


アクティベーション、重み、勾配を 4 ビットに量子化することで、ニューラル ネットワークのトレーニングの高速化が期待されます。
ただし、既存の 4 桁のトレーニング方法では、最新のハードウェアではサポートされていないカスタム数値形式が必要です。
最近、Tsinghua Zhu Jun のチームは、INT4 アルゴリズムを使用してすべての行列乗算を実装する Transformer トレーニング方法を提案しました。
超低い INT4 精度でのトレーニングは非常に困難です。この目標を達成するために、研究者は Transformer の活性化と勾配の特定の構造を注意深く分析し、それら専用の量子化器を提案しました。
順伝播の場合、研究者らは外れ値の課題を特定し、外れ値を抑制するアダマール量子化器を提案しました。
逆方向伝播の場合、彼らはビット分割を提案することで勾配の構造的疎性を利用し、分数サンプリング技術を利用して勾配を正確に定量化します。
この新しいアルゴリズムは、自然言語理解、機械翻訳、画像分類などの幅広いタスクで優れた精度を実現します。
プロトタイプの線形演算子は、FP16 の同様の演算子よりも 2.2 倍高速で、トレーニング速度は 35.1% 増加しました。
 #写真
#写真
論文アドレス: https://arxiv.org/abs/2306.11987
##コード アドレス: https://github.com/xijiu9/Train_Transformers_with_INT4新しい INT 4 トレーニング アルゴリズム
FQT メソッドは、元の完全精度計算グラフにいくつかの量子化器と逆量子化器を追加し、高コストの浮動小数点演算を消費量の少ない低精度の浮動小数点演算に置き換えます。 . ポイント操作。
FQT に関する研究は、収束速度や精度をあまり犠牲にすることなく、トレーニングの数値精度を下げることを目的としています。
必要な数値精度は、FP16 から FP8、INT32 INT8、INT8 INT5 に減少しました。
