


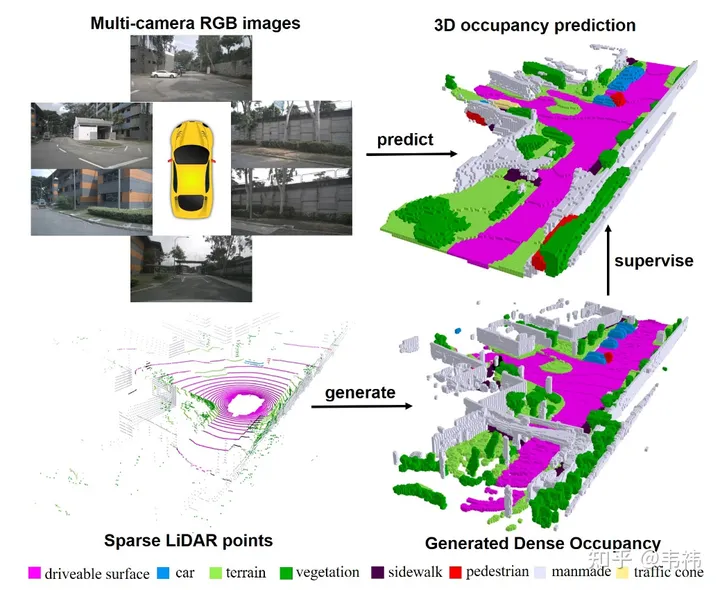
この作業では、マルチフレーム点群を通じて高密度の占有ラスター データセットを構築し、トランスフォーマーの 2D-3D Unet 構造に基づいて 3 次元占有ラスター ネットワークを設計しました。私たちの記事が ICCV 2023 に掲載されていることを光栄に思います。プロジェクト コードは現在オープンソースであり、誰でも試すことができます。

