



多くの企業は、GPU コンピューティング能力の開発を組み合わせて、自社に適した機械学習の問題の解決策を模索しています。たとえば、Xiaohongshu は、推論のパフォーマンスと効率を向上させるために、2021 年にプロモーション検索モデルの GPU ベースの変換を開始します。移行プロセスでは、異種ハードウェアにスムーズに移行する方法、Xiaohongshu のビジネス シナリオとオンライン アーキテクチャに基づいて独自のソリューションを開発する方法など、いくつかの困難にも直面しました。コスト削減と効率向上の世界的な傾向の下で、異機種混合コンピューティングは有望な方向性となっています。ヘテロジニアス コンピューティングでは、異なる種類のプロセッサ (CPU、GPU、FPGA など) を組み合わせてコンピューティング パフォーマンスを向上させ、効率の向上とコストの削減を実現します。
Xiaohongshu の推奨、広告、検索、その他の主要なシナリオのモデル サービスは、中間段階の推論アーキテクチャによって均一に実行されます。 Xiaohonshu のビジネスの継続的な発展に伴い、プロモーション検索などのシナリオのモデルの規模も拡大しています。洗練されたレコメンデーションシナリオのメインモデルを例に挙げると、2020年初頭からアルゴリズムがフルインタレストモデリングを開始し、ユーザーの過去の行動記録の平均長が約100倍に拡大しました。モデル構造も最初のマルチタスクから複数回の反復を経ており、モデル構造の複雑さも増加し続けており、これらの変更により、浮動小数点演算の数が 30 倍に増加しました。モデル推論とモデル メモリ アクセスが約 5 倍増加しました。
 #図
#図
モデル特徴: Xiaohongshu が 2022 年末に推奨したメイン モデルを例に挙げます. このモデルは完全にスパースです. 構造の一部は連続値特徴と行列演算で構成されています. 大規模なスパース パラメーターもあります など、単一モデルの疎な特徴は最大 1 TB ですが、比較的効果的なモデル構造の最適化により、密な部分は 10 GB 以内に制御され、ビデオ メモリに配置できます。ユーザーが小紅書をスワイプするたびに計算される合計 FLOP は 40B に達し、タイムアウトは 300 ミリ秒以内に制御されます (ルックアップによる機能処理を除く)。
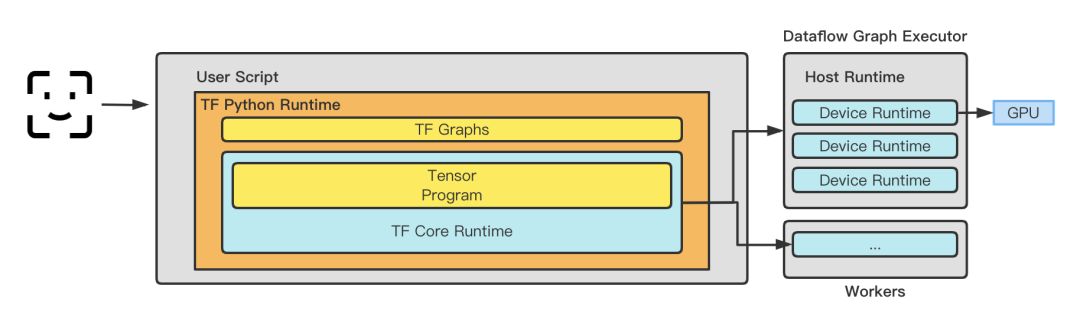
推論フレームワーク: Xiaohongshu は、2020 年以前はオンライン サービス フレームワークとして TensorFlow Serving フレームワークを採用していましたが、2020 年以降は、徐々に反復して、次のベースの自社開発フレームワークに移行しました。 TensorFlowCore Lambda Service サービス。 TensorFlow Serving は、モデル推論の正確さと信頼性を確保するために、グラフに入る前に TensorProto -> CTensor のメモリ コピーを実行します。ただし、ビジネス規模が拡大すると、メモリ コピー操作がモデルのパフォーマンスに影響を与えるようになります。 Xiaohongshu が独自に開発したフレームワークは、ランタイム、グラフ スケジューリング機能、最適化機能のプラグイン可能な機能を維持しながら、最適化によって不必要なコピーを排除し、TRT、BLADE、TVM などのさまざまな最適化フレームワークを後で使用するための基盤を築きます。現在では、適切なタイミングで自己調査を選択することが賢明な選択であるように見えますが、同時に、データ送信のコストを最小限に抑えるために、推論フレームワークが特徴抽出と変換の実装の一部も引き受けます。まだ見積もり中 自社開発のエッジ ストレージがサービスの手前側に展開され、リモートでデータをプルするコストの問題が解決されます。