FP8 トレーニングは、Transformer エンジンを備えた Nvidia H100 GPU に実装されており、大規模な Transformer のトレーニングを加速します。最近のトレーニング数値精度は4桁まで低下しました。
ただし、これらの 4 ビット トレーニング方法は、最新のハードウェアではサポートされていないカスタム数値形式を必要とするため、アクセラレーションに直接使用することはできません。
まず第一に、順伝播における非微分可能量子化器は損失状況を不安定にし、勾配ベースのオプティマイザは容易に局所最適に陥る可能性があります。
第 2 に、勾配は低精度で近似的にのみ計算されます。このような不正確な勾配により、トレーニング プロセスが遅くなり、トレーニングが不安定になったり、発散したりする可能性もあります。
この研究では、研究者らは、Transformer 用の新しい INT4 トレーニング アルゴリズムを提案しました。
図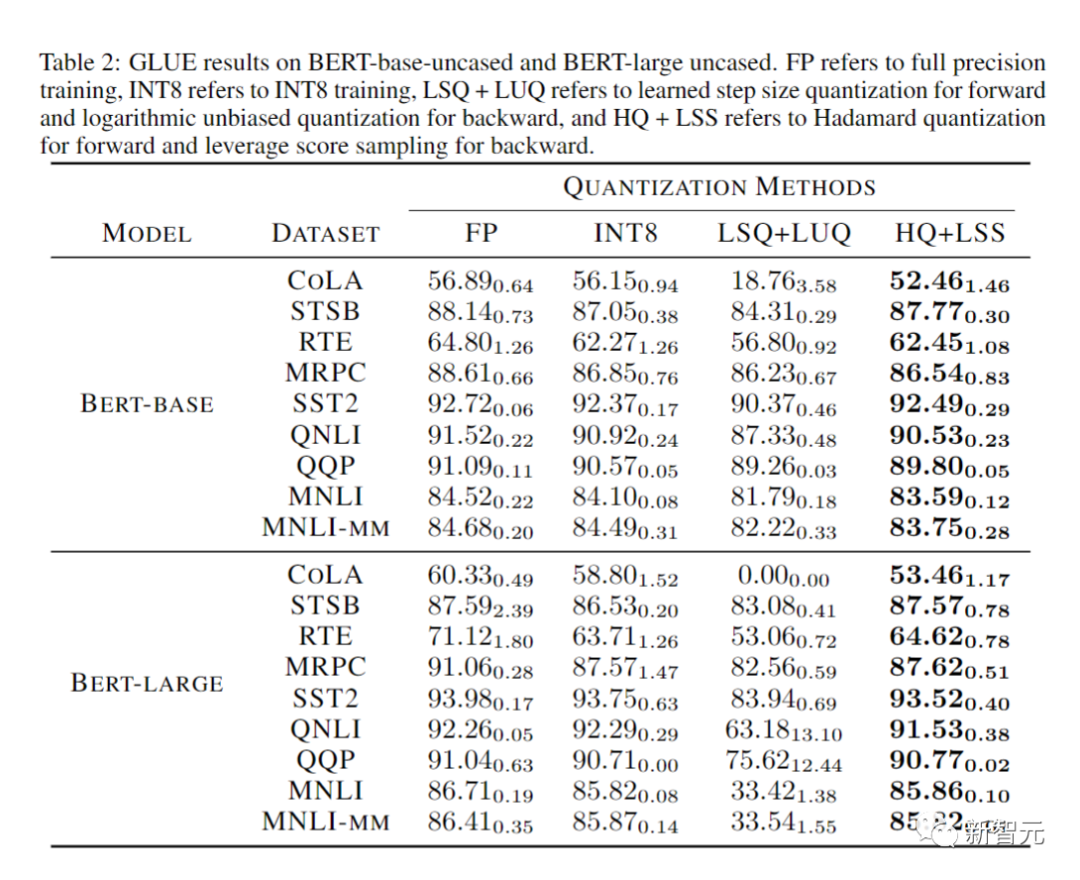
この MM 形式を使用すると、Transformer のアクティベーション、重み、および勾配の特定の構造を利用して、FP32 行列の乗算をより適切に近似できる、より柔軟な量子化器を設計できます。
ランダム数値線形代数 (RandNLA) 分野の進歩は、この量子化器によって最大限に活用されます。
順伝播の場合、研究者らは、活性化の異常値が精度低下の主な原因であることを発見しました。
異常値を抑制するために、彼らは活性化行列の変換されたバージョンを量子化するアダマール量子化器を提案しました。この変換はブロック対角アダマール行列であり、外れ値に含まれる情報を行列の隣接するエントリに伝播し、それによって外れ値の数値範囲を狭めます。
バックプロパゲーションの場合、活性化勾配の構造的疎性を利用します。研究者らは、一部のトークンの勾配が非常に大きいことを発見しました。同時に、他のほとんどのトークンの勾配は非常に均一であり、大きな勾配の量子化された残差よりもさらに均一です。
