


誰もが独自の大規模モデルのアップグレードと反復を続けるにつれて、コンテキスト ウィンドウを処理する LLM (大規模言語モデル) の能力も重要な評価指標になりました。
たとえば、OpenAI の gpt-3.5-turbo は 16,000 トークンのコンテキスト ウィンドウ オプションを提供し、AnthropicAI は Claude のトークン処理能力を 100,000 に増加しました。大規模なモデル処理コンテキスト ウィンドウの概念は何ですか? たとえば、GPT-4 は 32,000 のトークンをサポートします。これは 50 ページのテキストに相当します。つまり、GPT-4 は会話または生成するときに最大約 50 ページのコンテンツを記憶できます。文章。
一般的に、大規模な言語モデルがコンテキスト ウィンドウのサイズを処理できるかどうかは、あらかじめ決まっています。たとえば、Meta AI によってリリースされた LLaMA モデルの場合、その入力トークン サイズは 2048 未満である必要があります。
ただし、長い会話を行ったり、長い文書を要約したり、長期計画を実行したりするようなアプリケーションでは、事前に設定されたコンテキスト ウィンドウの制限を超えることがよくあるため、これ以上長い時間を処理することは困難です。コンテキスト ウィンドウ。LLM の方が一般的です。
しかし、これには新たな問題があり、長いコンテキスト ウィンドウを使用して LLM を最初からトレーニングするには多大な投資が必要です。これは当然、既存の事前トレーニング済み LLM のコンテキスト ウィンドウを拡張できるか?という疑問につながります。