モデルの特徴: Xiaohongshu は独自のコンピューター室を構築していません。すべてのマシンはクラウド ベンダーから購入されています。したがって、さまざまなモデルを選択する決定は、主に何を選択するかによって決まります。購入できる機械の種類は何ですか?モデル推論の計算は純粋な GPU 計算ではなく、適切なハードウェア比率を見つけるには、GPU/CPU を考慮することに加えて、帯域幅、メモリ帯域幅、沼間通信遅延などの問題も考慮します。
 画像
画像
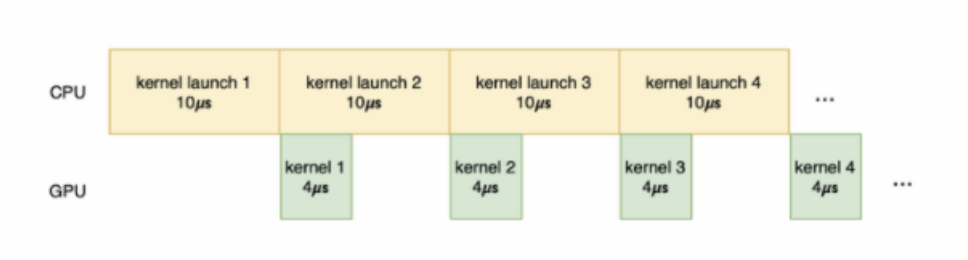
GPU の機能:Xiaohong 問題GPU カーネルの実行は、データ送信、カーネル起動、カーネル計算、結果送信の各段階に分けられます。このうち、データ転送はホストメモリからGPUメモリへデータを転送すること、カーネル起動はカーネルコードをホスト側からGPU側へ転送し、GPU上でカーネルを起動すること、カーネル計算は実際にカーネルコードを実行することです。カーネル コードの計算結果。結果の送信先 計算結果は GPU メモリからホスト メモリに転送されます。データ送信とカーネルの起動に大量の時間が費やされ、計算のためにカーネルに渡される作業がそれほど重くなく、実際の計算時間が非常に短い場合、GPU 使用率は改善されず、空の実行でさえも改善されません。起こる。
 写真
写真
3.1.1 物理マシン
物理マシンの最適化についてパフォーマンスの面では、従来の最適化のアイデアをいくつか採用できますが、主な目的は、GPU 以外のシステム オーバーヘッドのコストを削減し、仮想化仲介業者が獲得する価格差を削減することです。一般的に、一連のシステム最適化によりパフォーマンスが 1% ~ 2% 向上しますが、私たちの実践から、最適化はクラウド ベンダーの実際の機能と組み合わせる必要があります。
## ● 割り込みの分離: GPU 割り込みを分離して、GPU コンピューティングのパフォーマンスに影響を与える他のデバイスからの割り込みを回避します。 # カーネル バージョンのアップグレード: システムの安定性とセキュリティが向上し、GPU ドライバーの互換性とパフォーマンスが向上します。## ● 命令の透過的な送信: GPU 命令を透過的に物理デバイスに直接送信し、GPU の計算速度を高速化します。
3.1.2 仮想化とコンテナ複数のカードの場合、単一のポッドを特定の NUMA ノードにバインドすることでデータを改善しますCPUとGPU間の転送速度。