したがって、すべての勾配を計算するよりも、より大きな勾配の残差を計算することで計算リソースを節約する方が良いでしょう。 この疎性を利用するために、研究者らは、各トークンの勾配を上位 4 ビットと下位 4 ビットに分割するビット分割を提案しました。 次に、RandNLA の重要なサンプリング手法であるレバレッジ スコア サンプリングを通じて、最も有益な勾配が選択されます。 順伝播と逆伝播の定量化技術を組み合わせて、研究者は、トランスフォーマー アルゴリズムに INT4MM を使用する方法を提案しました。すべての線形演算を実行し、自然言語理解、質問応答、機械翻訳、画像分類などのさまざまなタスクで Transformer をトレーニングするためのアルゴリズムを評価します。 彼らのアルゴリズムは、既存の 4 ビット トレーニング アルゴリズムと比較して、同等以上の精度を実現します。 さらに、このアルゴリズムは、FP4 や対数形式などのカスタム数値形式を必要としないため、GPU などの最新のハードウェアと互換性があります。 このプロトタイプの量子化 INT4 MM オペレーター実装は、FP16MM ベースラインより 2.2 倍高速で、トレーニング速度が 35.1% 向上します。 完全量子化トレーニング (FQT) メソッドのアクティベーション、重み、および勾配はトレーニングを高速化するために低精度に量子化されるため、トレーニング中の線形演算子および非線形演算子は低精度の算術演算で実装できます。 FQT 研究は、完全精度のテンソルをより適切に近似できる新しい数値形式と量子化アルゴリズムを設計しました。 現在の研究の最前線は 4 ビット FQT です。 FQT は、勾配の数値範囲が広いことと、量子化されたネットワークを最初からトレーニングするという最適化問題があるため、困難です。 これらの課題により、既存の 4 ビット FQT アルゴリズムは依然として一部のタスクで 1 ~ 2.5% の精度損失が発生しており、最新のハードウェアをサポートできません。 混合専門家が増えない 改善トレーニング予算内でのモデルの能力。 構造ドロップアウトでは、計算効率の高い方法を利用してモデルを正規化します。