つい先週、Alibaba Cloud との最終技術面接でクラスメートが次の質問をされました。 1 日あたり 100 万回のログイン リクエストと 8G メモリを備えたサービス ノード JVM パラメータを設定するにはどうすればよいですか? 答えが理想的ではないと思われる場合は、見直しのために私のところに来てください。
新しいビジネス システムでは、オンラインにする前に、サーバー構成と JVM メモリ パラメータを見積もる必要があります。この容量とリソースの計画は、は、システム設計者による単なるランダムな見積もりではなく、システムが配置されているビジネス シナリオに基づいて、システム運用モデルを推測し、JVM パフォーマンスや GC 頻度などの指標を評価して見積もる必要があります。以下は、ダニエルの経験と私自身の実践に基づいてまとめたモデリングのステップです:
2. ルーチンの実践 - システムへのログインを例にします
したがって、1 日あたり 100 万リクエストのログイン システムは、3 インスタンス クラスタに従って 4G ヒープ メモリと 2G 新世代 JVM を割り当てることでシステムを保証できると大まかに推測できます。通常負荷の4C8Gの構成。
基本的には新しいシステムのリソースを評価するため、新しいシステムを構築する場合、各インスタンスにどれだけの容量と構成が必要か、クラスター内にいくつのインスタンスが構成されるかなどは評価されません。頭と胸をなでるだけで、決断が下されます。
スループット = ユーザー アプリケーション実行時の CPU 時間 / (ユーザー アプリケーション実行時の CPU 時間、CPU ガベージ コレクション時間)
ヒープメモリが増えると、gcが一度に処理できる量が増えてスループットが高くなりますが、gcが一度に処理する時間が長くなり、処理時間が長くなります。後からキューに入れられたスレッドの待ち時間; 逆にヒープメモリが少ないとgc時間が短くなり、キューに入れられたスレッドの待ち時間が短くなり遅延は減りますが、一度のリクエスト数は少なくなります(完全に一致しているわけではありません)。
高スループットを必要とする大容量メモリ サービスには、G1 リサイクラーを使用してください。
CMS ガベージ コレクターの動作メカニズム
CMS は主に古い世代のコレクターです。古い世代はマークされ、クリアされます。デフォルトでは、 FullGC アルゴリズムの後に実行され、メモリの断片をクリーンアップするデフラグ アルゴリズム。
#CMS GC #1. 開始マーク##最初のマークは、GCRoot が直接関連付けることができるオブジェクトのみをマークします。これは非常に高速です
同時マーキング段階は、GCRoots トレースのプロセスです
再マーキング フェーズでは、ユーザー プログラムの継続的な動作により変更されたオブジェクトのその部分のマーキング レコードを修正します。同時マーキング。はい
もうすぐ
4. ガベージ コレクション
ガベージ オブジェクトの同時クリーニング (マークおよびクリア アルゴリズム) No
SLOW
利点: 「低遅延」に重点を置いた同時収集。最も時間のかかる 2 つのステージでは STW は発生せず、STW が必要なステージは非常に早く完了しました。 欠点: 1. CPU の消費、2. 浮遊ゴミ、3. メモリの断片化 適用可能なシナリオ: サーバーの応答速度と速度に注意してください。 require system 一時停止時間は最小限です。
要約:
ビジネス システム、遅延に敏感な推奨 CMS、
大規模なメモリ サービス、高要件 スループット、G1 コレクターを使用!