単純なアプローチは、既存の事前トレーニング済み Transformer を微調整して、より長いコンテキスト ウィンドウを取得することです。ただし、経験的な結果は、この方法でトレーニングされたモデルが長いコンテキスト ウィンドウに適応するのが非常に遅いことを示しています。 10000 回のトレーニング バッチの後でも、有効コンテキスト ウィンドウの増加は依然として非常に小さく、2048 年から 2560 年までの期間のみです (実験セクションの表 4 に見られるように)。これは、このアプローチがより長いコンテキスト ウィンドウへのスケーリングにおいて非効率であることを示唆しています。
この記事では、Meta の研究者が 位置補間 (PI) を既存の事前トレーニング済み LLM (LLaMA を含む) に導入しました。コンテキスト ウィンドウが展開されます。結果は、LLaMA コンテキスト ウィンドウを 2k から 32k にスケーリングするのに必要な微調整ステップは 1000 ステップ未満であることを示しています。
 写真
写真
論文アドレス: https://arxiv.org/pdf/2306.15595.pdf
この研究の重要なアイデアは、外挿を実行することではなく、最大位置インデックスが事前トレーニング段階のコンテキスト ウィンドウの制限と一致するように位置インデックスを直接減らすことです。言い換えれば、より多くの入力トークンに対応するために、この研究では、トレーニングされた位置を超えて外挿するのではなく、位置エンコーディングが非整数位置に適用できるという事実を利用して、隣接する整数位置で位置エンコーディングを内挿します。後者は壊滅的な価値をもたらす可能性があります。
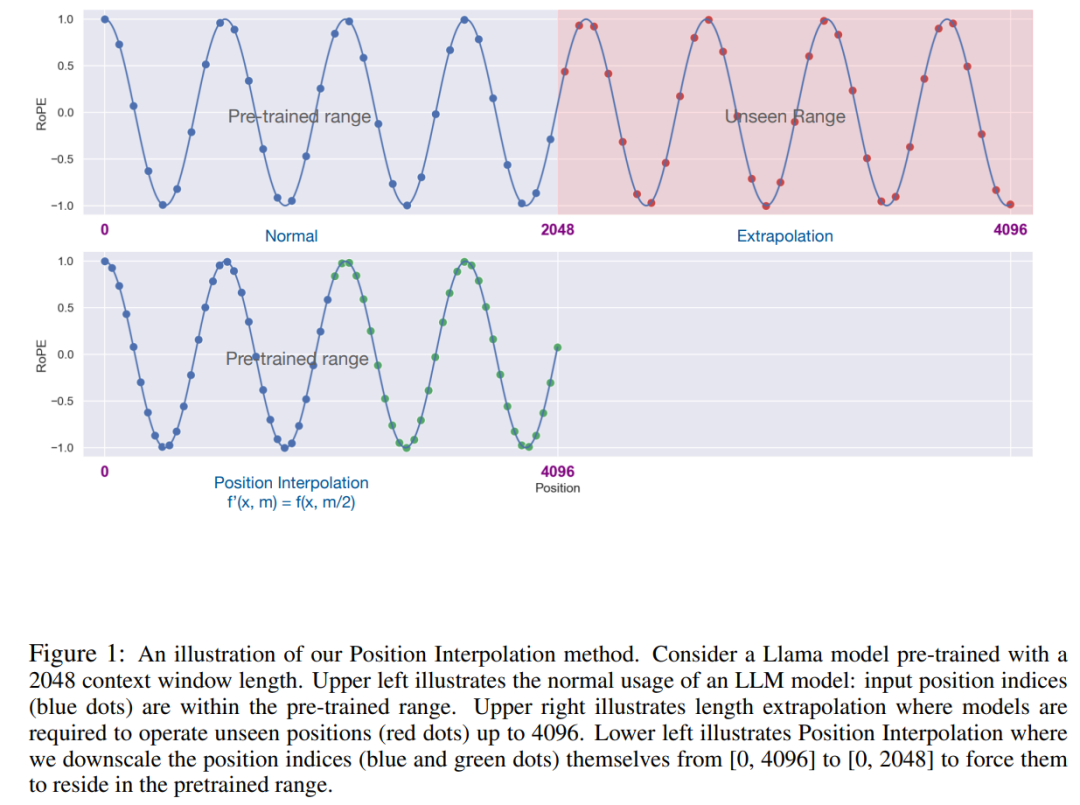