注意を効率的に行うと、注意を計算する際の二次時間の複雑さが軽減されます。 #分散型トレーニング システムは、より多くのコンピューティング リソースを利用することでトレーニング時間を短縮します。 研究者の数値精度を下げる作業は、これらの方向とは直交しています。 順伝播 ニューラル ネットワークトレーニングは、順方向および逆方向の伝播を通じて確率的勾配を計算する反復的な最適化プロセスです。 研究チームは、4 ビット整数 (INT4) アルゴリズムを使用して、順方向伝播と逆方向伝播を高速化します。 順伝播は、線形演算子と非線形演算子 (GeLU、正規化、ソフトマックスなど) の組み合わせで実装できます。 トレーニング プロセス中、すべての線形演算子を INT4 算術で高速化し、計算コストの低いすべての非線形演算子を 16 ビット浮動小数点 (FP16) 形式に保ちます。 Transformer のすべての線形演算は、行列乗算 (MM) の形式で記述できます。 表現を容易にするために、この記事では、単純な行列乗算の次の高速化について考察します。 この種の MM の主な使用例は、完全接続層です。 入力形状が (バッチ サイズ S、シーケンス長 T、次元 D) である Transformer を考えてみましょう。 全結合層は上記の式で表すことができます。ここで、X は N = STtoken の活性化、W は重み行列です。 注目層の場合、バッチ行列乗算 (BMMS) が必要になる場合があります。 私たちが提案する技術はBMMSにも応用可能です。 トレーニングを高速化するには、整数演算を使用して順伝播を計算する必要があります。 研究者らは、この目的のために学習ステップ量子化器 (LSQ) を利用しました。 LSQ は静的量子化です。その量子化スケールは入力メソッドに依存しないため、動的メソッドよりも安価です。量子化メソッドは、量子化スケールを動的に計算する必要があります。各反復。 異常値のアクティブ化 4 ビット/FQT の重みを使用して LSQ をアクティブ化に適用するだけです外れ値がアクティブになるため、精度が低下する可能性があります。 