#ステップ 3: 各パーティションの比率とサイズを計画する方法 一般的な考え方は次のとおりです:
まず、 JVM が最も重要です コア パラメータはメモリと割り当てを評価することです。最初のステップはヒープ メモリのサイズを指定することです。これはシステムがオンラインのときに必要です。-Xms は初期ヒープ サイズ、-Xmx は最大ヒープ サイズですヒープ サイズ。バックグラウンド Java サービスでは、通常、システム メモリの半分として指定されます。大きすぎると、サーバーのシステム リソースを占有します。小さすぎると、JVM の最高のパフォーマンスを発揮できません。発揮した。
2 番目に、新しい世代の -Xmn のサイズを指定する必要があります。このパラメータは非常に重要であり、非常に柔軟です。Sun は公式に 3/8 のサイズを推奨していますが、ビジネス シナリオに従って決定する必要があります。ステートレス サービスまたはライト ステート サービス (現在、Web アプリケーションなどの最も一般的なビジネス システム) では、一般的に新世代にはヒープ メモリの 3/4 を与えることもできます。また、ステートフル サービス (IM サービス、ゲートウェイ アクセスなどの一般的なシステム) についても、レイヤーなど)、新しい世代はデフォルトの比率 1/3 に従って設定できます。サービスはステートフルです。つまり、メモリ内に常駐するローカル キャッシュとセッション状態の情報が増えるため、これらのオブジェクトを保存するために古い世代により多くの領域を設定する必要があります。
最後に、-Xss スタックのメモリ サイズを設定し、単一スレッドのスタック サイズを設定します。デフォルト値は JDK のバージョンとシステムに関連しており、一般にデフォルトは 512 ~ 1024kb です。バックグラウンド サービスに数百の常駐スレッドがある場合、スタック メモリも数百 M のサイズを占有することになります。
#JVM パラメータ #-Xms
Java ヒープ メモリ サイズ
OS メモリ 64/1
OS メモリの半分
Java ヒープ メモリの最大サイズ Java ヒープ メモリ内の新しい世代のサイズ。新しい世代を差し引いた後の残りのメモリ サイズは、古い世代のメモリ サイズです。 sun は 3/8 を推奨します
-Xss
各スレッドのスタック メモリ サイズ
idk に依存
sun
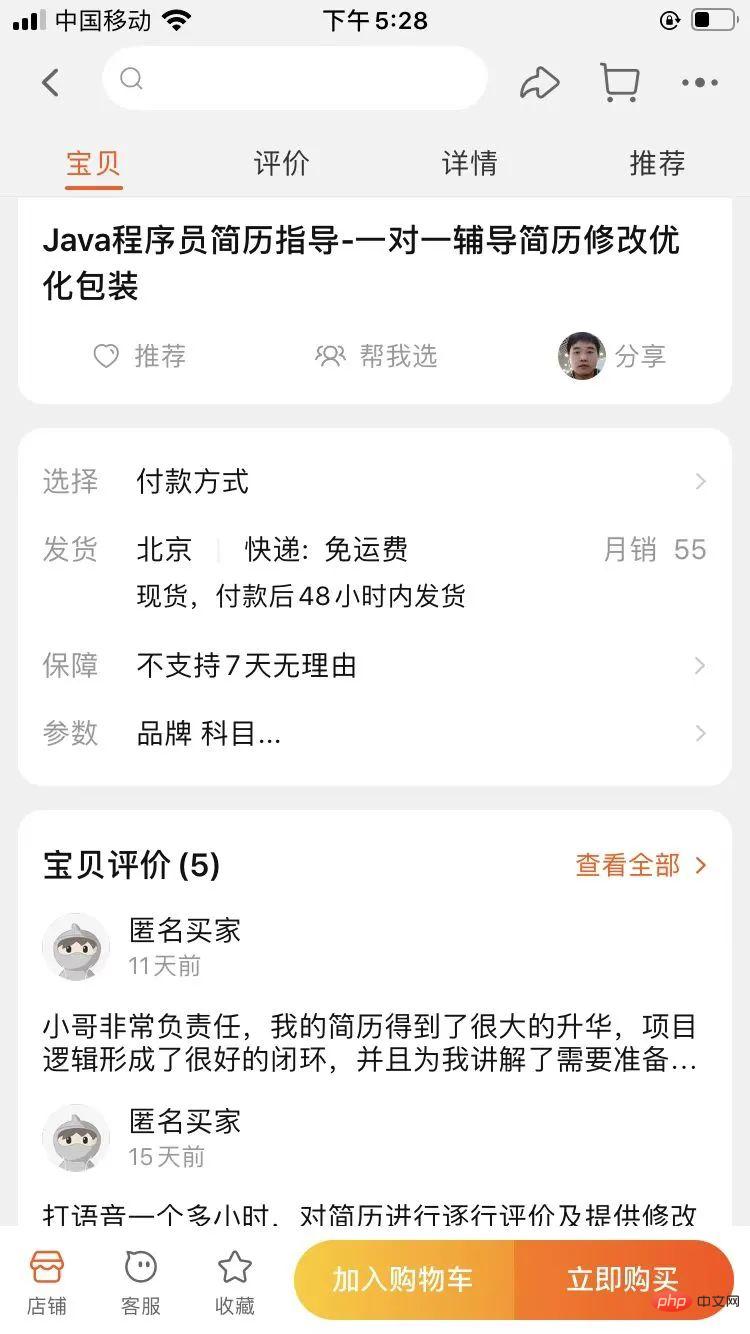
8G メモリの場合、マシンはまだ一定量のメモリを占有しているため、通常は最大メモリの半分を割り当てるだけで十分です。一般に、4G メモリは JVM に割り当てられます。パフォーマンス ストレス テスト。テストの学生は、ParNew CMS の複合リサイクラーを使用して、ログイン インターフェイスを 1 秒以内に 60M のオブジェクト生成速度で押しました。