PI メソッドは、RoPE (回転位置) に基づいて、事前トレーニングされた LLM (LLaMA など) のコンテキスト ウィンドウ サイズを拡張します。この研究では、最小限の微調整 (1000 ステップ以内) で最大 32768 まで、検索、言語モデリング、LLaMA 7B から 65B までの長い文書の要約など、長いコンテキストを必要とするさまざまなタスクでパフォーマンスの向上が達成されています。同時に、PI によって拡張されたモデルは、元のコンテキスト ウィンドウ内で比較的良好な品質を維持します。
RoPE は、私たちがよく知っている LLaMA、ChatGLM-6B、PaLM などの大規模な言語モデルに存在します。 Zhuiyi Technology の Su Jianlin 氏らによって提案された RoPE は、絶対エンコーディングによる相対位置エンコーディングを実装します。
RoPE の注意スコアは相対位置にのみ依存しますが、外挿パフォーマンスは良好ではありません。特に、より大きなコンテキスト ウィンドウに直接スケーリングする場合、混乱が非常に高い数値 (つまり、> 10^3) に達する可能性があります。
この記事では位置補間法を使用していますが、外挿法との比較は次のとおりです。基底関数 ϕ_j が滑らかであるため、内挿はより安定しており、外れ値が発生しません。
#写真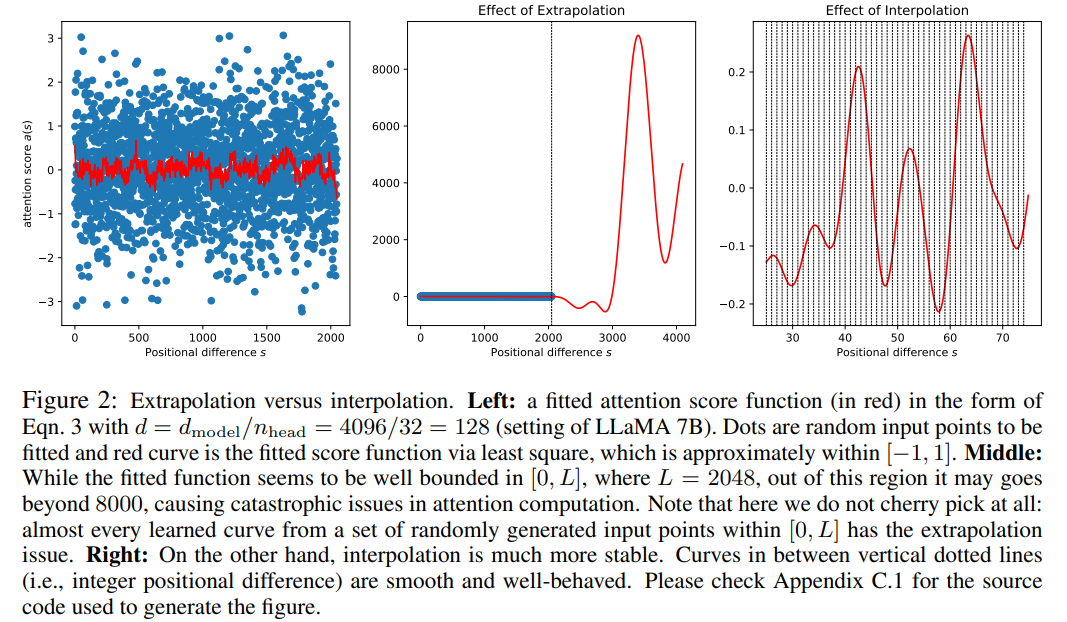
# ##### ######写真######
この研究では、位置エンコーディングの変換を位置補間と呼びます。このステップでは、RoPE を計算する前に、位置インデックスを [0, L' ) から [0, L) に減らして、元のインデックス範囲と一致させます。