上の図に示すように、アクティベーションには他のエントリよりも大きい外れ値エントリがいくつかあります。 残念ながら、トランスフォーマーはこれらの外れ値に情報を保存する傾向があり、そのような切り捨てにより精度が著しく損なわれる可能性があります。 異常値の問題は、トレーニング タスクがいくつかの新しい下流タスクで事前トレーニングされたモデルを微調整する場合に特に顕著です。 事前トレーニングされたモデルには、ランダムな初期化よりも多くの外れ値が含まれているためです。 外れ値の問題を解決するために、アダマール量子化 (HQ) を提案します。 主なアイデアは、外れ値の少ない線形空間で別の行列を量子化することです。 アクティベーション マトリックスの外れ値は、機能ごとの構造を形成します。 それらは通常、いくつかの次元に集中しています。つまり、X のいくつかの列だけが他の列よりも大幅に大きくなります。 ハーダマンド変換は、外れ値を他のエントリに広げる線形変換です。 逆伝播 次に、INT4 演算を使用して線形層の逆伝播を高速化することを検討します。 このセクションでは、活性化勾配/重み勾配の計算について説明します。 勾配行列はトレーニング中に非常に疎であることが多いことに気付きました。 そして、スパース性は次のような構造になっています。 この構造的希薄性は、最新のニューラル ネットワークの過度のパラメータ化によって生じます。 ネットワークは、トレーニング プロセスのほぼ全体にわたってハイパーパラメータ化スキームで実行され、いくつかの困難な例を除いて、ほとんどのトレーニング データにうまく適応します。 したがって、よく適合したデータ ポイントの場合、(活性化) 勾配はゼロに近くなります。 研究者らは、たとえば、トレーニング前のタスクでは、数回のトレーニング エポックの後に構造的希薄性がすぐに現れることを発見しました。 微調整タスクの場合、トレーニング プロセス全体を通じて勾配は常にまばらになります。 