


現在、大規模言語モデル (LLM) は、自然言語処理 (NLP) の分野に大きな変化の波を引き起こしています。 LLM には強力な創発能力があり、複雑な言語理解タスク、生成タスク、さらには推論タスクでもうまく機能することがわかります。これにより、人々は機械学習の別のサブフィールドであるコンピューター ビジョン (CV) における LLM の可能性をさらに探求するようになりました。
LLM の優れた才能の 1 つは、状況に応じて学習する能力です。コンテキスト学習は LLM のパラメーターを更新しませんが、さまざまな NLP タスクで驚くべき結果を示します。では、GPT は状況に応じた学習を通じて視覚的なタスクを解決できるのでしょうか?
最近、Google とカーネギー メロン大学 (CMU) の研究者が共同で発表した論文は、画像 (または他の非言語モダリティ) を言語に変換できる限り、それを言語に翻訳できることを示しています。 LLM が理解できるので、これは実現可能だと思われます。
 #写真
#写真
論文アドレス: https://arxiv.org/abs/2306.17842
この論文では、文脈学習を通じて視覚タスクを解決する PaLM または GPT の能力を明らかにし、新しい手法 SPAE (Semantic Pyramid AutoEncoder) を提案します。この新しいアプローチにより、LLM はパラメータを更新せずにイメージ生成タスクを実行できるようになります。これは、コンテキスト学習を使用して LLM が画像コンテンツを生成できるようにする最初の成功した方法でもあります。
まず、コンテキスト学習による画像コンテンツの生成に対する LLM の実験的効果を見てみましょう。
#たとえば、この論文では、特定のコンテキストで 50 枚の手書きの画像を提供することで、出力としてデジタル画像を生成する必要がある複雑なクエリに答えるように PaLM 2 に求めています。#Pictures
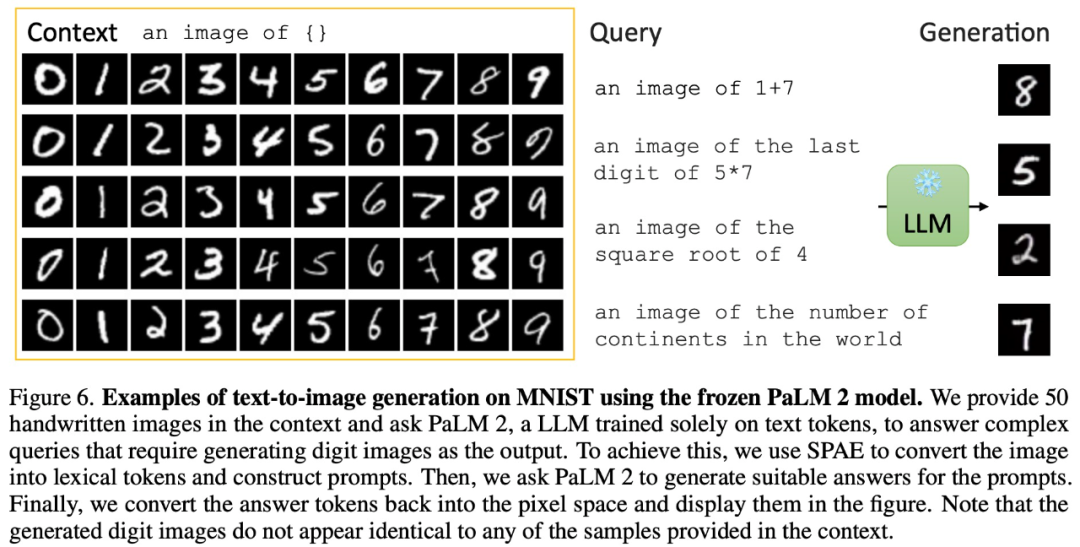 は、画像コンテキスト入力を使用して現実的な画像を生成することもできます。
は、画像コンテキスト入力を使用して現実的な画像を生成することもできます。
Picture
 画像の生成に加えて、コンテキスト学習を通じて、PaLM 2 は画像の説明も実行できます。
画像の生成に加えて、コンテキスト学習を通じて、PaLM 2 は画像の説明も実行できます。
