


AI エージェントは現在注目の分野です。OpenAI アプリケーション リサーチ ディレクターの LilianWeng が書いた長い記事 [1] の中で、彼女はエージェント = LLM メモリ プランニング スキル ツールという概念を提案しました
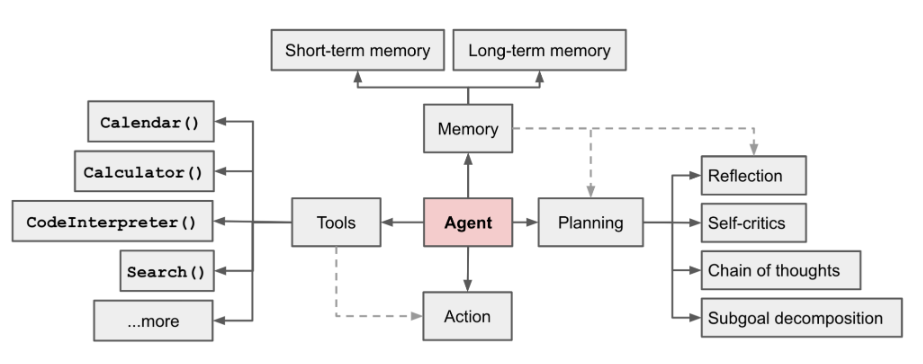
図 1 LLM を利用した自律エージェント システムの概要
エージェントの機能は次のとおりです。 LLM の強力な言語理解機能と論理的推論機能を使用して、人間がタスクを完了するのを支援するツールを呼び出します。ただし、これにはいくつかの課題も伴います。たとえば、基本モデルの能力によってエージェント呼び出しツールの効率が決まりますが、基本モデル自体には大規模モデル錯視などの問題があります。 #この記事は「入力」から始まります。基本的なエージェントプロセスを構築するための例として「複雑なタスクと命令による関数呼び出しの自動分割」のシナリオを取り上げ、「基本的なモデルの選択」を通じて「タスク」を適切に構築する方法を中心に説明します。 "、"PromptDesign
" など。「分割」モジュールと「関数呼び出し」モジュール。書き換えられた内容は次のとおりです: アドレス:
https://sota.jiqizhixin .com/project/smart_agent
GitHub リポジトリ:
書き直す必要があります内容は: https://github.com/zzlgreat/smart_agent
タスク分割と関数呼び出しエージェントプロセス
プランナー:
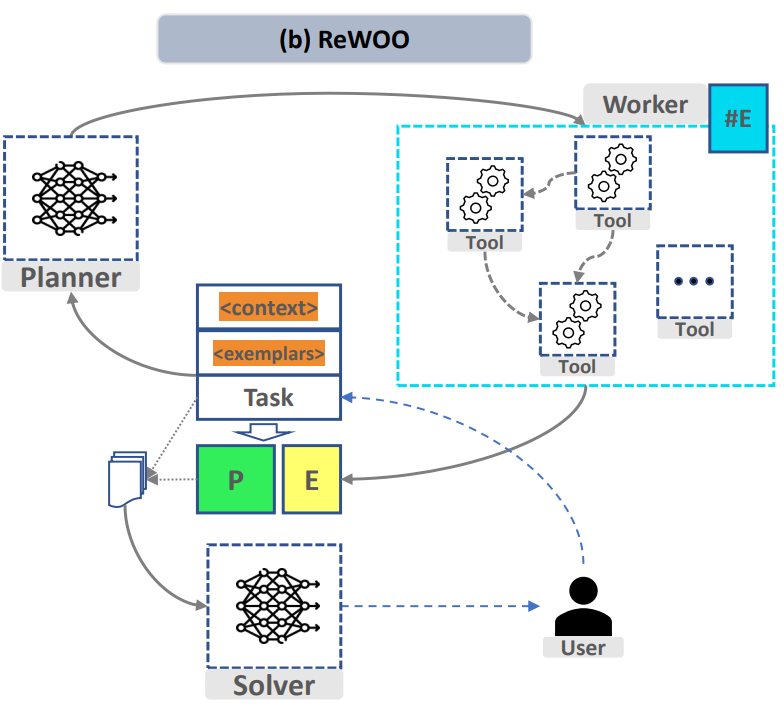
上記のプロセスを実現するために、プロジェクトは、「タスク分割」モジュールと「関数呼び出し」モジュールで、複雑なタスクを分割し、オンデマンドでカスタム関数を呼び出す機能を実現する 2 つの微調整モデルをそれぞれ設計しました。要約されたモデル ソルバーは、分割タスク モデルと同じにすることができます
#微調整されたタスク分割と関数呼び出しモデル#2.1 微調整エクスペリエンスの概要
基本モデルの選択:複雑なタスクを分割するには、微調整のための基本モデルには、十分な理解と汎化能力、つまり、トレーニング セットに含まれていないタスクをプロンプトの指示に従って分割する能力が必要です。現時点では、高いパラメーターを持つ大規模なモデルを選択することで、これを行うのが簡単になります。