バックプロパゲーション中に構造的スパース性を正確に活用する勾配量子化器を設計する方法 MM の計算についてはどうでしょうか? 高度なアイデアは、勾配の行の多くが非常に小さいため、パラメーターの勾配にほとんど影響を与えませんが、多くの計算を無駄にします。 一方、大きな行は INT4 では正確に表現できません。 いくつかの小さな行を削除し、節約された計算能力を使用して大きな行をより正確に表現します。 実験 研究者は、言語モデル、機械翻訳、画像分類などのさまざまなタスクで微調整された INT4 トレーニング アルゴリズムを評価します。 研究者らは、CUDA と Cutlass を使用して、提案された HQ-MM および LSS-MM アルゴリズムを実行しました。 研究者らはすべての浮動小数点線形演算子を INT4 実装に置き換えましたが、単に LSQ を使用して層を埋め込むのではなく、最後の分類器層の精度を維持しました。 最終的に、研究者らは、評価されたすべてのモデルにデフォルトのアーキテクチャ、オプティマイザー、スケジューラー、ハイパーパラメーターを採用しました。 研究者らは、以下の表でさまざまなタスクにおける収束モデルの精度を比較しました。 比較方法には、フルプレシジョン トレーニング (FP)、INT8 トレーニング (INT8)、FP4 トレーニング (" Ultra -low")、アクティベーションと重み付けに LSQ を使用する 4 ビット ログ量子化 (LSQ LUQ)、および順伝播に HQ を使用し、逆伝播に LSS を使用するアルゴリズム (HQ LSS)。 「Ultra Low」には公開実装がないため、機械翻訳タスクの元の論文でそのパフォーマンスのみをリストします。 大規模な機械翻訳タスクと大規模なビジュアル Transformer タスクを除き、各実行を 3 回繰り返し、標準偏差を表の下付き文字として報告します。 研究者らは、いかなる種類の知識の抽出やデータの拡張も実行しませんでした。 研究者らによって行われたアブレーション実験は、フォワード法とバックワード法の有効性を実証するために設計されました。 