arXiv: https://arxiv.org/pdf/2303.09551.pdf
コード: https://github.com/weiyithu/SurroundOcc
ホームページ リンク: https://weiyithu.github.io/SurroundOcc/
最近、狂ったように仕事を探していて、書く時間がありません。最近、カメラ準備完了の提出物を提出したところです。社会人として、結局は志胡のまとめを書いた方が良いのではないかと思いました。実際、記事の導入部分はすでにさまざまな公開アカウントによってよく書かれており、その宣伝のおかげで、自動運転の心臓部である nuScenes SOTA! を直接参照することができます。 SurroundOcc: 自動運転用の純粋なビジュアル 3D 占有予測ネットワーク (清華およびTianda)。一般に、貢献は 2 つの部分に分かれており、1 つはマルチフレーム LIDAR 点群を使用して高密度の占有データ セットを構築する方法、もう 1 つは占有予測用のネットワークを設計する方法です。実際、どちらの部分も比較的単純で理解しやすい内容になっており、わからないことがあればいつでも質問していただけます。そこでこの記事では、理論以外のことについてお話したいと思います。1 つは、現在のソリューションをどのように改善して導入しやすくするか、もう 1 つは将来の開発の方向性です。
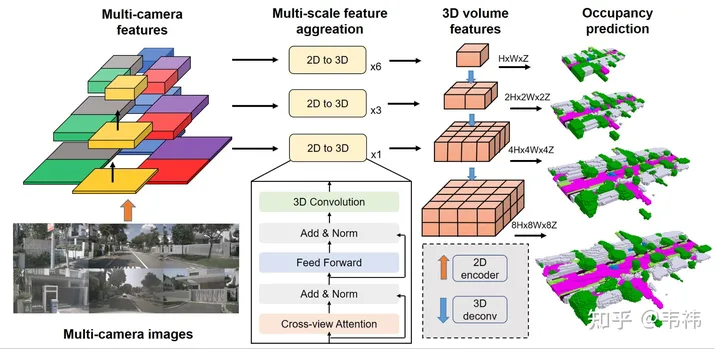
ネットワークの展開が簡単かどうかは、主にネットワークが適切かどうかによって決まります。オペレータはボード側に実装されますが、SurroundOcc メソッドの 2 つのより困難なオペレータは、トランス層と 3D コンボリューションです。
トランスフォーマーの主な機能は、2D 特徴を 3D 空間に変換することです。実際、この部分は LSS、ホモグラフィー、さらには mlp を使用して実装することもできるため、ネットワークのこの部分は、実装されたソリューション。ただし、私の知る限り、変圧器ソリューションはキャリブレーションの影響を受けにくく、いくつかのソリューションの中でパフォーマンスが優れているため、変圧器の展開を実装する能力がある人は、元のソリューションを使用することをお勧めします。
3D コンボリューションの場合は、2D コンボリューションに置き換えることができます。ここでは、(C、H、W、Z) の元の 3D 特徴を (C* Z、H、W) 2D 特徴に再形成する必要があります。その後、特徴抽出に 2D 畳み込みを使用でき、最後の占有予測ステップでは、(C、H、W、Z) に再整形され、監視されます。一方、スキップ接続は解像度が高いため、より多くのビデオ メモリを消費しますが、展開時に削除して、最小解像度のレイヤーのみを残すことができます。私たちの実験では、3D コンボリューションのこれら 2 つの操作には nuscene でいくつかのドロップ ポイントがあることがわかりましたが、業界のデータ セットの規模は nuscene よりもはるかに大きいため、場合によってはいくつかの結論が変更され、ドロップ ポイントは少なくなるか、まったくなくなるはずです。
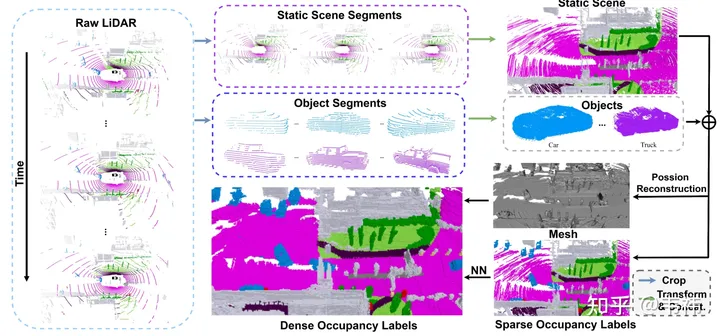
データセットの構築に関して、最も時間のかかるステップはポアソン再構成です。収集には 32 ライン LIDAR を使用する nuscenes データ セットを使用します。マルチフレーム ステッチング技術を使用した場合でも、ステッチされた点群には依然として多くの穴が存在することがわかりました。したがって、これらの穴を埋めるためにポアソン再構成を採用しました。ただし、現在業界で使用されている LIDAR 点群の多くは、M1、RS128 など比較的密度が高くなります。したがって、この場合、データセットの構築を高速化するためにポアソン再構成ステップを省略できます。
一方、SurroundOcc は、nuscenes でマークされた 3 次元ターゲット検出フレームを使用して、静的シーンを結合します。と動的オブジェクトが分離されます。ただし、実際のアプリケーションでは、大規模な 3 次元ターゲット検出および追跡モデルであるオートラベルを使用して、シーケンス全体の各オブジェクトの検出フレームを取得できます。手動で注釈を付けたラベルと比較すると、大規模なモデルを使用して生成された結果には間違いなくエラーが含まれます。最も直接的に現れるのは、オブジェクトの複数のフレームを結合した後のゴースト現象です。しかし実際には、職業では物体の形状に対する要求はそれほど高くなく、検出枠の位置が比較的正確であれば要求を満たすことができます。
現在の方法は依然としてライダーを利用して乗員監視信号を提供していますが、多くの車、特に一部の低レベル運転支援車にはライダーが搭載されていません。シャドウモードでは大量のRGBデータが返せるので、今後の方向性としては自己教師あり学習のみにRGBを使えるかどうかです。自然な解決策は、監視に NeRF を使用することです。具体的には、フロント バックボーン部分は変更せずに占有予測を取得し、ボクセル レンダリングを使用して各カメラの視点から RGB を取得し、損失は真の値 RGB で行われます。トレーニング セット監視信号を作成します。しかし、この単純な方法が実際に試してみたところ、あまりうまく機能しなかったのが残念です。考えられる理由としては、屋外シーンの範囲が広すぎてナーフが保持できない可能性もありますが、可能性もあります。正しく調整されていないことがわかります。もう一度試してください。
もう 1 つの方向は、タイミングと占有フローです。実際、占有フローは、単一フレームの占有よりも下流のタスクにとってはるかに便利です。 ICCV の期間中は、占有フローのデータセットを編集する時間がなく、論文を発表するときに多くのフロー ベースラインを比較する必要があったため、その時点では作業しませんでした。タイミング ネットワークについては、比較的シンプルで効果的な BEVFormer および BEVDet4D のソリューションを参照できます。難しい部分はやはりフロー データ セットです。一般的なオブジェクトはシーケンスの 3 次元ターゲット検出フレームを使用して計算できますが、小動物のビニール袋などの特殊な形状のオブジェクトには、シーン フロー手法を使用してアノテーションを付ける必要がある場合があります。

書き直す必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug
以上がSurroundOcc: サラウンド 3D 占有グリッドの新しい SOTA!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