通常の JVM パラメータ構成は次のとおりです:
-Xms3072M -Xmx3072M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8 ログイン後にコピー
この設定では、
動的なオブジェクトの年齢判断原理によりフルGCが頻繁に発生するため、問題が発生する可能性があります。なぜ?
この GC 中に、S1 に 100M がロードされた後、20 秒後に MinorGC が再度トリガーされると仮定します。S1 領域に残っている追加の 100M オブジェクトは、S2 領域に正常に配置できません。オブジェクトが古い世代にプッシュされ、一定期間実行され続けると、システムは 1 時間以内に FullGC をトリガーする可能性があります。
デフォルトの比率 8:1:1 に従って割り当てられた場合、残存領域は 1G の約 10% (数十から 100M) にすぎません。
如果 每次minor GC垃圾回收过后进入survivor对象很多,并且survivor对象大小很快超过 Survivor 的 50% , 那么会触发动态年龄判定规则,让部分对象进入老年代.
而一个GC过程中,可能部分WEB请求未处理完毕, 几十兆对象,进入survivor的概率,是非常大的,甚至是一定会发生的.
如何解决这个问题呢?为了让对象尽可能的在新生代的eden区和survivor区, 尽可能的让survivor区内存多一点,达到200兆左右,
于是我们可以更新下JVM参数设置:
-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8
说明:
‐Xmn2048M ‐XX:SurvivorRatio=8
年轻代大小2g,eden与survivor的比例为8:1:1,也就是1.6g:0.2g:0.2g ログイン後にコピー
survivor达到200m,如果几十兆对象到底survivor, survivor 也不一定超过 50%
这样可以防止每次垃圾回收过后,survivor对象太早超过 50% ,
这样就降低了因为对象动态年龄判断原则导致的对象频繁进入老年代的问题,
JVM の動的な年齢決定ルールとは何ですか?
古い世代に入るオブジェクトの動的年齢判定ルール (動的昇格年齢計算しきい値): マイナー GC 中に、Survivor 内の年齢 1 から N までのオブジェクトのサイズが Survivor の 50% を超えるとき、その後、年齢が N 以上のオブジェクトを古い世代に置きます。
中核となる最適化戦略は、短期的に存続するオブジェクトを可能な限り存続環境内に保持し、古い世代に入らないようにすることです。このようにして、これらのオブジェクトはマイナー gc 中にリサイクルされ、再利用されなくなります。古い世代を入力すると、完全な gc になります。
新世代のメモリを評価し、適切に割り当てるにはどうすればよいでしょうか?