さらに、コンピューティング能力の使用に関しては、lora/qlora Fine-チューニングを行い、推論の敷居をさらに下げるために定量的な展開が採用されています。
「タスク分割」モデルを選択する場合、そのモデルが強力な汎化能力と確実な思考連鎖を備えていることを望みます。能力。この点に関しては、HuggingFace の Open LLM ランキングを参照してモデルを選択できますが、マルチタスクの精度を測定するテスト MMLU と総合スコア Average
## を重視します。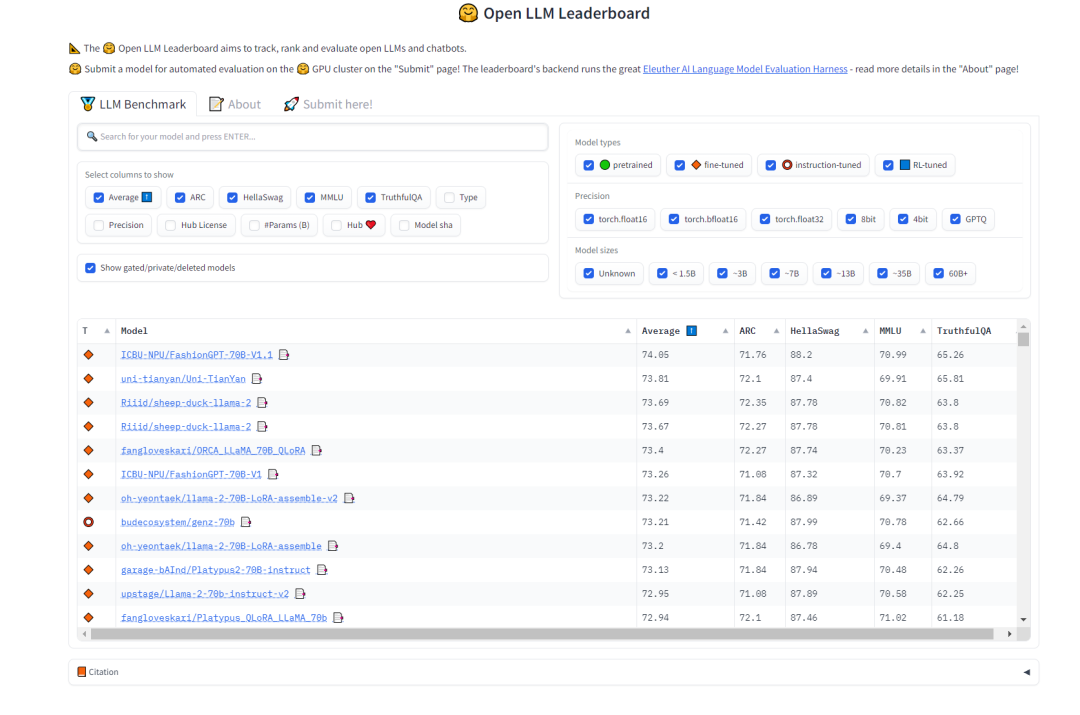
このプロジェクトに選択されたタスク分割モデル モデルは次のとおりです:
#このプロジェクトで選択された関数呼び出しモデル モデルは次のとおりです:
codellama 34b/7b: 関数呼び出しを担当するモデル。このモデルは、大量のコード データを使用してトレーニングされます。コード データには、大量のコード データが含まれている必要があります。関数の自然言語記述の数 与えられた関数の記述には、優れたゼロショット機能があります。
For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following: Wikipedia[input]: Worker that search for similar page contents from Wikipedia. Useful when you need to get holistic knowledge about people, places, companies, historical events, or other subjects.The response are long and might contain some irrelevant information. Input should be a search query. LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense. Prioritize it when you are confident in solving the problem yourself. Input can be any instruction.
