


生成 AI は人工知能コミュニティに旋風を巻き起こし、個人も企業も、Vincent 写真、Vincent ビデオ、Vincent 音楽など、関連するモーダル変換アプリケーションの作成に熱心になり始めています。
最近、ServiceNow Research や LIVIA などの科学研究機関の数名の研究者が、テキストの説明に基づいて論文内のグラフを生成しようとしました。この目的のために、彼らは FigGen の新しい手法を提案し、関連する論文も ICLR 2023 の Tiny Paper として掲載されました。
 写真
写真
論文アドレス: https://arxiv.org/pdf/2306.00800.pdf
論文内のグラフを生成するのがそんなに難しいのかと疑問に思う人もいるかもしれません。これは科学研究にどのように役立ちますか?
科学研究チャートの生成は、研究結果を簡潔かつわかりやすい方法で広めるのに役立ちます。チャートの自動生成は、時間とエネルギーを節約するなど、研究者に多くのメリットをもたらします。グラフをゼロからデザインすることに労力を費やしてください。また、視覚的にわかりやすく図をデザインすることで、より多くの人に論文を読んでもらうことができます。
ただし、図の生成には、ボックス、矢印、テキストなどの個別のコンポーネント間の複雑な関係を表現する必要があるという課題もあります。自然画像の生成とは異なり、紙のグラフでは概念が異なる表現を持ち、詳細な理解が必要となる場合があります。たとえば、ニューラル ネットワーク グラフの生成には、分散が大きい不正設定問題が含まれます。
したがって、この論文の研究者は、紙の図のペアのデータセットで生成モデルをトレーニングし、図のコンポーネントと論文内の対応するテキストの間の関係を把握しました。これには、さまざまな長さ、高度に専門的なテキストの説明、さまざまなグラフ スタイル、画像のアスペクト比、テキスト レンダリングのフォント、サイズ、向きの問題に対処する必要があります。