# CPU NUMA アフィニティ。アフィニティは、CPU の観点から見て、どのメモリ アクセスが高速でレイテンシが低いかを示します。前述したように、CPU に直接接続されたローカル メモリの方が高速です。したがって、オペレーティング システムは、アクセス速度とパフォーマンスを向上させるために、タスクが配置されている CPU に応じてローカル メモリを割り当てることができます。これは、CPU NUMA アフィニティの考慮事項に基づいており、ローカル NUMA ノードでタスクを実行しようとします。 Xiaohonshu のシナリオでは、CPU のメモリ アクセスのオーバーヘッドは小さくありません。 CPU がローカル メモリに直接接続できるようにすると、CPU でのカーネル実行にかかる時間を大幅に節約でき、GPU に十分なスペースを確保できます。
# CPU 使用率を 70% に制御することで、遅延を 200ms -> 150ms に短縮できます。
3.1.3 ミラーコンパイルの最適化。 CPU が異なれば命令レベルのサポート機能も異なり、クラウド ベンダーによって購入されるモデルも異なります。比較的単純なアイデアは、さまざまなハードウェア シナリオでさまざまな命令セットを使用してイメージをコンパイルすることです。オペレーターを実装する場合、多くのオペレーターはすでに AVX512 などの命令を備えています。 Alibaba Cloud の Intel(R) With 最適化により、このモデルの CPU スループットは 10% 向上しました。
# Intel(R) Xeon(R) Platinum 8163 for ali intelbuild:intel --copt=-march=skylake-avx512 --copt=-mmmx --copt=-mno-3dnow --copt=-mssebuild:intel --copt=-msse2 --copt=-msse3 --copt=-mssse3 --copt=-mno-sse4a --copt=-mcx16build:intel --copt=-msahf --copt=-mmovbe --copt=-maes --copt=-mno-sha --copt=-mpclmulbuild:intel --copt=-mpopcnt --copt=-mabm --copt=-mno-lwp --copt=-mfma --copt=-mno-fma4build:intel --copt=-mno-xop --copt=-mbmi --copt=-mno-sgx --copt=-mbmi2 --copt=-mno-pconfigbuild:intel --copt=-mno-wbnoinvd --copt=-mno-tbm --copt=-mavx --copt=-mavx2 --copt=-msse4.2build:intel --copt=-msse4.1 --copt=-mlzcnt --copt=-mrtm --copt=-mhle --copt=-mrdrnd --copt=-mf16cbuild:intel --copt=-mfsgsbase --copt=-mrdseed --copt=-mprfchw --copt=-madx --copt=-mfxsrbuild:intel --copt=-mxsave --copt=-mxsaveopt --copt=-mavx512f --copt=-mno-avx512erbuild:intel --copt=-mavx512cd --copt=-mno-avx512pf --copt=-mno-prefetchwt1build:intel --copt=-mno-clflushopt --copt=-mxsavec --copt=-mxsavesbuild:intel --copt=-mavx512dq --copt=-mavx512bw --copt=-mavx512vl --copt=-mno-avx512ifmabuild:intel --copt=-mno-avx512vbmi --copt=-mno-avx5124fmaps --copt=-mno-avx5124vnniwbuild:intel --copt=-mno-clwb --copt=-mno-mwaitx --copt=-mno-clzero --copt=-mno-pkubuild:intel --copt=-mno-rdpid --copt=-mno-gfni --copt=-mno-shstk --copt=-mno-avx512vbmi2build:intel --copt=-mavx512vnni --copt=-mno-vaes --copt=-mno-vpclmulqdq --copt=-mno-avx512bitalgbuild:intel --copt=-mno-movdiri --copt=-mno-movdir64b --copt=-mtune=skylake-avx512
3.2 計算の最適化
3.2.1 計算能力を最大限に活用する
#●計算最適化を行うには、まずハードウェアのパフォーマンスを十分に理解し、徹底的に理解する必要があります。 Xiaohonshu のシナリオでは、次の図に示すように、2 つの主要な問題が発生しました: 1. CPU 上で多くのメモリ アクセスがあり、メモリ ページ フォールトの頻度が高く、その結果、メモリの無駄が発生します。 CPU リソース、およびリクエストの遅延が高すぎる
2. オンライン推論サービスでは、計算には通常、1 つのリクエストのバッチ サイズが小さいことと、1 つのサービスの同時実行スケールが大きいという 2 つの特性があります。バッチ サイズが小さいと、カーネルが GPU の計算能力を十分に活用できなくなります。 GPU カーネルの実行時間は一般的に短く、カーネル起動のオーバーヘッドを完全にカバーすることはできず、カーネル起動時間はカーネル実行時間よりも長くなる場合もあります。 TensorFlow では、単一の Cuda Stream 起動カーネルがボトルネックとなり、推論シナリオでの GPU 使用率はわずか 50% になります。さらに、小規模モデル シナリオ (単純で高密度なネットワーク) の場合、CPU を GPU に置き換えることはコスト効率が悪く、モデルの複雑さが制限されます。
写真
上記 2 つの問題を解決するために、次の対策を講じました。 1メモリ ページ フォールトの頻度が高いという問題を解決するために、jemalloc ライブラリを使用してメモリ リサイクル メカニズムを最適化し、オペレーティング システムの透過的ヒュージ ページ機能を有効にします。さらに、ラムダの特殊なメモリ アクセス特性に合わせて、メモリの断片化を可能な限り回避するために、特別なデータ構造を設計し、メモリ割り当て戦略を最適化します。同時に、tf_serving インターフェイスを直接バイパスして TensorFlow を直接呼び出し、データのシリアル化と逆シリアル化を削減しました。これらの最適化により、ホームページとインストリームの微調整シナリオでスループットが 10% 向上し、ほとんどの広告シナリオで遅延が 50% 削減されました。