最初のステップは、ヒープ メモリのサイズを指定することです。これが、 -Xms 初期ヒープ サイズ、-Xmx 最大ヒープ サイズ、
バックグラウンド Java サービスでは、通常、システム メモリの半分として指定されます。大きすぎる場合は、サーバーのシステムリソースを占有し、小さすぎるとJVMの最高のパフォーマンスを発揮できません。
2 番目に、新しい世代の -Xmn のサイズを指定する必要があります。このパラメータは非常に重要で、柔軟性が非常に優れています。Sun は公式に 3/8 のサイズを推奨していますが、次の規定に従って決定する必要があります。ビジネス シナリオ:
ステートレス サービスまたはライト ステート サービス (Web アプリケーションなど、現在最も一般的なビジネス システム) の場合、一般に、新世代にはヒープ メモリ サイズの 3/4 を与えることもできます。 ステートフル サービス (IM サービス、ゲートウェイ アクセス層などの一般的なシステム) の場合、新しい世代はデフォルトの比率 1/3 に従って設定できます。
サービスはステートフルです。つまり、より多くのローカル キャッシュとセッション状態情報がメモリに常駐します。これは、古い世代がこれらを保存するためにより多くの領域を設定するためであるはずです。オブジェクト。
step4: 適切なスタック メモリ サイズはどれくらいですか? -Xss スタック メモリ サイズ: シングル スレッドのスタック サイズを設定します。デフォルト値は JDK のバージョンとシステムに関連しており、一般にデフォルトは 512 ~ 1024kb です。バックグラウンド サービスに数百の常駐スレッドがある場合、スタック メモリも数百 M のサイズを占有することになります。
step5: オブジェクトを古い世代に移動するのが適切になるまでのオブジェクトの経過時間はどれくらいですか? マイナー gc には 20 ~ 30 秒かかり、通常、ほとんどのオブジェクトは数秒以内にガベージになると仮定します。たとえば、リサイクルが 2 分間行われなかった場合、これらのオブジェクトは比較的長期間存続すると考えられるため、存続エリアのスペースを占有し続けるのではなく、古い世代に移動されます。
所以,可以将默认的15岁改小一点,比如改为5,
那么意味着对象要经过5次minor gc才会进入老年代,整个时间也有一两分钟了(5*30s= 150s),和几秒的时间相比,对象已经存活了足够长时间了。
所以:可以适当调整JVM参数如下:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5 ログイン後にコピー
step6:多大的对象,可以直接到老年代比较合适? 对于多大的对象直接进入老年代(参数-XX:PretenureSizeThreshold),一般可以结合自己系统看下有没有什么大对象 生成,预估下大对象的大小,一般来说设置为1M就差不多了,很少有超过1M的大对象,
所以:可以适当调整JVM参数如下:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5 ‐XX:PretenureSizeThreshold=1M ログイン後にコピー
step7:垃圾回收器CMS老年代的参数优化 JDK8默认的垃圾回收器是-XX:+UseParallelGC(年轻代)和-XX:+UseParallelOldGC(老年代),
如果内存较大(超过4个G,只是经验 值),还是建议使用G1.
这里是4G以内,又是主打“低延时” 的业务系统,可以使用下面的组合:
ParNew+CMS(-XX:+UseParNewGC -XX:+UseConcMarkSweepGC) ログイン後にコピー
新生代的采用ParNew回收器,工作流程就是经典复制算法,在三块区中进行流转回收,只不过采用多线程并行的方式加快了MinorGC速度。
老生代的采用CMS。再去优化老年代参数 :比如老年代默认在标记清除以后会做整理,还可以在CMS的增加GC频次还是增加GC时长上做些取舍,
如下是响应优先的参数调优:
XX:CMSInitiatingOccupancyFraction=70 ログイン後にコピー
设定CMS在对内存占用率达到70%的时候开始GC(因为CMS会有浮动垃圾,所以一般都较早启动GC)
XX:+UseCMSInitiatinpOccupancyOnly ログイン後にコピー
和上面搭配使用,否则只生效一次
-XX:+AlwaysPreTouch ログイン後にコピー
强制操作系统把内存真正分配给IVM,而不是用时才分配。