さまざまな量子化器に対する順伝播の有効性を調べるために、FP16 では逆伝播をそのままにしておきます。 #結果を以下に示します。 ついに研究者たちは、評価 彼らのプロトタイプ実装は、ニューラル ネットワーク トレーニングを加速するアプローチの可能性を示しています。 そして、その実装はまだ完全には最適化されていません。 研究者らは、線形演算子を非線形性や正規化と統合しませんでした。 したがって、結果は INT4 トレーニング アルゴリズムの可能性を完全には反映していません。 完全に最適化された実装には大規模なエンジニアリングが必要ですが、この文書の範囲を超えています。 #結論 研究者らは、Transformer の MM の特性を分析することにより、精度を維持しながら活性化と勾配を定量化するための HQ および LSS 手法を提案しました。 いくつかの重要なタスクにおいて、私たちのメソッドは既存の INT4 メソッドと同等かそれ以上のパフォーマンスを発揮します。 研究者の研究は、MLP ミキサー、グラフ ニューラル ネットワーク、リカレント ニューラル ネットワーク ネットワークなど、トランスフォーマー以外の他の MM アーキテクチャにも拡張される可能性があります。 これが彼らの今後の研究の方向性です。
より広範な影響: 研究者のアルゴリズムは効率を高め、トレーニング ニューラル ネットワークのエネルギー消費を削減でき、二酸化炭素排出量の削減に役立つ可能性があります。深層学習によって引き起こされます。 ただし、効率的なトレーニング アルゴリズムは、人間の安全保障のリスクを引き起こす大規模な言語モデルや悪意のある人工知能アプリケーションの開発を促進する可能性もあります。 たとえば、誤ったコンテンツの生成に使用される関連モデルやアプリケーション。 制限事項: この作業の主な制限は、より大きなモデルを使用した大規模な行列乗算 (線形層) のみを高速化できることです。 、ただし畳み込み層を高速化することはできません。 さらに、提案された方法は、OPT-175B のような非常に大きなモデルにはあまり適用できません。 私たちの知る限り、これらの非常に大規模なモデルでは、INT8 トレーニングでさえまだ未解決の問題です。 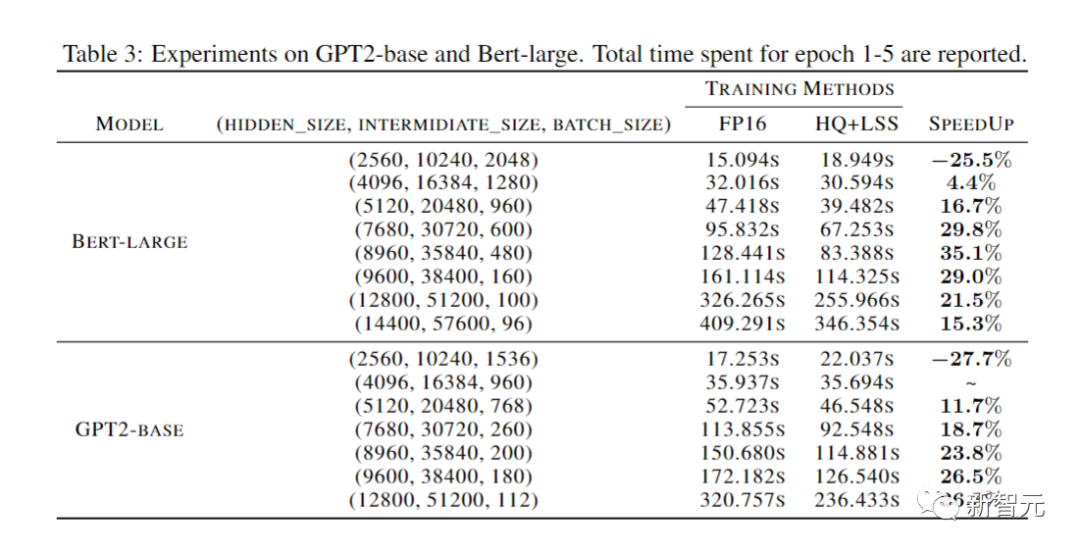 画像