画像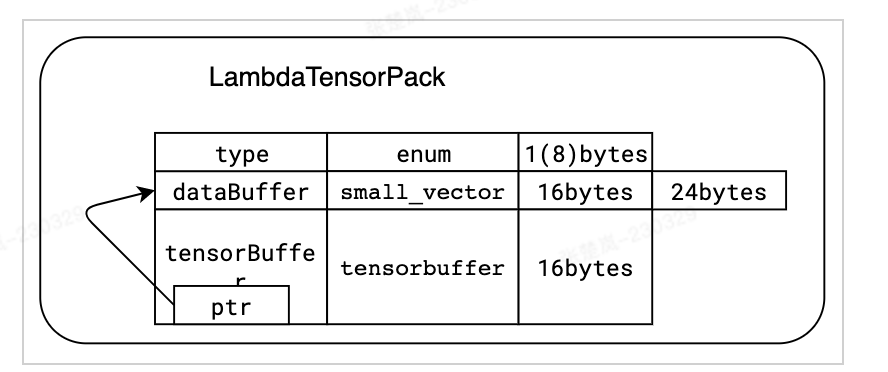 tensorflow::Tensor 形式と互換性があり、機能を tensorflow::SessionRun に渡す前にゼロコピーが作成されます。
tensorflow::Tensor 形式と互換性があり、機能を tensorflow::SessionRun に渡す前にゼロコピーが作成されます。
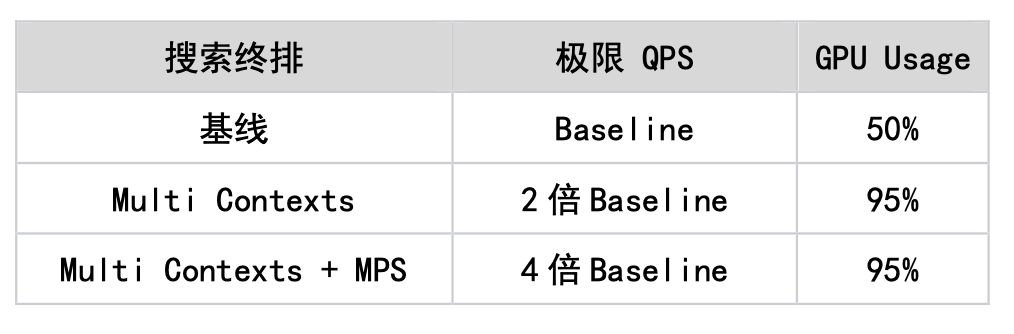
2. TensorFlow の単一 Cuda Stream の問題に対して、Multi Streams と Multi Contexts の機能をサポートし、ミューテックス ロックによるパフォーマンスのボトルネックを回避し、GPU 使用率を 90% まで高めることに成功しました。同時に、Nvidia が提供する Cuda MPS 機能を使用して GPU の空間分割多重化 (複数のカーネルの同時実行をサポート) を実現し、GPU の使用率をさらに向上させます。これに基づいて、検索のランキング モデルが GPU に正常に実装されました。さらに、ホームページのレイアウトや広告など、他の事業分野でも導入して成功しています。次の表は、検索順位シナリオにおける最適化の状況を示しています。
 写真
写真
3. Op/Kernel 融合テクノロジー: 手書きまたはグラフのコンパイルおよび最適化ツールを通じて、より高性能な Tensorflow オペレーターを生成し、 CPU キャッシュと GPU 共有メモリにより、システムのスループットが向上します。
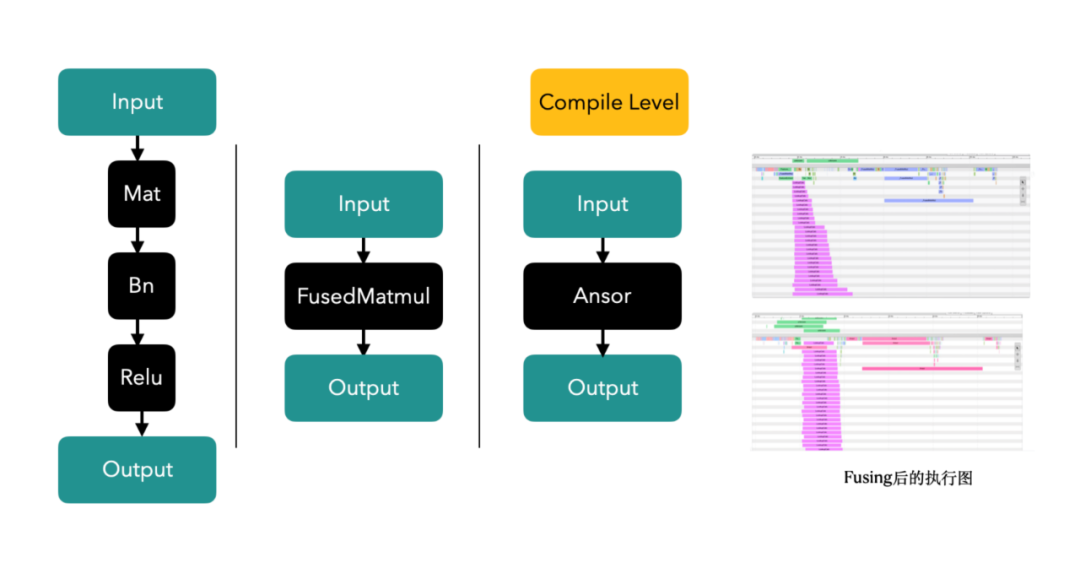 #写真
#写真
3.2.2 コンピューティング能力の無駄の回避#
#1. システム リンクには最適化の余地があります## a. 初期ランキング前 設定計算: ユーザー側で関連する計算を処理する場合、事前のソートのために大量のノートを計算する必要があります 例えば流出を例にとると、約 5,000 個のノートを計算する必要があり、ラムダスライス処理が施されています。計算の繰り返しを避けるために、最初の行のユーザー側の計算はリコールフェーズと並行して進められ、ユーザーベクトルの計算が複数回の繰り返しから 1 回のみに削減され、マシンの 40% が大まかな行シナリオで最適化されています。
2. 推論プロセスへのグラフ内トレーニング:
a. 計算の前処理: 計算の一部は、グラフのフリーズによって事前に処理できます。推論するときに、計算を繰り返す必要はありません。
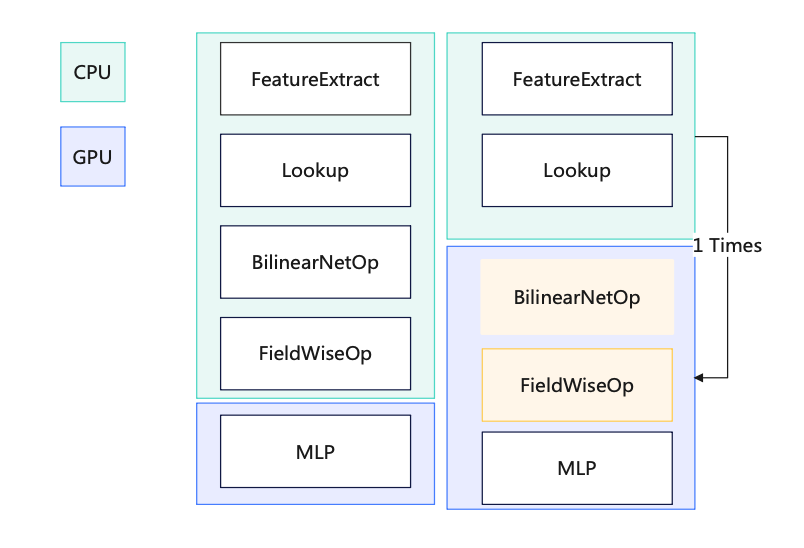
b. 出力モデルのフリーズ最適化: モデルが出力されると、すべてのパラメーターがグラフ自体とともに生成され、フリーズされたグラフ (フリーズ グラフ) が生成され、前処理計算が実行されます。 Const 演算子 (GPU 使用率が 12% 減少)c. 推論シナリオでの結合計算: 各バッチには 1 人のユーザーのみが含まれます。つまり、ユーザー側で多数の反復計算があり、マージの可能性d. CPU/GPU オペレーターの分割: ルックアップ後にすべてのオペレーターを GPU に移動し、CPU と GPU 間のデータ コピーを回避します e. GPU から CPU へのデータ コピー: データ パックを転送します1 つのコピー f. BilinearNet オペレーターの GPU cuda 実装: GPU を介して計算を加速してパフォーマンスを向上させる g. 一部のオペレーター GPU ベース: CPU -> GPU のコピーを排除 h. BatchNorm と MLP のマージ: 新しい MLP レイヤーを実装することで、GPU パスの数を減らし (N -> 1 )、1 回の計算の計算量を増やします (GPU スモール コアの同時実行機能を再利用します) ) #写真
