


書き直す必要がある内容は次のとおりです: 著者 Richard MacManus
計画 | Yan Zheng
Web3 は Web2 を破壊することはできませんでしたが、新興の大規模モデル開発スタックにより、開発者は次のことを可能にしています。 「クラウド」からスタート 「ネイティブ」の時代は、新たなAI技術スタックに向かって進んでいます。
ヒント エンジニアは、大規模なモデルに急ぐ開発者の神経には触れられないかもしれませんが、プロダクト マネージャーまたはリーダーからの一文: 「エージェント」は開発できるか、「チェーン」は実装できるか、 「どのベクトル データベースを使用するか?」という問題がありましたが、主要な主流の大規模モデル アプリケーション企業の運転技術学生にとって、生成 AI の開発を克服することは困難になっています。
新興テクノロジー スタックの層は何ですか?最も難しい部分はどこですか?この記事では、次のことがわかります。
過去 1 年で、次のようなツールがいくつか登場しました。これにより、AI アプリケーションの開発者エコシステムが成熟し始めました。現在では、人工知能の開発に注力する人たちを表す言葉として「AIエンジニア」も使われています。 Shawn @swyx Wang 氏によると、これは「迅速なエンジニア」にとっての次のステップです。また、AI エンジニアがより広範な人工知能エコシステムのどこに当てはまるかを視覚化するための座標図も作成しました。
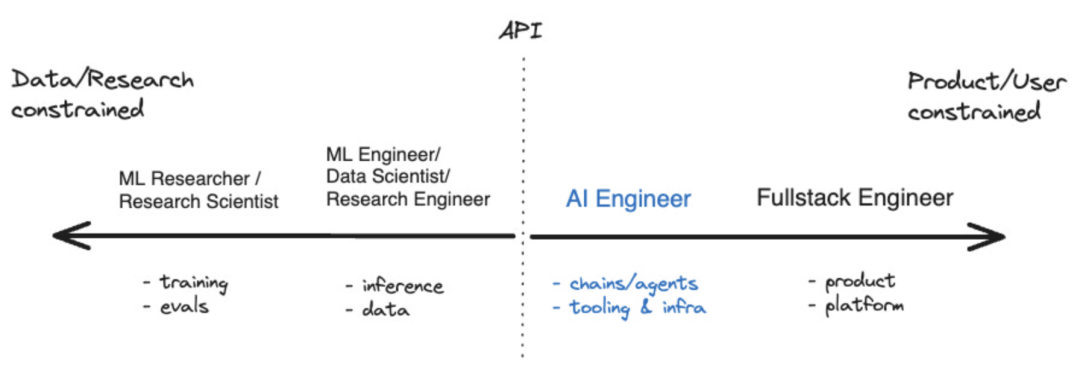 #出典: swyx## 大規模言語モデル (LLM) AIエンジニアのコアテクノロジーです。 LangChain と LlamaIndex の両方が LLM を拡張および補完するツールであることは偶然ではありません。しかし、この新しい種類の開発者が利用できる他のツールは何でしょうか?
#出典: swyx## 大規模言語モデル (LLM) AIエンジニアのコアテクノロジーです。 LangChain と LlamaIndex の両方が LLM を拡張および補完するツールであることは偶然ではありません。しかし、この新しい種類の開発者が利用できる他のツールは何でしょうか?
これまでのところ、私が見た LLM スタックの最も優れた図は、ベンチャー キャピタル会社 Andreessen Horowitz (a16z) のものです。以下は、「LLM アプリ スタック」に関する見解です:
出典: a16z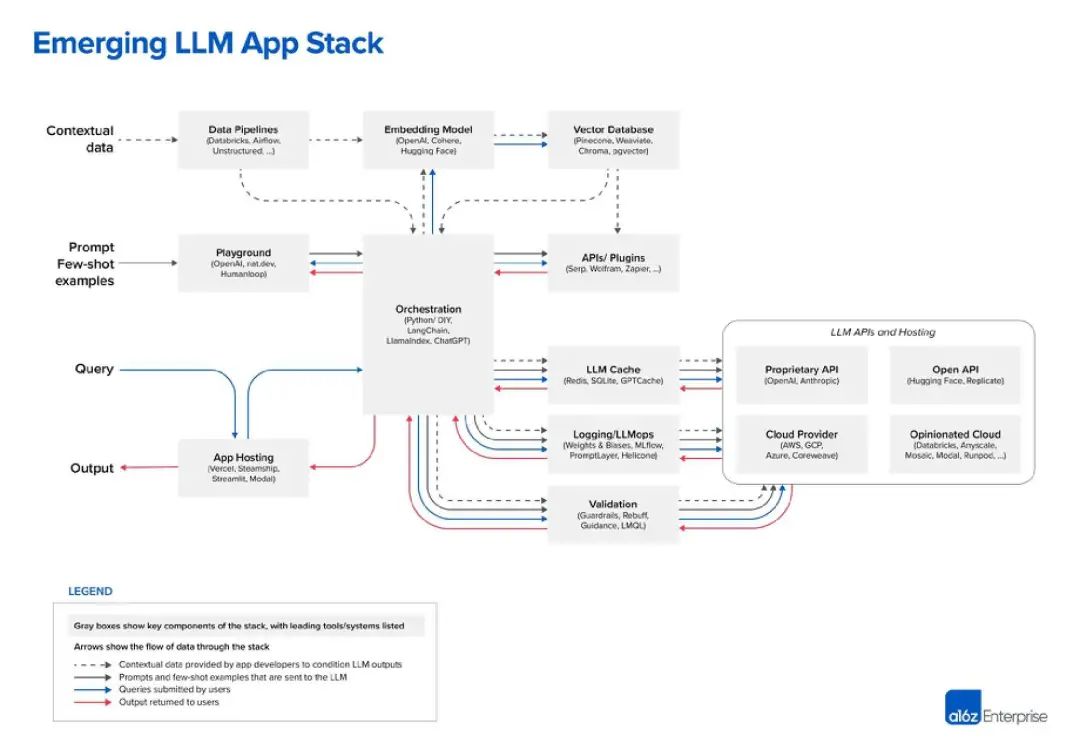
を含むその他の数十の LLM オプションから選択できます。LLM を使用する前に、 「データパイプライン」を確立する必要があります。たとえば、Databricks と Airflow を 2 つの例として考えてみましょう。そうでない場合、データは「非構造化」で処理できます。これはデータの周期性にも当てはまり、企業がカスタム LLM にデータを入力する前にデータを「クリーンアップ」するか、単に整理するのに役立ちます。 Alation のような「データ インテリジェンス」企業は、この種のサービスを提供しています。これは、IT テクノロジ スタックでよく知られている「ビジネス インテリジェンス」などのツールに似ています。
データ レイヤーの最後の部分は非常に人気があります。最近では、LLM データを保存および処理するためのベクトル データベース。 Microsoft の定義によれば、これはデータを高次元ベクトルとして保存するデータベースであり、これは特徴や属性の数学的表現です。データは埋め込みテクノロジを使用してベクトルとして保存され、大手ベクトル データベース ベンダーである Pinecone はメディア チャットで、自社のツールが Databricks などのデータ パイプライン ツールと併用されることが多いと述べました。この場合、データは通常、他の場所 (データ レイクなど) に保存され、機械学習モデルを介して埋め込みデータに変換されます。処理とチャンク化の後、結果のベクトルが Pinecone に送信されます。
3、ヒントとクエリ