したがって、RoPE への入力として、任意の 2 つのトークン間の最大相対距離は L ' から L に減少しました。拡張前後で位置インデックスと相対距離の範囲を調整することで、コンテキスト ウィンドウの拡張による注意スコアの計算への影響が軽減され、モデルの適応が容易になります。
位置インデックスの再スケーリング方法では、追加の重みが導入されず、モデル アーキテクチャがまったく変更されないことは注目に値します。
この研究は、位置補間によってコンテキスト ウィンドウを元のサイズの 32 倍に効果的に拡張できること、およびこの拡張だけが効果的であることを実証します。完了するには何百ものトレーニング ステップが必要です。
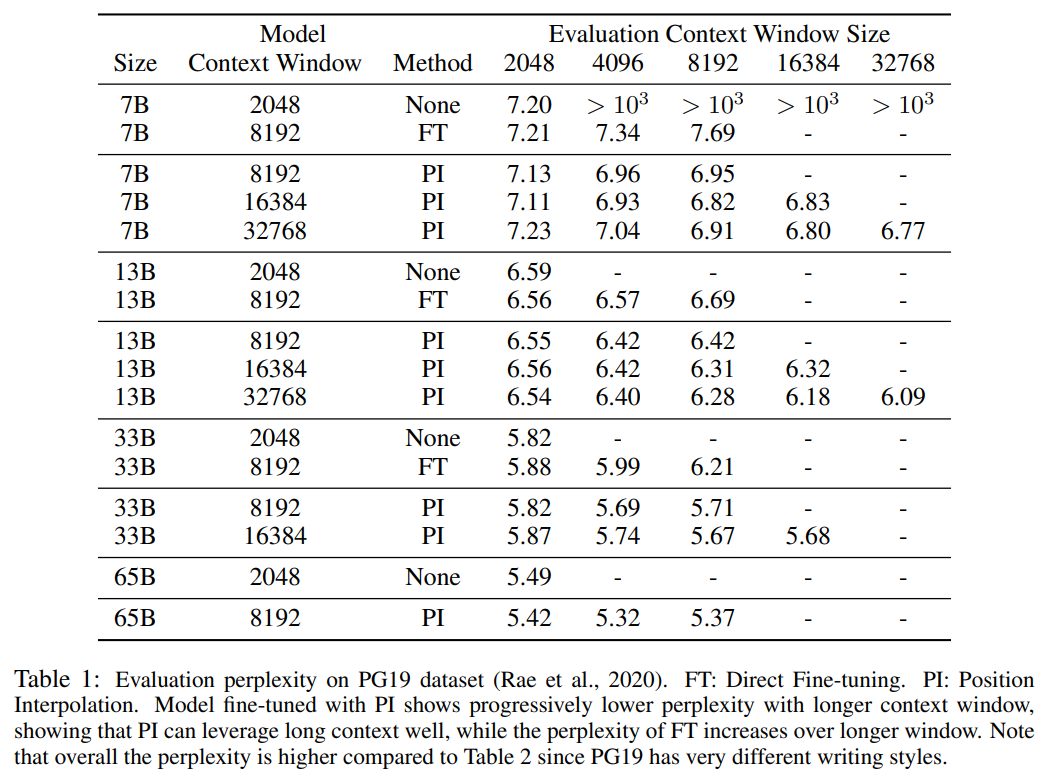
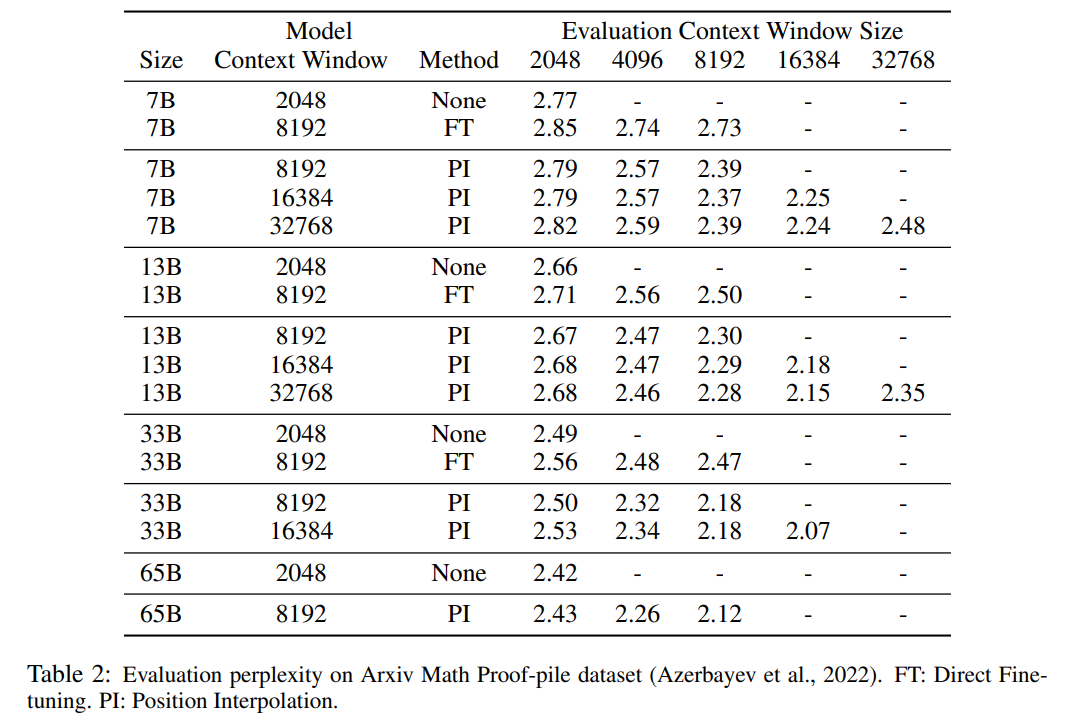
表 1 と表 2 は、PG-19 および Arxiv Math Proof-pile データ セットにおける PI モデルとベースライン モデルの複雑さを報告します。結果は、PI 法を使用して拡張されたモデルが、より長いコンテキスト ウィンドウ サイズでの混乱を大幅に改善することを示しています。
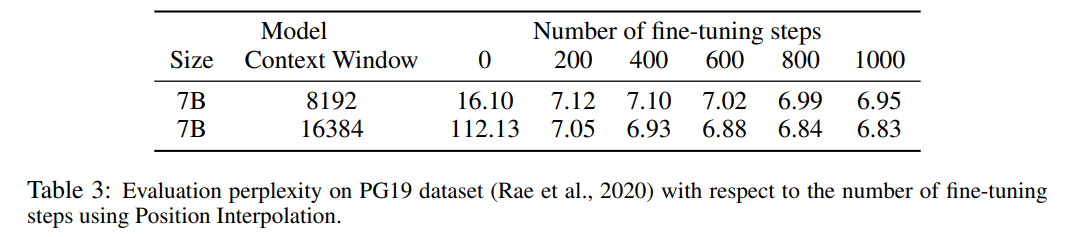
#表 3 は、PG19 データセットの PI メソッドを使用した LLaMA 7B モデルの 8192 への拡張を報告します。 16384 は、コンテキスト ウィンドウ サイズが大きい場合のパープレキシティと微調整ステップ数の関係です。