##● 動的コンピューティングのダウングレードにより、1 日を通してリソースの使用効率が向上し、第 2 レベルでラムダ負荷の負のフィードバックを自動的に調整して正しい値を実現します。単一ゾーンのストレス テストの前にダウングレードの準備を手動で行う必要はありません。 # アウトバウンド絞り込みソート、アウトバウンド予備ソート、インバウンド絞り込みソート、内部流入予備ソート、検索などの主要なビジネス シナリオがすべて開始されました。
# 複数のビジネスラインにおけるキャパシティの問題を解決し、ビジネスの成長に伴うリソースの直線的な増加を効果的に軽減し、システムの堅牢性を大幅に向上させました。機能導入後の業務ラインでは、瞬間成功率の大幅低下によるP3以上の事故は発生していません。
# 1 日を通してのリソース使用効率が大幅に向上します。インストリーム微調整を例に取ると (下図に示すように)、メーデーの 3 日間の休暇中に使用される CPU コアの数は、 10:00 ~ 24:00 は 50 コアのまま、フラット ライン (ジッターはリリース バージョンに対応)
写真
 3.2.4 より優れたハードウェアへの変更
3.2.4 より優れたハードウェアへの変更
● A10 GPU のパフォーマンスは T4 GPU の 1.5 倍であり、同時に、A10 モデルには新世代の CPU が搭載されています。 T4モデル(Skylake、14nm)に比べ(icelake、10nm)、価格はT4モデルのみの1.2倍タイプです。今後はA30などのオンラインでの活用も検討していきます。
3.3 グラフの最適化図
 3.3.1 DL スタックの自動コンパイル最適化#########
3.3.1 DL スタックの自動コンパイル最適化#########
# BladeDISC は、MLIR に基づいた Alibaba の最新のオープンソース動的形状深層学習コンパイラです。Xiaohongshu の自動グラフ最適化部分は、このフレームワークから来ています (Blade 推論加速ライブラリは Apache 2.0 オープンソースで、あらゆるクラウドで使用できます。知的財産リスク) 。このフレームワークは、TF グラフのコンパイルの最適化 (ダイナミック シェイプ コンパイラー、スパース サブグラフの最適化を含む) を提供し、ビジネス シナリオによりよく適応できる独自のカスタマイズされた演算子の最適化を重ね合わせることができます。ストレス テストの単一マシン推論では、QPS を 20% 向上させることができます。
# このフレームワークの主要テクノロジー
(1) MLIR インフラストラクチャ
MLIR (Multi-Level Intermediate Representation ) は、開始されたオープンソース プロジェクトです。 Googleによる。その目的は、柔軟で拡張可能な多層 IR インフラストラクチャとコンパイラ ユーティリティ ライブラリを提供し、コンパイラと言語ツールの開発者に統一されたフレームワークを提供することです。