次の 2 つのレベルはヒントとクエリとして要約できます。これは人工知能アプリケーションです。プログラムが LLM および (オプションで) 他のデータ ツールと連携する対話。 A16z は、LangChain と LlamaIndex を「オーケストレーション フレームワーク」として位置付けています。つまり、開発者が使用している LLM を理解すれば、これらのツールを活用できるということです。
A16z はブログ投稿では正確に定義されていませんが、「Playground」ツールは次のことができると推測できます。 help 開発者は、A16z が「キュー柔術」と呼ぶものを実行します。これらの場所では、開発者はさまざまなプロンプト手法を試すことができます。
Humanloop は英国の企業で、そのプラットフォームには「共同プロンプト ワークスペース」が特徴です。さらに、それ自体を「本番 LLM 機能のための完全な開発ツールキット」であると説明しています。したがって、基本的には LLM のものを試し、それが機能する場合はアプリケーションにデプロイすることができます
現在、大規模な生産ラインのレイアウトが徐々に明らかになりつつあります。オーケストレーション ボックスの右側には、LLM キャッシュや検証などの多くの操作ボックスがあります。さらに、Hugging Face などのオープン API リポジトリや、OpenAI などの独自の API プロバイダーを含む、LLM 関連の一連のクラウド サービスと API サービスがあります。
これは、「クラウド ネイティブ」の第一歩となるかもしれません。多くの DevOps 企業が、自社の製品リストに、開発者が慣れ親しんでいる技術スタックの最も類似した場所に人工知能を追加しているのは偶然ではありません。 5月に私はハーネスのCEO、ジョティ・バンサル氏と話をした。 Harness は、CI/CD プロセスの「CD」部分に焦点を当てた「ソフトウェア配信プラットフォーム」を実行しています。
Bansai 氏は、既存の機能に基づいた仕様の生成からコードの記述に至るまで、ソフトウェア配信ライフサイクルに関わる退屈で反復的なタスクを AI が軽減できると教えてくれました。さらに同氏は、AIはコードレビュー、脆弱性テスト、バグ修正を自動化し、さらにはビルドやデプロイのためのCI/CDパイプラインの作成も可能だと述べた。 5 月に私が行った別の会話によると、AI は開発者の生産性も変化させています。ビルド自動化ツール Gradle の Trisha Gee 氏は、AI はボイラープレート コードの作成などの反復的なタスクの時間を削減し、開発者がコードがビジネス ニーズを満たしているかどうかを確認するなどの全体像に集中できるようにすることで、開発をスピードアップできると語った。
新興の LLM 開発テクノロジ スタックでは、オーケストレーション フレームワーク ( LangChain や LlamaIndex など)、ベクトル データベース、Humanloop などの「プレイグラウンド」プラットフォーム。これらの製品はすべて、かつての Spring Cloud や Kubernetes などのクラウドネイティブ時代のツールの台頭と同様に、現在の時代のコアテクノロジーである大規模言語モデルを拡張および/または補完しています。ただし、現在、クラウド ネイティブ時代の大企業、中小企業、トップ企業のほぼすべてが、自社のツールを AI エンジニアリングに適応させるために最善を尽くしており、これは LLM テクノロジー スタックの将来の開発に非常に有益です。
はい、今回の大きなモデルは「巨人の肩の上に立っている」ようです。コンピューター技術における最高のイノベーションは常に過去に基づいています。おそらくそれが、「Web3」革命が失敗した理由です。それは前世代を基礎にして構築するというよりも、それを横取りしようとしたのです。
LLM テクノロジー スタックはそれを実現したようで、クラウド開発時代から新しい人工知能ベースの開発者エコシステムへの架け橋となっています
参考リンク:
https :/ /m.sbmmt.com/link/c589c3a8f99401b24b9380e86d939842以上が大規模なモデル開発ツールセットが作成されました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



