


Text-to-Image の分野は、ここ数年、特に人工知能生成コンテンツ (AIGC) の時代に大きな進歩を遂げました。 DALL-E モデルの台頭により、Imagen、Stable Diffusion、ControlNet およびその他のモデルなど、ますます多くの Text-to-Image モデルが学術コミュニティで登場しました。ただし、Text-to-Image 分野の急速な発展にも関わらず、既存のモデルは、テキストを含む画像を安定して生成するという点で依然としていくつかの課題に直面しています。
既存の Sota Vincent グラフ モデルを試した後、次のことが可能になります。 find を実行すると、モデルによって生成されたテキストは基本的に文字化けと同様に読めなくなり、画像全体の美しさに大きな影響を与えます。

既存の sota テキスト生成モデルによって生成されたテキスト情報は可読性が低いです
調査後、学術界ではこの分野に関する研究はほとんどありません。実際、ポスター、本の表紙、道路標識など、テキストを含む画像は日常生活で非常に一般的です。 AI がそのような画像を効果的に生成できれば、デザイナーの作業を支援し、デザインのインスピレーションを刺激し、デザインの負担を軽減するのに役立ちます。さらに、ユーザーは、Vincent 図モデルの結果のテキスト部分のみを変更し、他の非テキスト領域の結果を保持したい場合もあります。
元の意味を変えないように、内容を中国語に書き直す必要があります。元の文は必須ではありません

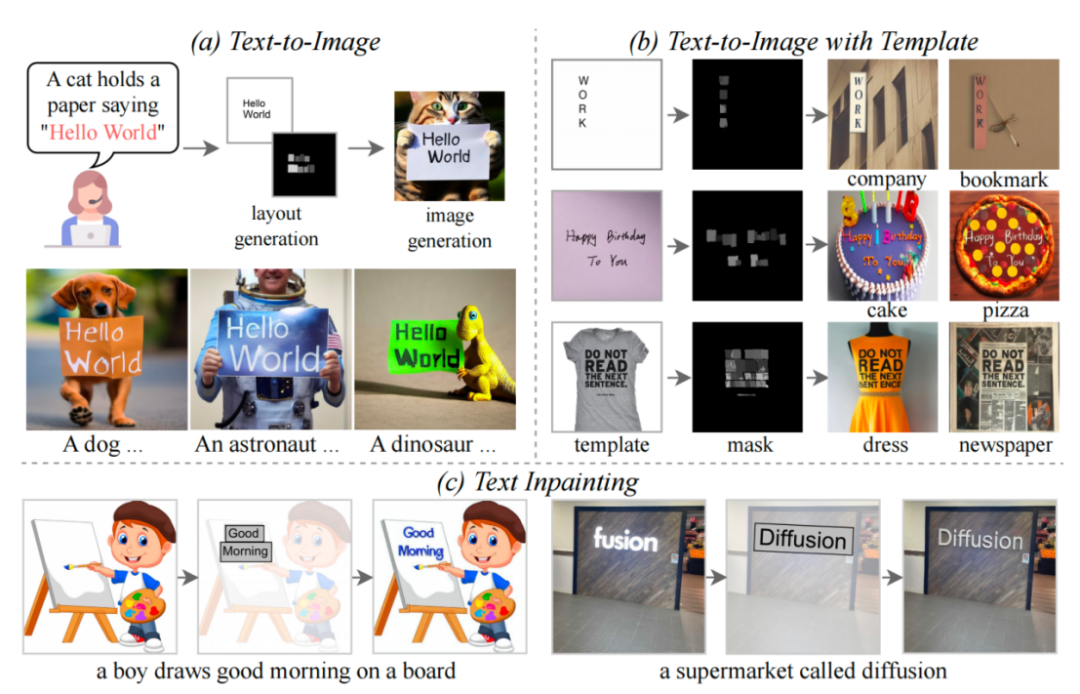
TextDiffuser の 3 つの機能
##この記事では、TextDiffuser モデルは 2 つのステージで構成され、最初のステージでレイアウトを生成し、2 番目のステージで画像を生成することを提案します。
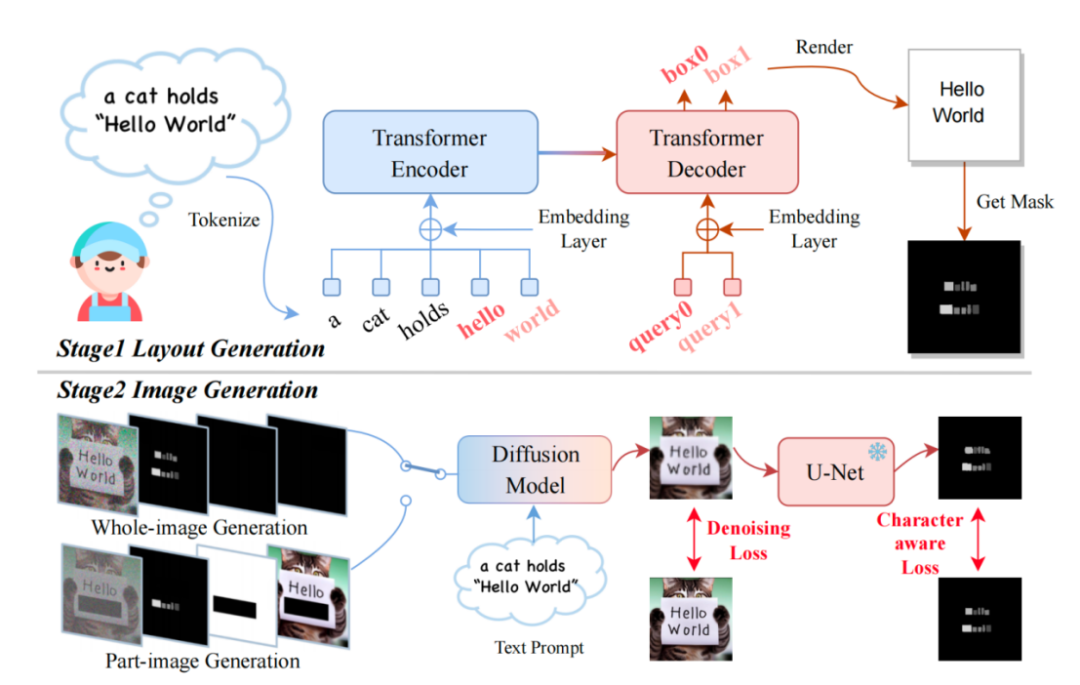 #書き直す必要があるのは、TextDiffuser フレーム図です。
#書き直す必要があるのは、TextDiffuser フレーム図です。