結果から、微調整なし (ステップ数は 0) で、コンテキスト ウィンドウが展開されたときなど、モデルが特定の言語モデリング機能を示すことができることがわかります。 to 8192 パープレキシティは 20 未満です (直接外挿法の場合は 10^3 を超えます)。 200 ステップでは、モデルの複雑度はコンテキスト ウィンドウ サイズ 2048 の元のモデルの複雑度を超えており、このモデルが事前トレーニングされた設定よりも長いシーケンスを言語モデリングに効果的に利用できることを示しています。 1000 ステップでは、モデルが着実に改善され、より優れた複雑性が達成されることがわかります。
 図
図
次の表は、PI によって拡張されたモデルが、有効なコンテキスト ウィンドウ サイズの点でスケーリング目標を正常に達成していることを示しています。つまり、わずか 200 ステップの微調整の後、有効コンテキスト ウィンドウ サイズは最大値に達し、7B および 33B のモデル サイズおよび最大 32768 コンテキスト ウィンドウで一貫性が保たれます。対照的に、直接微調整によってのみ拡張された LLaMA モデルの有効コンテキスト ウィンドウ サイズは 2048 から 2560 に増加するだけであり、10000 ステップを超える微調整の後でもウィンドウ サイズが大幅に加速される兆候はありませんでした。
#図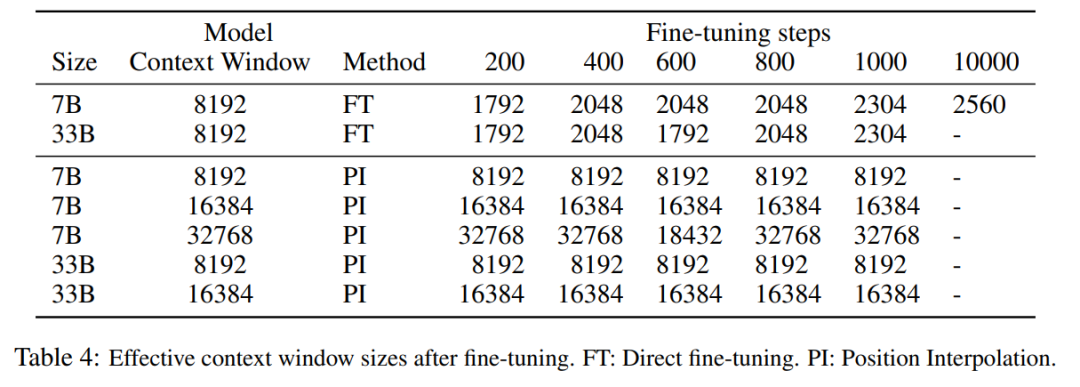
図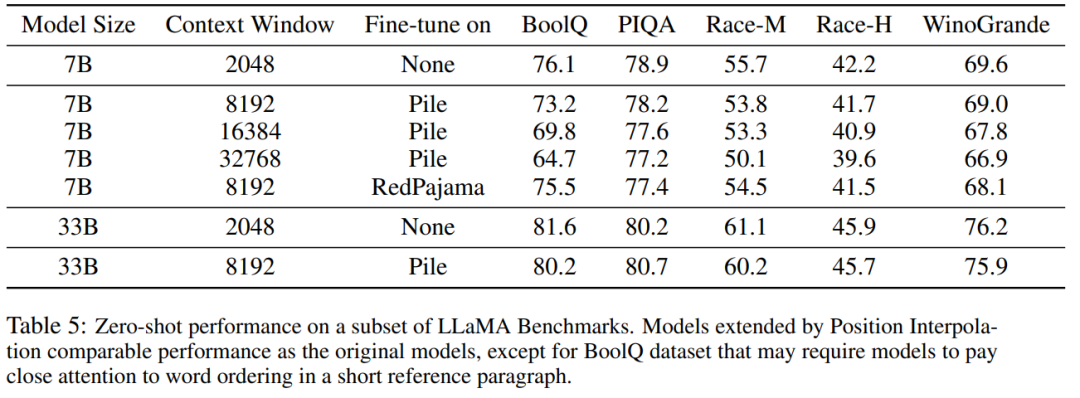
以上がTian Yuandong チームによる新しい研究: 1000 ステップ未満の微調整、LLaMA コンテキストを 32K まで拡張の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