MLIR の設計は LLVM の影響を受けますが、LLVM とは異なり、MLIR は主に中間表現 (IR) の設計と拡張に焦点を当てています。 MLIR は、高レベル言語から低レベル ハードウェアまでのコンパイル プロセスをサポートできるマルチレベル IR 設計を提供し、豊富なインフラストラクチャ サポートとモジュラー設計アーキテクチャを提供することで、開発者は MLIR の機能を簡単に拡張できます。さらに、MLIR には強力な接着機能もあり、さまざまなプログラミング言語やツールと統合できます。 MLIR は、コンパイラおよび言語ツールの開発者に、コンパイルの最適化とコード生成を容易にする統合された柔軟な中間表現言語を提供する、強力なコンパイラ インフラストラクチャおよびツール ライブラリです。
(2) 動的形状のコンパイル
静的形状の制限により、深層学習モデルを作成する際に、各入力と出力の形状を事前に決定する必要があります。 、実行時に変更することはできません。これにより、深層学習モデルの柔軟性とスケーラビリティが制限されるため、動的形状をサポートする深層学習コンパイラが必要になります。
3.3.2 精度調整
● 量子化を実現する方法の 1 つは、FP16
を使用することです。FP16 計算の最適化:MLP レイヤーで FP32 計算を FP16 に置き換えることで、GPU 使用量を大幅に削減できます (相対的に 13% の減少)
FP16 を調整するプロセスで、精度の最適化にホワイト ボックス方式を選択しますつまり、どのレイヤーが低精度の計算を使用するかをより詳細に制御でき、経験に基づいて継続的に調整および最適化できるようになります。この手法はモデル構造を比較的深く理解して解析する必要があり、モデルの特性や計算要件に応じて的を絞った調整を行うことができ、より高いコストパフォーマンスを実現します。
これに対して、ブラック ボックス手法は比較的単純で、モデルの内部構造を理解する必要はなく、特定の許容しきい値を設定するだけで精度の最適化が完了します。この方法の利点は、操作が簡単で、モデルの生徒に対する要件が比較的低いことですが、特定のパフォーマンスと精度が犠牲になる可能性があります。
したがって、精度の最適化にホワイト ボックス手法を選択するかブラック ボックス手法を選択するかは、特定の状況に応じて決定する必要があります。より高いパフォーマンスと精度を追求する必要があり、十分な経験と技術力がある場合は、ホワイトボックスアプローチの方が適している可能性があります。操作の単純さと迅速な反復がより重要な場合は、ブラック ボックス アプローチの方が実用的である可能性があります。
2021 年の初めから 2022 年末までに、このプロジェクトの最適化により、Xiaohongshu の推論計算能力は 30 倍に増加し、主要なユーザー指標は 10 増加しました。 % になり、同時にクラスターの累積節約リソースも 50% に達しました。私たちの意見では、Xiaohongshu の AI テクノロジーの開発はビジネス ニーズを重視し、テクノロジーとビジネスの発展のバランスをとる必要があります。技術革新を達成する一方で、コスト、効率、持続可能性も考慮する必要があります。最適化プロセス中に考慮すべき点は次のとおりです。