综上,只要年轻代参数设置合理,老年代CMS的参数设置基本都可以用默认值,如下所示:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5 ‐XX:PretenureSizeThreshold=1M ‐XX:+UseParNewGC ‐XX:+UseConcMarkSweepGC ‐XX:CMSInitiatingOccupancyFraction=70 ‐XX:+UseCMSInitiatingOccupancyOnly ‐XX:+AlwaysPreTouch ログイン後にコピー
参数解释
1.‐Xms3072M ‐Xmx3072M 最小最大堆设置为3g,最大最小设置为一致防止内存抖动
2.‐Xss1M 线程栈1m
3.‐Xmn2048M ‐XX:SurvivorRatio=8 年轻代大小2g,eden与survivor的比例为8:1:1,也就是1.6g:0.2g:0.2g
4.-XX:MaxTenuringThreshold=5 年龄为5进入老年代 5.‐XX:PretenureSizeThreshold=1M 大于1m的大对象直接在老年代生成
6.-XX: UseParNewGC -XX: UseConcMarkSoupGC ParNew cms ガベージ コレクターの組み合わせを使用します
7.-XX:CMSInitiatingOccupancyFraction=70 古い世代のオブジェクトこの比率に達すると、fullgc がトリガーされます。
8.-XX: UseCMSInitiatinpOccupancyOnly 古い世代のオブジェクトがこの比率に達すると、毎回
##9 で fullgc がトリガーされます。 .‐XX : AlwaysPreTouch オペレーティング システムが、使用時にメモリを割り当てるのではなく、実際に IVM にメモリを割り当てるように強制します。
#step8: OOM 構成時のメモリ ダンプ ファイルと GC ログ 問題のトラブルシューティングに役立つように、GC ログの印刷や OOM 自動ダンプなどの追加の構成コンテンツが追加されました
-XX:+HeapDumpOnOutOfMemoryError ログイン後にコピー
在Out Of Memory,JVM快死掉的时候,输出Heap Dump到指定文件。
不然开发很多时候还真不知道怎么重现错误。
路径只指向目录,JVM会保持文件名的唯一性,叫java_pid${pid}.hprof。
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=${LOGDIR}/ ログイン後にコピー
因为如果指向特定的文件,而文件已存在,反而不能写入。
输出4G的HeapDump,会导致IO性能问题,在普通硬盘上,会造成20秒以上的硬盘IO跑满,
需要注意一下,但在容器环境下,这个也会影响同一宿主机上的其他容器。
GC的日志的输出也很重要:
-Xloggc:/dev/xxx/gc.log
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails ログイン後にコピー
GC的日志实际上对系统性能影响不大,打日志对排查GC问题很重要。
一份通用的JVM参数模板
一般来说,大企业或者架构师团队,都会为项目的业务系统定制一份较为通用的JVM参数模板,但是许多小企业和团队可能就疏于这一块的设计,如果老板某一天突然让你负责定制一个新系统的JVM参数,你上网去搜大量的JVM调优文章或博客,结果发现都是零零散散的、不成体系的JVM参数讲解,根本下不了手,这个时候你就需要一份较为通用的JVM参数模板了,不能保证性能最佳,但是至少能让JVM这一层是稳定可控的,
在这里给大家总结了一份模板:
基于4C8G系统的ParNew+CMS回收器模板(响应优先),新生代大小根据业务灵活调整!
-Xms4g
-Xmx4g
-Xmn2g
-Xss1m
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=10
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=70
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+AlwaysPreTouch
-XX:+HeapDumpOnOutOfMemoryError
-verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-Xloggc:gc.log ログイン後にコピー
如果是GC的吞吐优先,推荐使用G1,基于8C16G系统的G1回收器模板:
G1收集器自身已经有一套预测和调整机制了,因此我们首先的选择是相信它,
即调整-XX:MaxGCPauseMillis=N参数,这也符合G1的目的——让GC调优尽量简单!