具体的な実装プロセスでは、研究者たちは最近のテキストから画像への結果からインスピレーションを得て、拡散モデルを使用してチャートを生成し、科学研究チャートを生成するための普及の可能性を提案しました。テキストの説明。モデル - FigGen。
この普及モデルのユニークな特徴は何ですか?詳細に進みましょう。
研究者たちは、潜在拡散モデルをゼロからトレーニングしました。
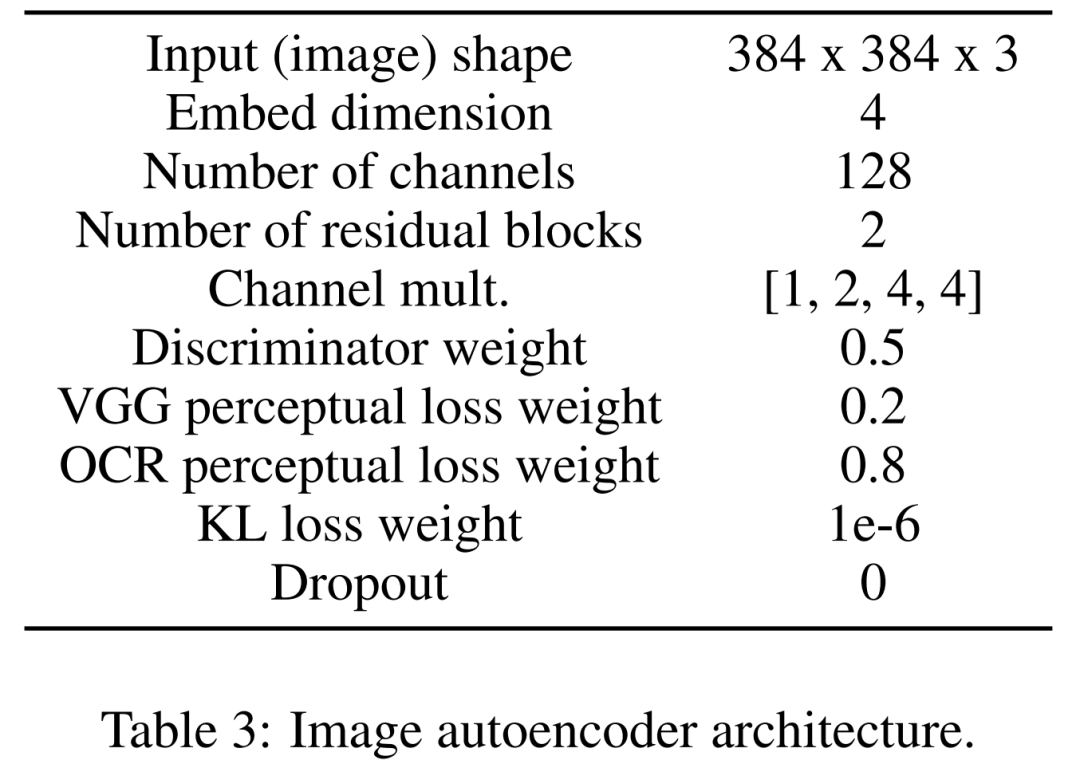
まず、画像を圧縮された潜在表現にマッピングするための画像オートエンコーダーを学習します。画像エンコーダは、KL 損失と OCR 知覚損失を使用します。条件付けに使用されるテキスト エンコーダーは、この拡散モデルのトレーニングでエンドツーエンドで学習されます。以下の表 3 は、画像オートエンコーダ アーキテクチャの詳細なパラメータを示しています。
拡散モデルは潜在空間で直接対話し、データ破損したフォワード スケジューリングを実行しながら、時間的およびテキストの条件付きノイズ除去 U-Net を利用してプロセスから回復する方法を学習します。
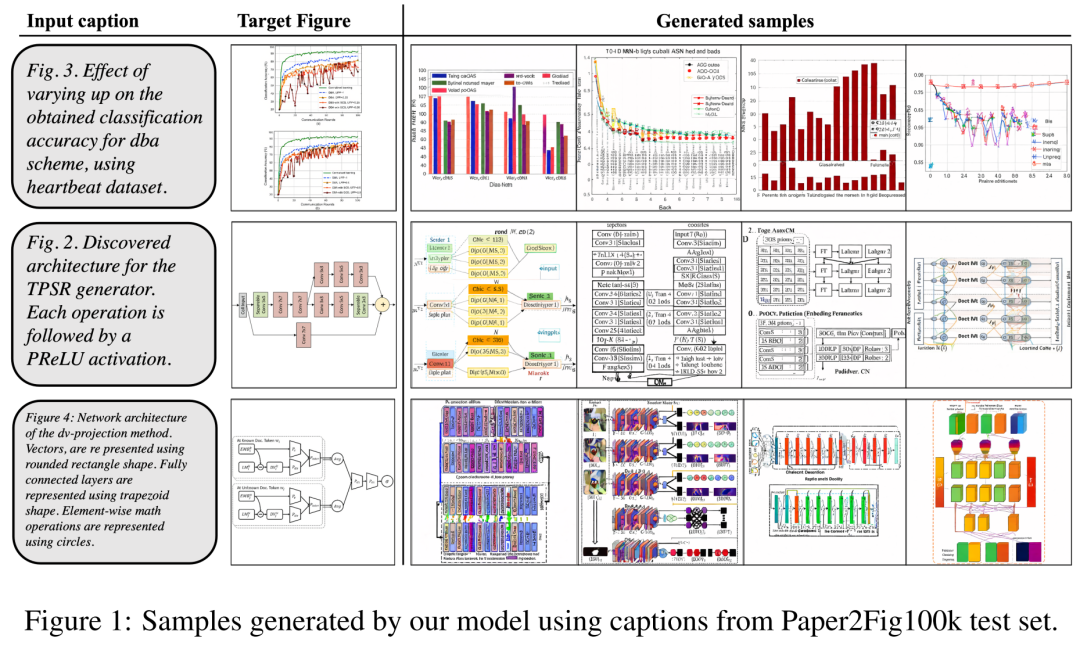
## データセットとして、研究者らは Paper2Fig100k を使用しました。これは論文内のグラフとテキストのペアで構成され、81,194 個のデータが含まれています。トレーニング サンプルと 21,259 の検証サンプル。以下の図 1 は、Paper2Fig100k テスト セットのテキスト説明を使用して生成された図の例です。
#モデル詳細
まずは画像エンコーダー。最初の段階では、画像オートエンコーダーがピクセル空間から圧縮された潜在表現へのマッピングを学習し、拡散モデルのトレーニングを高速化します。また、画像エンコーダーは、図の重要な詳細 (テキストのレンダリング品質など) を失うことなく、潜像をピクセル空間にマップし直す方法を学習する必要があります。この目的を達成するために、研究者らは、因子 f=8 で画像をダウンサンプリングするボトルネックを備えた畳み込みコーデックを定義しました。エンコーダーは、ガウス分布を使用して KL 損失、VGG 認識損失、OCR 認識損失を最小限に抑えるようにトレーニングされています。