アルゴリズムを最適化し、システムのパフォーマンスを向上させます。 これは、Xiaohongshu 機械学習チームの中核となる使命です。アルゴリズムを最適化し、システム化を改善することで、ビジネス ニーズをより適切にサポートし、ユーザー エクスペリエンスを向上させることができます。ただし、リソースが限られている場合、チームは最適化の焦点を明確にし、過剰な最適化を避ける必要があります。
#インフラストラクチャを構築し、データ処理機能を向上させます。 インフラストラクチャは、AI アプリケーションをサポートするために重要です。 Xiaohonshu は、コンピューティング機能とストレージ機能、データセンター、ネットワーク アーキテクチャを含むインフラストラクチャ構築へのさらなる投資を検討できます。さらに、機械学習およびデータ サイエンス アプリケーションをより適切にサポートするためにデータ処理機能を向上させることも非常に重要です。
チームの人材密度と組織構造を改善します。 優れた機械学習チームには、データ サイエンティスト、アルゴリズム エンジニア、ソフトウェア エンジニアなど、さまざまなスキルや背景を持つ人材が必要です。組織構造の最適化は、チームの効率とイノベーション能力の向上にも役立ちます。
Win-Winの協力とオープンイノベーション。 Xiaohongshu は引き続き他の企業、学術機関、オープンソース コミュニティと協力して AI テクノロジーの開発を共同で推進していきます。これにより、Xiaohongshu はより多くのリソースと知識を獲得し、よりオープンで革新的な組織になることができます。
このソリューションは、Xiaohongshu の機械学習アーキテクチャを業界トップレベルに引き上げます。今後も引き続きエンジンのアップグレードを推進し、コスト削減と効率の向上を図り、新技術を導入してXiaohongshuの機械学習の生産性を向上させ、Xiaohongshuの実際のビジネスシナリオをさらに統合し、単一モジュールの最適化からシステム全体の最適化にアップグレードしていきます。さらに、ビジネス側トラフィックのパーソナライズされた差別化特性を導入して、究極のコスト削減と効率の向上を実現します。高い理想を持った方の参加をお待ちしています!
Zhang Chulan (Du Zeyu): ビジネステクノロジー部
は華東師範大学を卒業し、責任者を務めています商用化エンジン チームの担当者で、主に商用オンライン サービスの構築を担当します。
Lu Guang (Peng Peng): インテリジェント流通部門
上海交通大学を卒業し、主に Lambda GPU の最適化を担当する機械学習エンジン エンジニアです。
Ian (Chen Jianxin): インテリジェント流通部門
北京郵電大学を卒業した機械学習エンジンのエンジニアで、主にラムダパラメータを担当していますサーバーとGPUの最適化。
赤羽 (Liu Zhaoyu) : インテリジェント流通部門
清華大学を卒業し、機械学習エンジンのエンジニアであり、主に関連する研究と探索を担当しています。機能エンジンの方向性。
特別な感謝: インテリジェント流通学科の学生の皆様
以上が計算能力がボトルネックにならないように、Xiaohongshu 機械学習異種ハードウェア推論最適化手法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