同时也不要自己显式设置新生代的大小(用-Xmn或-XX:NewRatio参数),
如果人为干预新生代的大小,会导致目标时间这个参数失效。
-Xms8g
-Xmx8g
-Xss1m
-XX:+UseG1GC
-XX:MaxGCPauseMillis=150
-XX:InitiatingHeapOccupancyPercent=40
-XX:+HeapDumpOnOutOfMemoryError
-verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-Xloggc:gc.log ログイン後にコピー
G1参数
描述
默认值
XX:MaxGCPauseMillis=N
最大GC停顿时间。柔性目标,JVM满足90%,不保证100%。
200
-XX:nitiatingHeapOccupancyPercent=n
当整个堆的空间使用百分比超过这个值时,就会融发MixGC
45
-XX:MaxGCPauseMillis の場合、パラメーター設定には明らかな傾向があります。↓が低い: レイテンシは低くなりますが、MinorGC が頻繁に発生し、古い領域の MixGC リサイクルが少なくなり、大規模な Full GC のリスクが増加します。 。 ↑を大きくすると、一度にリサイクルされるオブジェクトの数が増えますが、システム全体の応答時間も長くなります。
InitiatingHeapOccupancyPercent の場合、パラメーター サイズを調整する効果も異なります。↓を下げると、MixGC がより早くトリガーされ、CPU が無駄になります。 ↑を増やす: 複数世代のリサイクル領域が蓄積され、FullGC のリスクが増加します。
チューニングの概要 システムをオンラインにする前の包括的なチューニングのアイデア:
1. ビジネスの見積もり: 予想される同時実行性に基づく、平均メモリ要件次に、各タスクの評価、そのタスクをホストするために必要なマシンの数、各マシンに必要な構成が評価されます。
2. 容量の見積もり: システムのタスク処理速度に応じて、Eden 領域と Survior 領域のサイズ、および旧世代のメモリ サイズを合理的に割り当てます。
3. リサイクラーの選択: 応答優先のシステムの場合は、ParNew CMS リサイクラーを使用することをお勧めします。スループット優先のマルチコアの大容量メモリ (ヒープ サイズ ≥ 8G) サービスの場合は、ParNew CMS リサイクラーを使用することをお勧めします。 G1リサイクル業者。
4. 最適化のアイデア: 存続期間の短いオブジェクトを MinorGC ステージでリサイクルさせます (同時に、リサイクル後に存続するオブジェクトが Survivor 領域の
5. これまでにまとめたチューニング プロセスは、主にオンラインにする前のテストと検証段階に基づいているため、オンラインにする前にマシンの JVM パラメータを最適な値に設定しようとします。
JVM チューニングは単なる手段ですが、JVM チューニングによってすべての問題を解決できるわけではありません。ほとんどの Java アプリケーションは JVM の最適化を必要としません。次の原則のいくつかに従うことができます:
オンラインにする前に、まずマシンの JVM パラメーターを最適なレベルに設定することを検討する必要があります。
作成されるオブジェクトの数 (コード レベル) を減らす;
グローバル変数とラージ オブジェクトの使用を減らします (コード レベル); アーキテクチャのチューニングとコードのチューニングを優先し、JVM の最適化は最後の手段です (コード レベル)。 、アーキテクチャ レベル); #JVM パラメーター (コード レベル) を最適化するよりも、GC 状況を分析してコードを最適化する方が良いです。
#上記の原則を通じて、実際には、最も効果的な最適化方法はアーキテクチャとコードレベルの最適化であり、JVM の最適化は最後の手段であり、最後の「絞り」とも言えることがわかりました。サーバー構成の。