関数呼び出しの場合、qlora の微調整が実行されるためしたがって、huggingface のオープンソース関数呼び出しデータ セット [3] のプロンプト スタイルが直接使用されます。以下を参照してください。
命令データセットの準備
### Instruction:(without the )### Response:如:### Instruction:For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following:get_current_time[input]: Get the current time for now. search_bing[input]: Search the web for content on Bing, and return the top 10 results. Remember, the results may not as good as Wikipedia. If you think the result will not exist in wikipedia, use it. search_wiki[input]: Search the web for content on Wikipedia, and return the top 3 results. If you think the result can exist in wikipedia, use it. search_bilibili[input]: Search for videos on Bilibili, which is a website full of ACG. It can return top 10 search results. save_file[input]: save a file in the target dir which contains the data. query_mysql[input]: Execute the sql in the local mysql database. And return the result. What movies did the director of 'Oppenheim' direct? List the top 10 best.### Response:Step 1: Identify the director of "Oppenheimer" movie.#E1 = search_wiki("Director of Oppenheimer")Step 2: Retrieve information about the director's other works.If the retrieved name exists in Wikipedia, proceed with searching their filmography using search_wiki. Otherwise, try searching through Bing or another source like IMDb.For example, if Christopher Nolan is found as the director of "Oppenheimer":#E2 = search_bing("Filmography of Christopher Nolan")Step 3: Extract the list of films directed by this person from the retrieved information.From the returned results, extract the titles of the top 10 best movies according to critics/audience ratings or personal preference.
図 3 HuggingFace 関数呼び出しのオープン ソース データ セットの例
在Ubuntu 22.04系统上,使用了CUDA 11.8和Pytorch 2.0.1,并采用了LLaMA-Efficient-Tuning框架。此外,还使用了Deepspeed 0.10.4
需要进行针对 Marcoroni-70B 的 lora 微调
全部选择完成后,新建一个训练的 bash 脚本,内容如下:
accelerate launch src/train_bash.py \--stage sft \--model_name_or_path your_model_path \--do_train \--dataset rewoo \--template alpaca \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir your_output_path \--overwrite_cache \--per_device_train_batch_size 1 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-6 \--num_train_epochs 4.0 \--plot_loss \--flash_attn \--bf16
