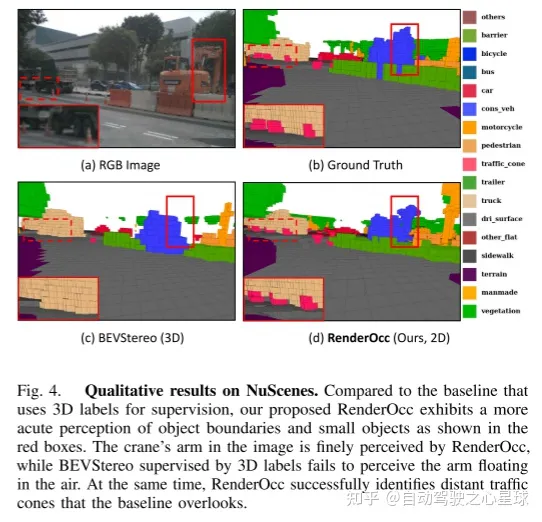
図 1 は、RenderOcc の新しいトレーニング方法を示しています。監視のために高価な 3D 占有ラベルに依存する以前の方法とは異なり、この論文で提案される RenderOcc は 2D ラベルを利用して 3D 占有ネットワークをトレーニングします。 2D レンダリング監視により、モデルはきめ細かい 2D ピクセルレベルのセマンティクスと深度監視の恩恵を受けることができます。
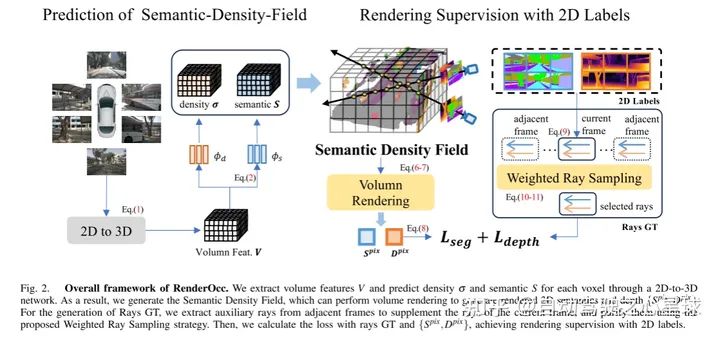
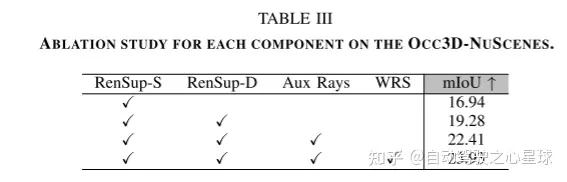
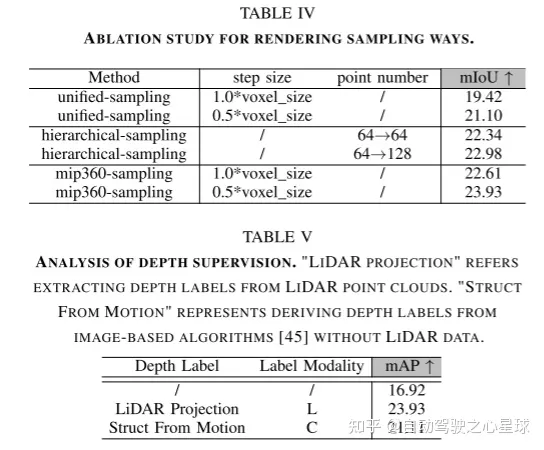
# 図 2. RenderOcc の全体的なフレームワーク。この論文では、2D から 3D へのネットワークを通じて体積特徴を抽出し、各ボクセルの密度とセマンティクスを予測します。したがって、この論文では、ボリューム レンダリングを実行して、レンダリングされた 2D セマンティクスと深度を生成できるセマンティック密度フィールドを生成します。 Rays GT の生成では、この論文では、隣接するフレームから補助光線を抽出して現在のフレームの光線を補完し、提案された重み付けされた光線サンプリング戦略を使用してそれらを純化します。次に、この記事では、ray GT と {} を使用して、2D ラベルのレンダリング監視を実現するための損失を計算します。
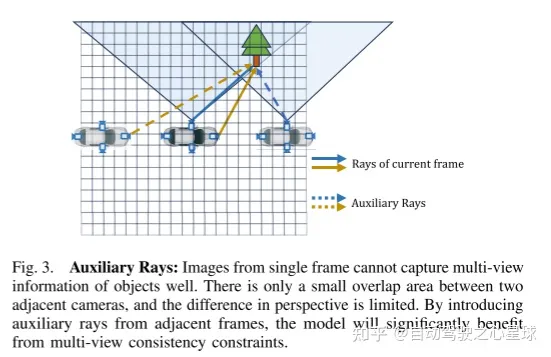
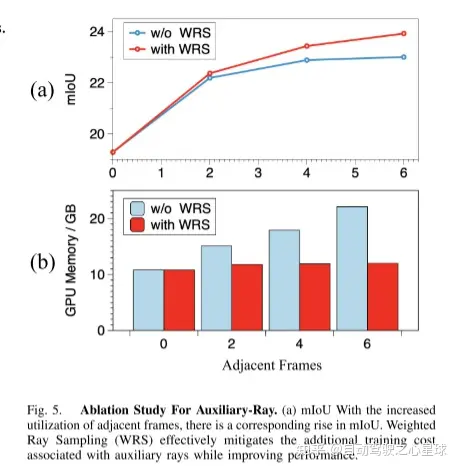
書き換えられた内容: 図 3。補助光: 単一フレームの画像では、オブジェクトの多視点情報をうまく捉えることができません。隣接するカメラ間の重なり合う領域はわずかであり、視野角の差は限られています。隣接するフレームから補助光線を導入することにより、モデルはマルチビューの一貫性制約から大きな恩恵を受けることができます。

書き直す必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/WzI8mGoIOTOdL8irXrbSPQ
以上が最初の記事: 2D ラベルのみを使用してマルチビュー 3D 占有モデルをトレーニングするための新しいパラダイムの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