ZGCとは何ですか? ZGC (Z Garbage Collector) は、低遅延を主な目標として Oracle によって開発されたガベージ コレクターです。
これは、動的なリージョン メモリ レイアウトに基づいたコレクタであり、(一時的に) age 生成はなく、読み取りバリア、染色ポインタ、メモリ多重マッピングなどのテクノロジを使用して、同時マークソート アルゴリズムを実装します。
JDK 11 に新たに追加されましたが、まだ実験段階です。
主な機能は、テラバイトのメモリ (最大 4T) をリサイクルし、一時停止時間が 10 ミリ秒を超えないことです。
利点: 短い一時停止、高スループット、ZGC コレクション中に消費される余分なメモリがほとんどない
欠点: 浮遊ガベージ
現在はほとんど使用されていませんが、本当に普及するにはまだ必要です時間を書きます。
ガベージ コレクターを選択するにはどうすればよいですか? 実際のシナリオではどのように選択すればよいでしょうか? 以下にいくつかの提案がありますので、お役に立てれば幸いです:
1. ヒープ サイズがそれほど大きくない場合 (たとえば、 100MB) の場合、通常はシリアル コレクターを選択するのが最も効率的です。パラメータ: -XX:SerialGC を使用します。
2. アプリケーションがシングルコア マシンで実行されている場合、または仮想マシンにシングル コアしかない場合でも、シリアル コレクターを選択することが適切です。現時点では、いくつかの機能を有効にする必要はありません。パラレルコレクターの収入です。パラメータ: -XX:SerialGC を使用します。
3. アプリケーションが「スループット」を優先し、長い一時停止に対する特別な要件がない場合。パラレルコレクターを選択することをお勧めします。パラメータ: -XX: ParallelGC を使用します。
4. アプリケーションの応答時間要件が高く、一時停止を少なくしたい場合。 1 秒の一時停止でも大量のリクエストが失敗するため、G1、ZGC、または CMS を選択するのが合理的です。これらのコレクターの GC 一時停止時間は通常は短くなりますが、作業を処理するために追加のリソースが必要となり、スループットは通常より低くなります。パラメータ: -XX: UseConcMarkSoupGC、-XX: UseG1GC、-XX: UseZGC など。上記の出発点から、通常の Web サーバーには応答性に対する非常に高い要件があります。
実際には、選択性は CMS、G1、および ZGC に重点が置かれています。スケジュールされたタスクによっては、並列コレクターを使用する方が適切な選択となります。
Hotspot はなぜ永続世代を置き換えるためにメタスペースを使用したのですか? メタスペースとは何ですか?永続世代とは何ですか?なぜ永続生成ではなくメタスペースを使用するのでしょうか?
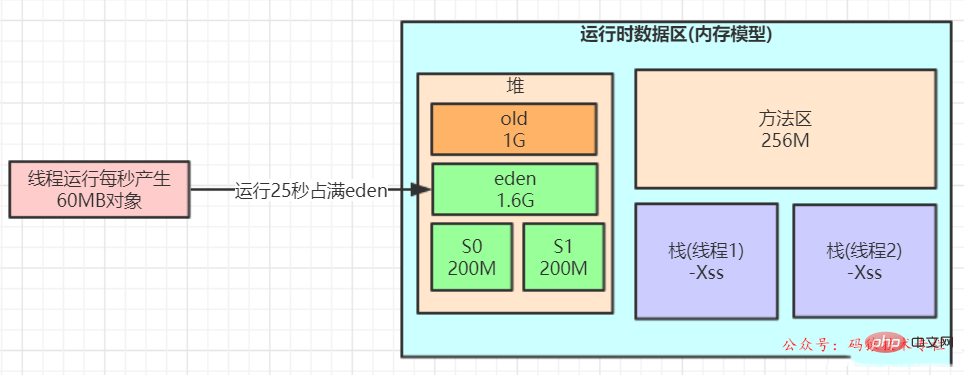
最初に メソッド領域 を確認し、次のように仮想マシンの実行時のデータ メモリ グラフを見てみましょう。
メソッド領域は、ヒープと同様に各スレッドが共有するメモリ領域で、クラス情報、定数、静的変数、即時にコンパイルされたコードなどを格納するために使用されます。仮想マシンによってロードされたデータ。
永続世代とは何ですか?メソッド領域とどのような関係があるのでしょうか?
HotSpot 仮想マシンで開発およびデプロイする場合、多くのプログラマーはメソッド領域を永続世代と呼びます。
メソッド領域は仕様であり、永続生成は Hotspot による仕様の実装であると言えます。
Java7 以前のバージョンでは、メソッド領域は永続世代で実装されていました。
メタスペースとは何ですか?メソッド領域とどのような関係があるのでしょうか?
Java8 の場合、HotSpots は永続的な生成をキャンセルし、メタスペースに置き換えました。
言い換えると、メソッド領域はまだ存在しますが、実装は永続的な世代からメタスペースに変更されました。
なぜ永続世代がメタスペースに置き換えられるのですか?