# #画像関連の質問に対する視覚的な Q&A もあります:

写真
 ノイズ除去を使用してビデオを生成することもできます:
ノイズ除去を使用してビデオを生成することもできます:
画像
 メソッドの概要
メソッドの概要
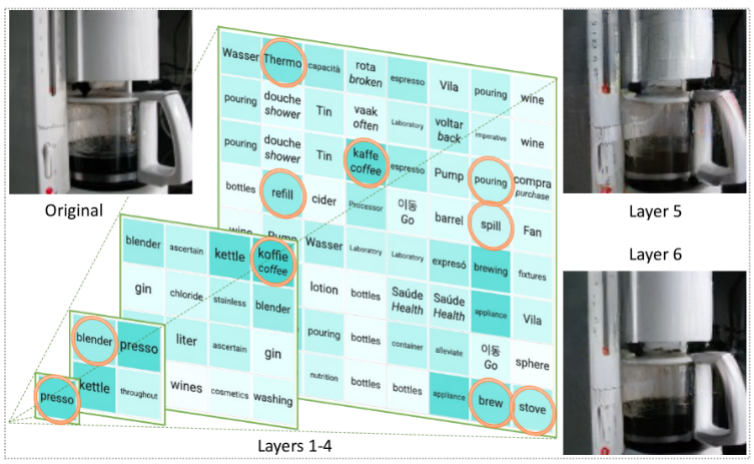
このアプローチは、テキストで満たされた塔を構築し、画像のセマンティクスと詳細をキャプチャするようなものです。このテキストで埋められた表現により、画像の説明を簡単に生成できるようになり、LLM が画像関連の質問に答えたり、画像のピクセルを再構築したりすることもできます。
具体的には、この研究では、トレーニングされたエンコーダーと CLIP モデルを使用して画像をトークン空間に変換し、LLM を使用してトークン空間を生成することを提案しています。適切な語彙トークン、最後にトレーニングされたデコーダを使用してこれらのトークンをピクセル空間に変換します。この独創的なプロセスにより、画像が LLM が理解できる言語に変換され、視覚タスクで LLM の生成力を活用できるようになります。
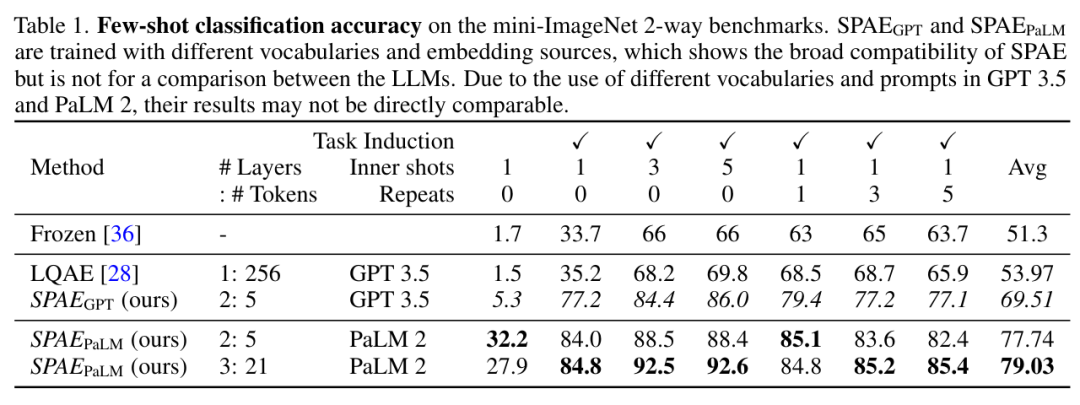
この研究では、SPAE と SOTA 手法である Frozen および LQAE を実験的に比較しました。結果を以下の表 1 に示します。 SPAEGPT は、トークンの 2% のみを使用しながら、すべてのタスクで LQAE よりも優れたパフォーマンスを示します。
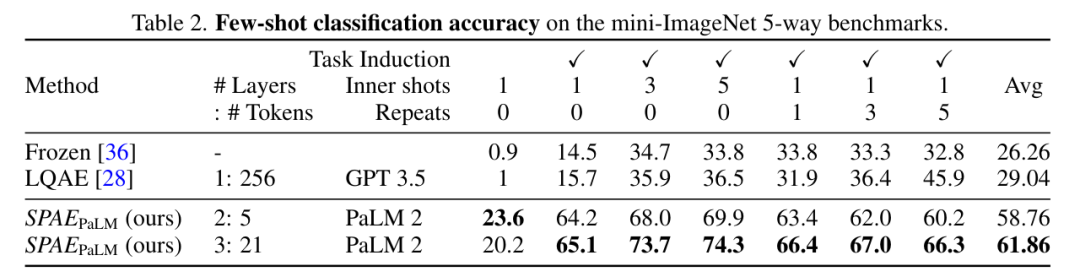
 写真
写真
全体的に、mini-ImageNet ベンチマークでのテストでは、SPAE メソッドが以前の SOTA よりも優れていることがわかりました。このメソッドによりパフォーマンスが向上しました。 25%増加します。
 写真
写真
SPAE設計法の有効性を検証するために、本研究ではアブレーション実験を実施しました。表 4 および図 10 に示すとおりです。# 興味を持った読者は、論文の原文を読んで研究内容をさらに詳しく知ることができます。
以上が大規模な言語モデルの視覚的才能: GPT は文脈学習を通じて視覚的なタスクも解決できますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