2 番目はテキスト エンコーダーです。研究者らは、汎用テキスト エンコーダがグラフ生成タスクには適していないことを発見しました。したがって、彼らは、サイズ 512 の埋め込みチャネルを使用する拡散プロセスで最初からトレーニングされた Bert トランスフォーマーを定義しました。これは、U-Net のクロスアテンション層を調整する埋め込みサイズでもあります。研究者らは、さまざまな設定(8、32、128)下での変圧器層の数の変化も調査しました。
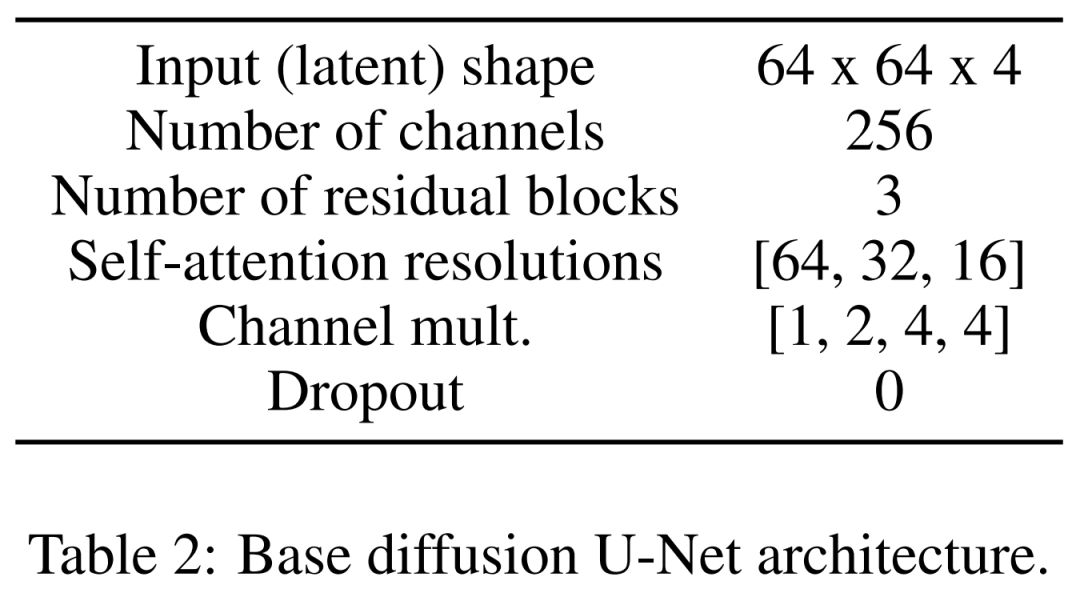
最後に、潜在拡散モデルがあります。以下の表 2 は、U-Net のネットワーク アーキテクチャを示しています。画像の知覚的に等価な潜在表現に対して拡散プロセスを実行します。この場合、画像の入力サイズは 64x64x4 に圧縮され、拡散モデルが高速になります。彼らは 1,000 の拡散ステップと線形ノイズ スケジューリングを定義しました。
トレーニングの詳細
##画像オートエンコーダーをトレーニングするために、研究者らは、4 サンプルの有効バッチ サイズと 4.5e−6 の学習率を持つ Adam オプティマイザーを使用しました。その間、4 枚の 12GB NVIDIA V100 グラフィックス カードが使用されました。トレーニングの安定性を達成するために、弁別器を使用せずに 50k 反復でモデルをウォームアップします。潜在拡散モデルをトレーニングするために、研究者らは、有効バッチ サイズ 32、学習率 1e−4 の Adam オプティマイザーも使用しました。 Paper2Fig100k データセットでモデルをトレーニングするとき、8 枚の 80GB NVIDIA A100 グラフィックス カードを使用しました。
実験結果
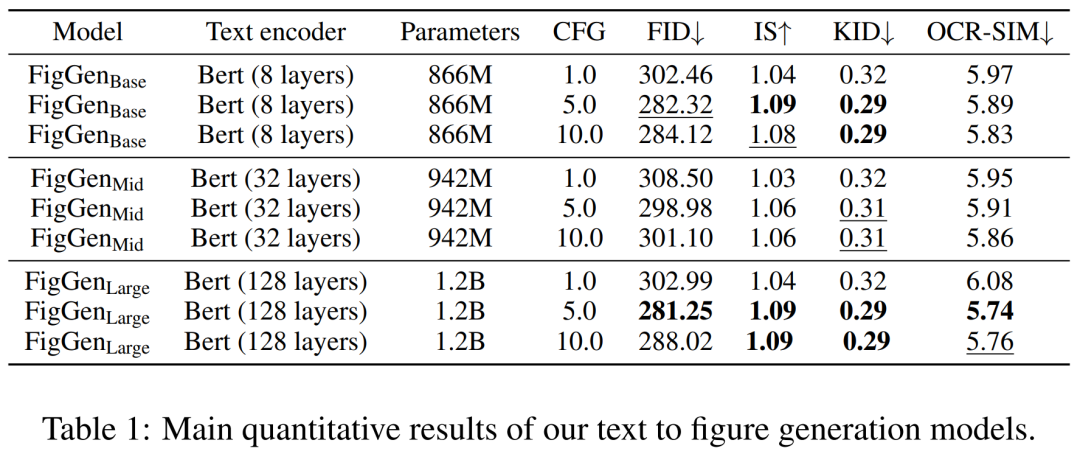