这样的设置需要的内存峰值最高可以到 240G,但还是保证了 6 卡 4090 可以进行训练。开始的时候可能会比较久,这是因为 deepspeed 需要对模型进行 init。之后训练就开始了。
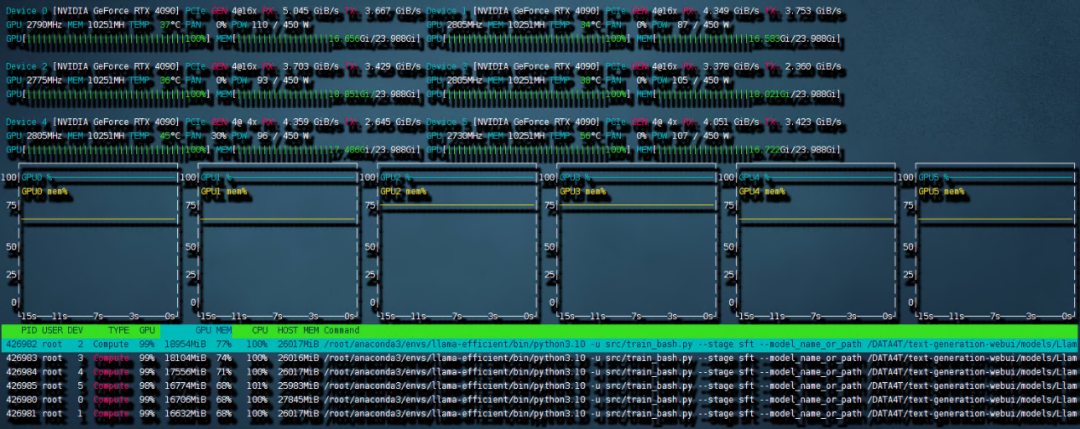
需要重新写的内容是:图4 6 卡 4090 训练带宽速度
共计用时 8:56 小时。本次训练中因为主板上的 NVME 插槽会和 OCULINK 共享一路 PCIE4.0 x16 带宽。所以 6 张中的其中两张跑在了 pcie4.0 X4 上,从上图就可以看出 RX 和 TX 都只是 PCIE4.0 X4 的带宽速度。这也成为了本次训练中最大的通讯瓶颈。如果全部的卡都跑在 pcie 4.0 x16 上,速度应该是比现在快不少的。
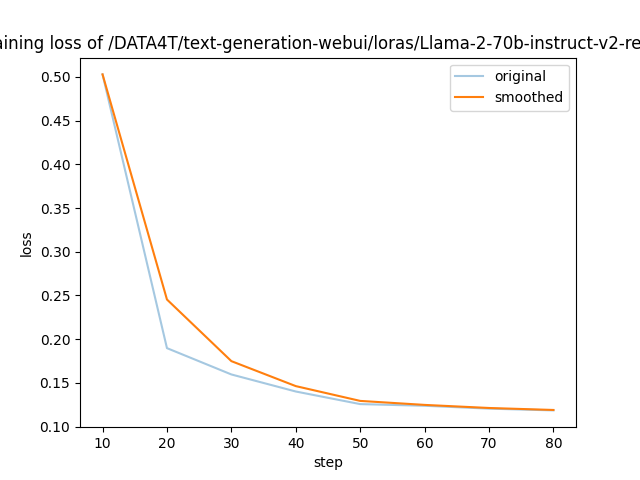
需要进行改写的内容是:图5展示了LLaMA-Efficient-Tuning生成的损失曲线
以上是 LLaMA-Efficient-Tuning 自动生成的 loss 曲线,可以看到 4 个 epoch 后收敛效果还是不错的。
2)针对 codellama 的 qlora 微调
根据前文所述的 prompt loss mask 方法,我们对 trainer 类进行了重构(请参考项目代码仓库中的 func_caller_train.py)。由于数据集本身较小(共55行),所以仅需两分钟即可完成4个epoch的训练,模型迅速收敛
在项目代码仓库中,提供了一个简短可用的 toolkit 示例。里面的函数包括:
现在有一个70B和一个34B的模型,在实际使用中,用6张4090同时以bf16精度运行这两个模型是不现实的。但是可以通过量化的方法压缩模型大小,同时提升模型推理速度。这里采用高性能LLM推理库exllamav2运用flash_attention特性来对模型进行量化并推理。在项目页面中作者介绍了一种独特的量化方式,本文不做赘述。按照其中的转换机制可以将70B的模型按照2.5-bit量化为22G的大小,这样一张显卡就可以轻松加载
需要重新编写的内容是:1)测试方法
トレーニング セットに含まれていない複雑なタスクの説明がある場合、トレーニング セットに含まれていない関数と対応する説明をツールキットに追加します。プランナーがタスクの分割を完了できれば、ディストリビューターは関数を呼び出すことができ、ソルバーはプロセス全体に基づいて結果を要約することができます。
書き直す必要がある内容は次のとおりです: 2) テスト結果
タスク分割: 最初にテキストを使用します。次の図に示すように、generation -webui はタスク分割モデルの効果を迅速にテストします。

#図 6 タスク分割テストの結果
ここに単純なrestful_api インターフェイスを記述して、エージェント テスト環境での呼び出しを容易にすることができます (プロジェクト コード fllama_api.py を参照)。
関数呼び出し: 単純なプランナー、ディストリビューター、ワーカー、ソルバーのロジックがプロジェクトに記述されています。次に、このタスクをテストしてみましょう。コマンドを入力してください: 「Killers of the Flower Moon」の監督はどのような映画を監督しましたか?そのうちの 1 つをリストし、bilibili で検索してください。
関数「bilibili を検索」は、プロジェクトの関数呼び出しトレーニング セットには含まれていません。同時に、このムービーはまだ公開されていない新しいムービーでもあり、モデル自体の学習データが含まれているかどうかは不明です。モデルが入力命令を適切に分割していることがわかります。
複数の関数呼び出し同時に以下の結果が得られました。 クリック結果は Goodfellas で、映画の監督と一致しました。
このプロジェクトは、「コマンドを入力することで複雑なタスク分割と関数呼び出しを自動で実現する」というシナリオを例として設計します。基本エージェント プロセスのセット:toolkit-plan-distribute-worker-solver は、1 ステップでは完了できない基本的な複雑なタスクを実行できるエージェントを実装します。基本モデルの選択と lora の微調整により、大規模モデルの微調整と推論を低い計算能力条件下で完了できます。そして、推論の敷居をさらに下げるために、定量的な展開方法を採用します。最後に、映画監督の他の作品を検索する例がこのパイプラインを通じて実装され、基本的な複雑なタスクが完了しました。
制限事項: この記事では、検索と基本操作用のツールキットに基づいた関数呼び出しとタスク分割のみを設計します。使用されるツールセットは非常にシンプルで、あまりデザインがありません。フォールトトレランスメカニズムについてはあまり考慮されていません。このプロジェクトを通じて、誰もが RPA 分野のアプリケーションを引き続き探索し、エージェント プロセスをさらに改善し、高度なインテリジェントな自動化を達成してプロセスの管理性を向上させることができます。
以上がAI エージェントはどのように実装されますか? 4090 魔法で改造された Llama2 の写真 6 枚: タスクを分割し、1 つのコマンドで関数を呼び出すの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