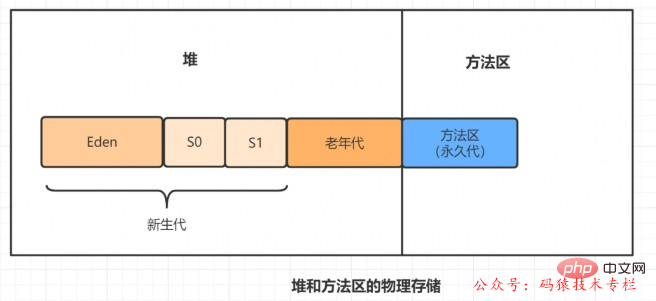
永続世代のメソッド領域は、ヒープが使用する物理メモリと連続しています。
#永続世代は、次の 2 つのパラメータを通じて構成されます~
-XX:PremSize: 永続世代の初期サイズを設定します -XX:MaxPermSize : 永続世代の最大値を設定します。デフォルトは 64M
永続世代 の場合、多くのクラスが動的に生成される場合、java.lang永続世代スペースの構成には制限があるため、.OutOfMemoryError :PermGen space error が発生する可能性があります。最も一般的なシナリオは、Web 開発で多数の JSP ページが存在する場合です。
JDK8以降、メソッド領域はメタスペース(Metaspace)に存在します。
物理メモリはヒープと連続していませんが、ローカル メモリに直接存在します。理論的には、マシンメモリのサイズはメタスペース のサイズです。
次のパラメータを使用してメタスペースのサイズを設定できます:
-XX:MetaspaceSize、初期スペース サイズ。この値に達すると、型のアンロードのためにガベージ コレクションがトリガーされ、GC が値を調整します。解放されるスペースの量 スペースが少ない場合は、値を適切に下げます。解放されるスペースがほとんどない場合は、MaxMetaspaceSize を超えない範囲で値を適切に増やします。 -XX:MaxMetaspaceSize、最大スペース。デフォルトでは制限はありません。
#-XX:MinMetaspaceFreeRatio、GC 後、割り当てられたスペースによって発生するガベージ コレクションに換算される、メタスペースの残りのスペース容量の最小パーセンテージ
-XX:MaxMetaspaceFreeRatio、GC 後、スペースの解放によって発生するガベージ コレクションに換算される、メタスペースの最大残りスペース容量のパーセンテージ それでは、なぜメタスペースを使用して永続世代を置き換えるのでしょうか?
表面的には、OOM 例外を回避するためです。
通常、PermSize と MaxPermSize は永続世代のサイズを設定するために使用され、永続世代の上限を決定しますが、どのくらいの大きさに設定すべきかを常に知ることができるわけではありません。デフォルト値を使用すると、OOM エラーが発生しやすくなります。
メタスペースを使用する場合、ロードできるメタデータのクラスの数は、MaxPermSize ではなく、システムの実際の利用可能なスペースによって制御されます。
ストップ ザ ワールドとは何ですか? OopMap とは何ですか?安全な場所とは何ですか? ガベージ コレクションのプロセスにはオブジェクトの移動が含まれます。
オブジェクト参照の更新の正確性を確保するには、すべてのユーザー スレッドを一時停止する必要があります。このような一時停止は、仮想マシン設計者によって Stop The World と表現されます。 STWとも呼ばれます。
HotSpotには、OopMap と呼ばれるデータ構造(マッピングテーブル)があります。
クラス読み込みアクションが完了すると、HotSpot はオブジェクト内のどのオフセットにどのようなタイプのデータがあるかを計算し、それを OopMap に記録します。
ジャストインタイム コンパイル プロセス中に、特定の場所 で OopMap も生成され、スタックおよびレジスター上のどの場所が参照であるかを記録します。
これらの特定の位置は主に次のとおりです。 1. ループの終わり (カウントされないループ)
2. メソッドが戻る前 / メソッドの呼び出し命令を呼び出した後
3. 例外がスローされる可能性がある場所
これらの場所は セーフポイントと呼ばれます。
ユーザー プログラムの実行時、コード命令フローの任意の位置でガベージ コレクションを一時停止したり開始したりすることはできませんが、一時停止する前に安全なポイントまで実行する必要があります。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