以下の表 1 は、さまざまなテキスト エンコーダーの結果を示しています。大きなテキスト エンコーダが最良の定性的結果を生成し、CFG のサイズを増やすことで条件生成を改善できることがわかります。定性サンプルは問題を解決するには十分な品質ではありませんが、FigGen はテキストと画像の関係を把握しました。
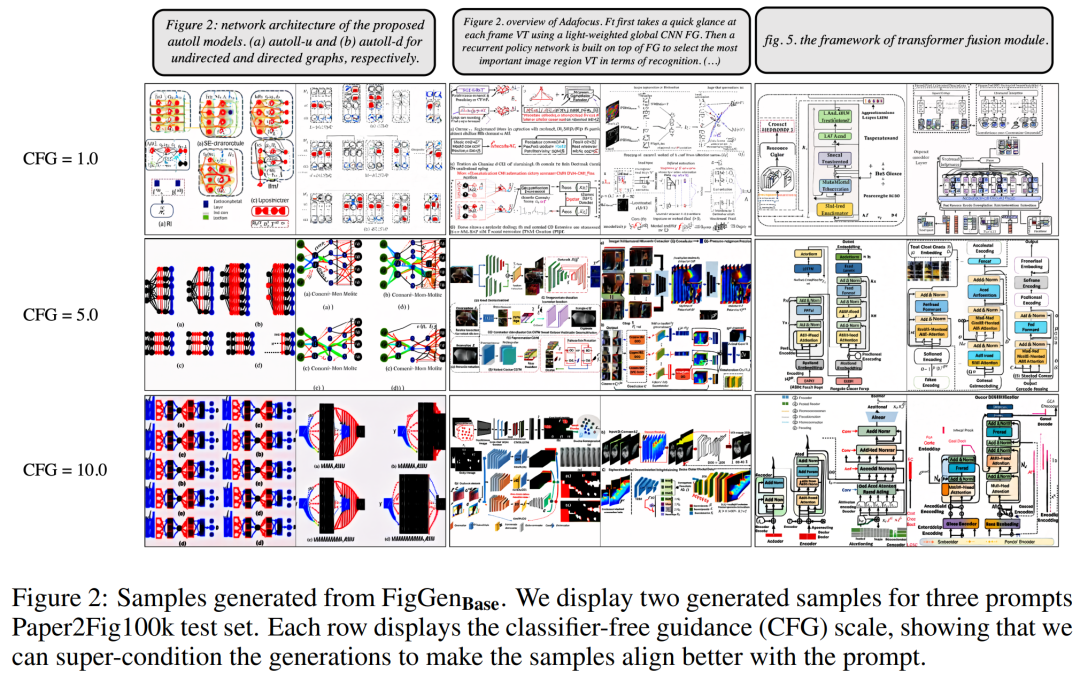
 # 以下の図 2 は、Classifier-Free Guide (CFG) パラメーターを調整するときに生成される追加の FigGen サンプルを示しています。研究者らは、CFG のサイズを大きくすると画質が向上することを観察しました。これは定量的にも実証されました。
# 以下の図 2 は、Classifier-Free Guide (CFG) パラメーターを調整するときに生成される追加の FigGen サンプルを示しています。研究者らは、CFG のサイズを大きくすると画質が向上することを観察しました。これは定量的にも実証されました。
写真
 下の図 3 は、FigGen からのその他の生成例を示しています。理解可能な画像を正しく生成するモデルの難易度に密接に影響するテキスト記述の技術レベルだけでなく、サンプル間の長さの違いにも注意してください。
下の図 3 は、FigGen からのその他の生成例を示しています。理解可能な画像を正しく生成するモデルの難易度に密接に影響するテキスト記述の技術レベルだけでなく、サンプル間の長さの違いにも注意してください。
写真
 ただし、研究者らは、これらの生成されたグラフは論文の著者にとって実際的な助けにはならないが、彼らはまだそれを有望な探求の方向とみなすことができます。
ただし、研究者らは、これらの生成されたグラフは論文の著者にとって実際的な助けにはならないが、彼らはまだそれを有望な探求の方向とみなすことができます。
研究の詳細については、元の論文を参照してください。
以上が紙のイラストも拡散モデルを使用して自動生成でき、ICLR にも受け入れられます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