モデルは、 text Prompt を入力し、プロンプト内のキーワードに基づいて各キーワードのレイアウト (つまり、座標フレーム) を決定します。研究者らは、Layout Transformer を使用し、エンコーダ/デコーダ フォームを使用してキーワードの座標ボックスを自己回帰的に出力し、Python の PILLOW ライブラリを使用してテキストをレンダリングしました。このプロセスでは、Pillow の既製の API を使用して各文字の座標ボックスを取得することもできます。これは、文字レベルのボックス レベルのセグメンテーション マスクを取得するのと同じです。この情報に基づいて、研究者らは安定拡散を微調整しようとしました。
彼らは 2 つの状況を考慮しました。1 つは、ユーザーが画像全体を直接生成したい場合 (全体画像生成と呼ばれます)。もう 1 つの状況は、論文ではテキストインペインティングとも呼ばれる部分画像生成です。これは、ユーザーが画像を与え、画像内の特定のテキスト領域を変更する必要があることを意味します。
上記 2 つの目標を達成するために、研究者たちは入力特徴を再設計し、次元を元の 4 次元から 17 次元に増加しました。これらには、4 次元のノイズのある画像特徴、8 次元の文字情報、1 次元の画像マスク、および 4 次元のマスクされていない画像の特徴が含まれます。画像全体の生成の場合、研究者はマスク領域を画像全体に設定し、逆に、部分画像の生成の場合、画像の一部のみがマスクされます。拡散モデルのトレーニング プロセスは LDM に似ています。これに興味のある方は、元の記事のメソッド セクションの説明を参照してください。
推論段階では、TextDiffuser には非常に優れた機能があります。柔軟な使用方法があり、次の 3 つのタイプに分類できます。

構築された MARIO データ
TextDiffuser を訓練するために、研究者は 10,000 個のデータを収集しました上の図に示すように、テキスト画像には 3 つのサブセットが含まれています: MARIO-LAION、MARIO-TMDB、MARIO-OpenLibrary