画像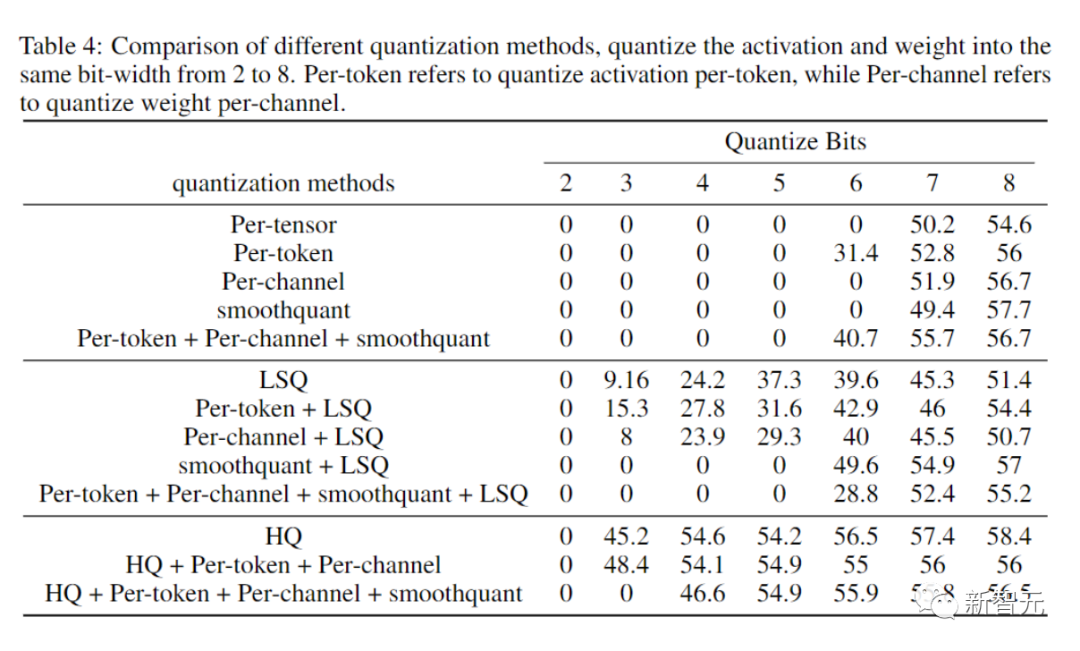 写真
写真関連作品
完全量子化トレーニング
 写真
写真その他の効果的なトレーニング方法
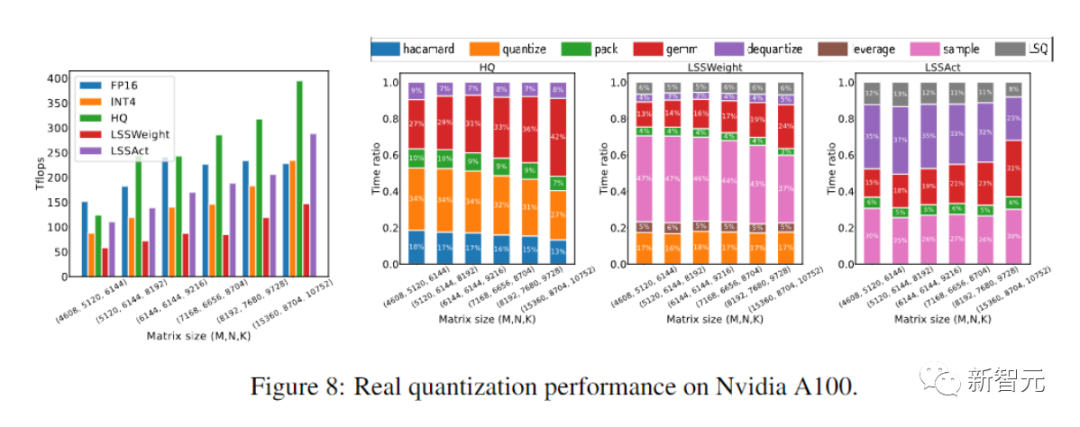 写真
写真学習済みステップ量子化
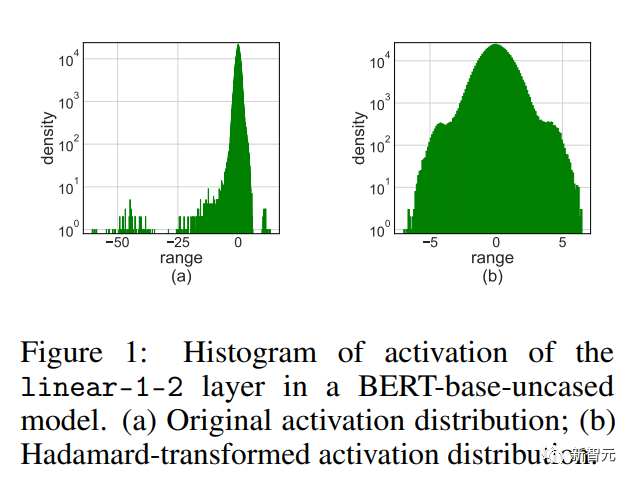 図
図アダマール量子化
勾配の構造的疎性
 # には、より大きなエントリを含むいくつかの行 (トークンなど) があり、大きいほど、他のほとんどの行はすべてゼロのベクトルに近くなります。
# には、より大きなエントリを含むいくつかの行 (トークンなど) があり、大きいほど、他のほとんどの行はすべてゼロのベクトルに近くなります。 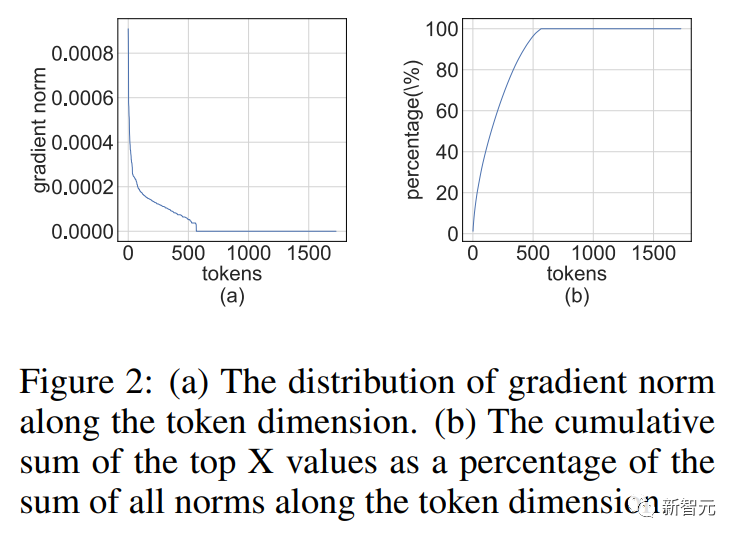 写真
写真ビット分割とスコア サンプリングの活用
収束モデルの精度
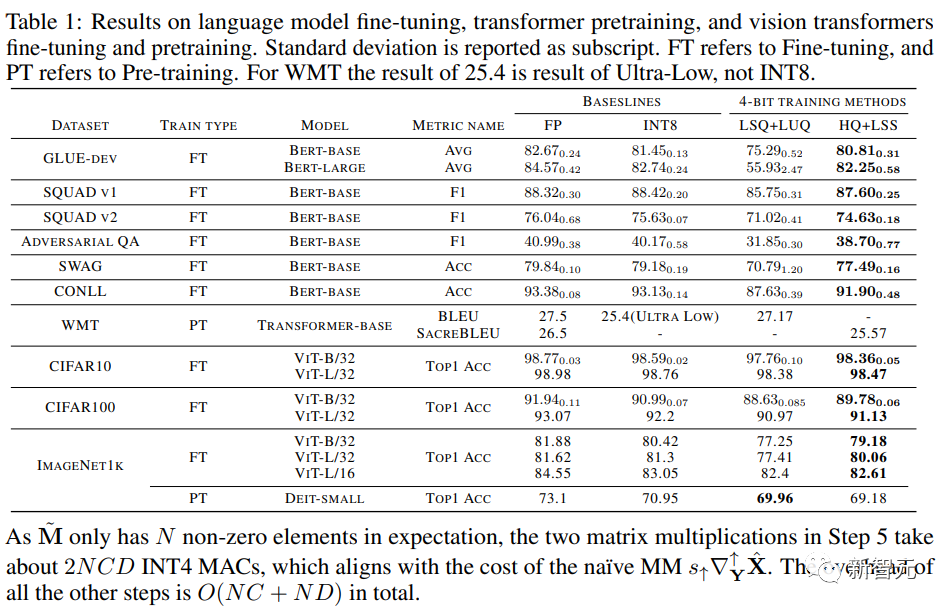 写真
写真アブレーション実験
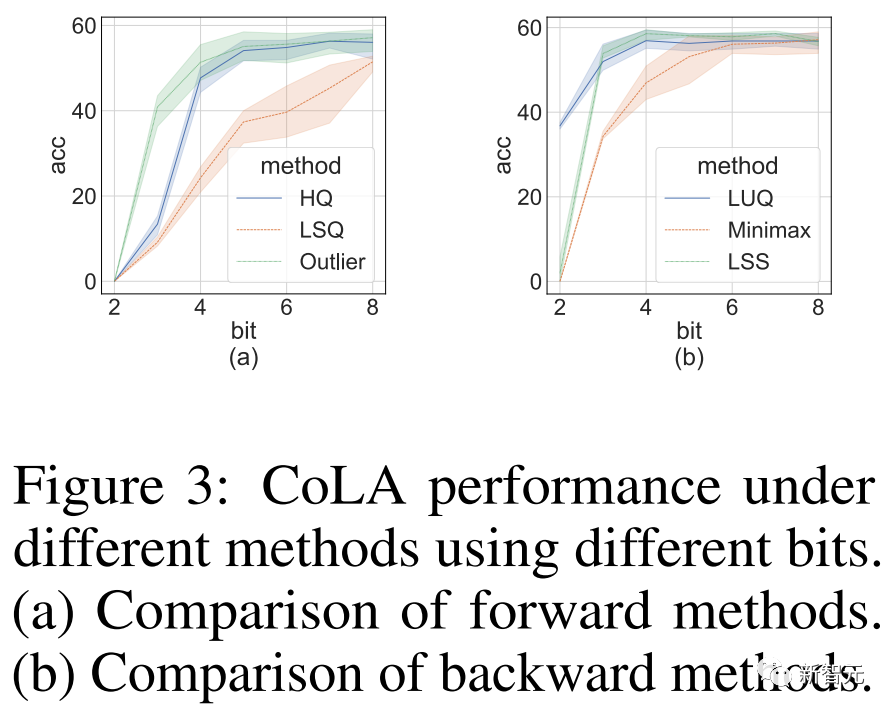 写真
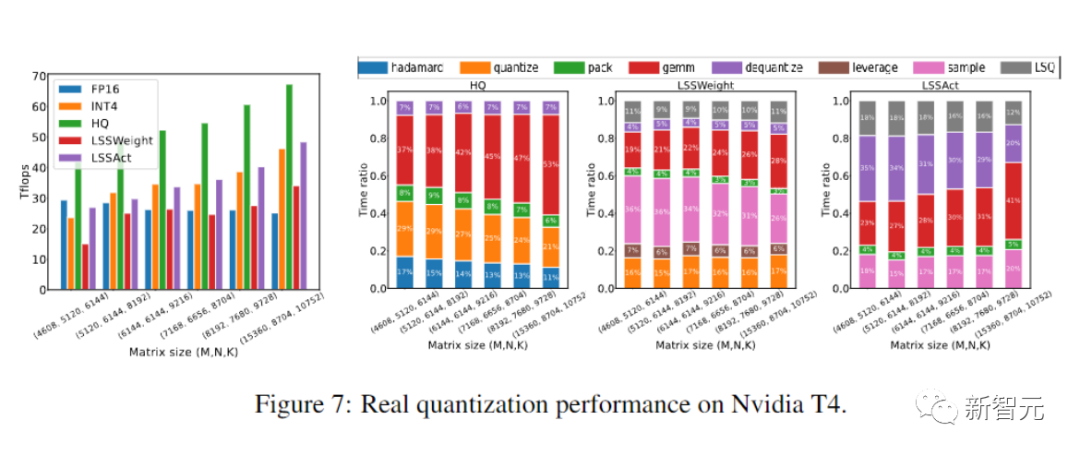
写真計算効率とメモリ効率
研究者らは、ハードウェアに非常に優しい Transformer INT4 のトレーニング方法を提案しました。
以上が清華大学の Zhu Jun チームの新しい成果: 4 桁の整数を使用して Transformer をトレーニングします。これは FP16 よりも 2.2 倍、35.1% 高速であり、AGI の到来を加速します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