研究者らは、データをフィルタリングする際にいくつかの側面を考慮しました。画像は OCR を受け、テキスト量が [1,8] の画像のみが保持されます。新聞や複雑な設計図面など、これらのテキストには大量の高密度のテキストが含まれていることが多く、一般に OCR 結果の精度が低いため、8 つを超えるテキストを含むテキストが除外されました。さらに、テキスト領域が 10% より大きくなるように設定されています。このルールは、画像内のテキスト領域が小さすぎることを防ぐために設定されています。
MARIO-10M データセットでトレーニングした後、研究者らは TextDiffuser と既存の手法との定量的および定性的な比較を実施しました。たとえば、画像生成タスク全体では、次の図に示すように、この方法で生成された画像のテキストはより鮮明で読みやすく、テキスト領域と背景領域の統合も優れています。
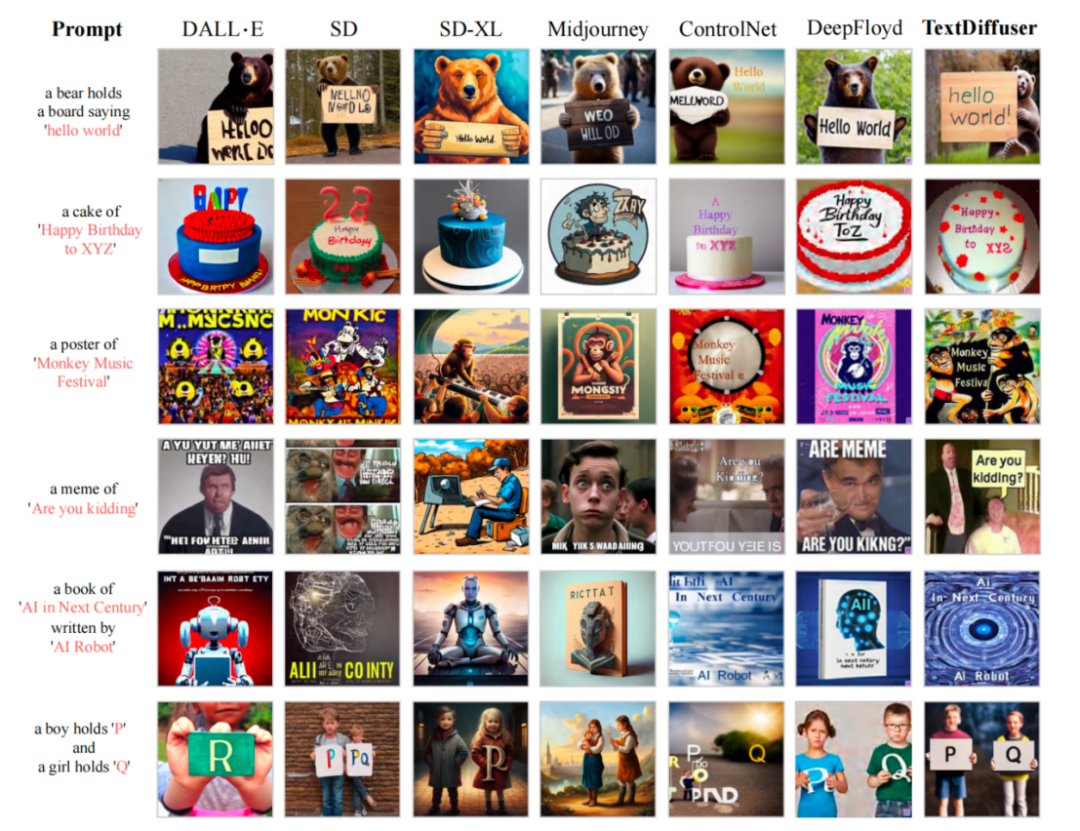 #テキスト レンダリング パフォーマンスと既存の作品との比較
#テキスト レンダリング パフォーマンスと既存の作品との比較
研究者らは一連の定性実験も実施し、その結果を表に示します。 1.評価指標には、FID、CLIPScore、OCR が含まれます。特に OCR インデックスに関して、この調査方法は比較方法と比較して大幅に改善されました
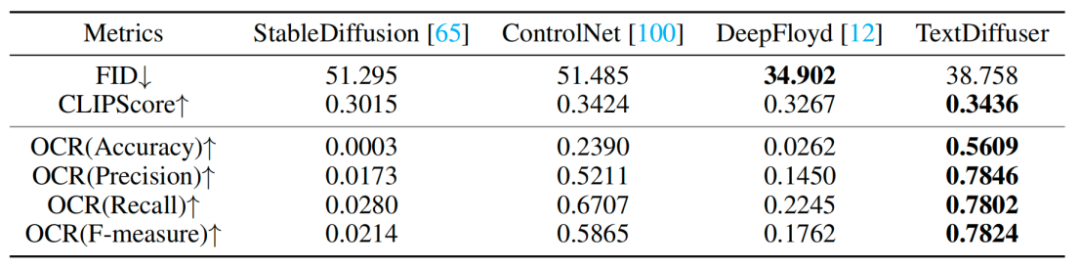 リライト内容: 実験結果を表 1 に示します。定性的実験
リライト内容: 実験結果を表 1 に示します。定性的実験
部分画像生成タスクでは、研究者は指定された画像に文字を追加または変更することを試みました。実験結果は、TextDiffuser によって生成された結果が非常に自然であることを示しました。
 #テキスト修復機能の視覚化
#テキスト修復機能の視覚化
一般的に、この記事は次のことを提案します。 TextDiffuser モデルは、テキスト レンダリングの分野で大きな進歩を遂げ、可読テキストを含む高品質の画像を生成できるようになりました。将来的には、研究者は TextDiffuser の効果をさらに改善する予定です。
以上が新しいタイトル: TextDiffuser: 画像内のテキストを恐れることなく、高品質のテキスト レンダリングを提供します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



