


今日のソーシャル メディアやインターネット文化においてビデオの役割はますます重要になっており、Douyin、Kuaishou、Bilibili などは数億人のユーザーに人気のプラットフォームとなっています。ユーザーは、自分の人生の瞬間、創造的な作品、興味深い瞬間、その他のビデオを中心としたコンテンツを共有して、他のユーザーと対話し、コミュニケーションを図ります。
最近、大規模な言語モデルが優れた機能を実証しています。大型モデルに「目」と「耳」を持たせて、動画を理解してユーザーと対話できるようにすることはできないだろうか。
この問題から出発して、DAMO アカデミーの研究者は、包括的なオーディオビジュアル機能を備えた大規模モデルである Video-LLaMA を提案しました。 Video-LLaMA は、ビデオ内のビデオおよびオーディオ信号を認識して理解することができ、オーディオ/ビデオの説明、書き込み、質疑応答など、オーディオとビデオに基づく一連の複雑なタスクを完了するためのユーザー入力指示を理解できます。現在、論文、コード、インタラクティブなデモはすべて公開されています。さらに、研究チームは、Video-LLaMA プロジェクトのホームページで、中国のユーザーのエクスペリエンスをよりスムーズにするために、モデルの中国語版も提供しています。

ビデオの動的なシーンの変化をキャプチャするために、Video-LLaMA にはプラグイン可能なビジュアル言語ブランチが導入されています。このブランチでは、まず BLIP-2 の事前トレーニング済み画像エンコーダーを使用して画像の各フレームの個々の特徴を取得し、それを対応するフレーム位置の埋め込みと組み合わせます。すべての画像特徴は Video Q-Former と Video Q に送信されます。 -前者はフレームレベルの画像表現を集約し、固定長の合成ビデオ表現を生成します。最後に、線形レイヤーを使用して、ビデオ表現を大規模言語モデルの埋め込み空間に位置合わせします。
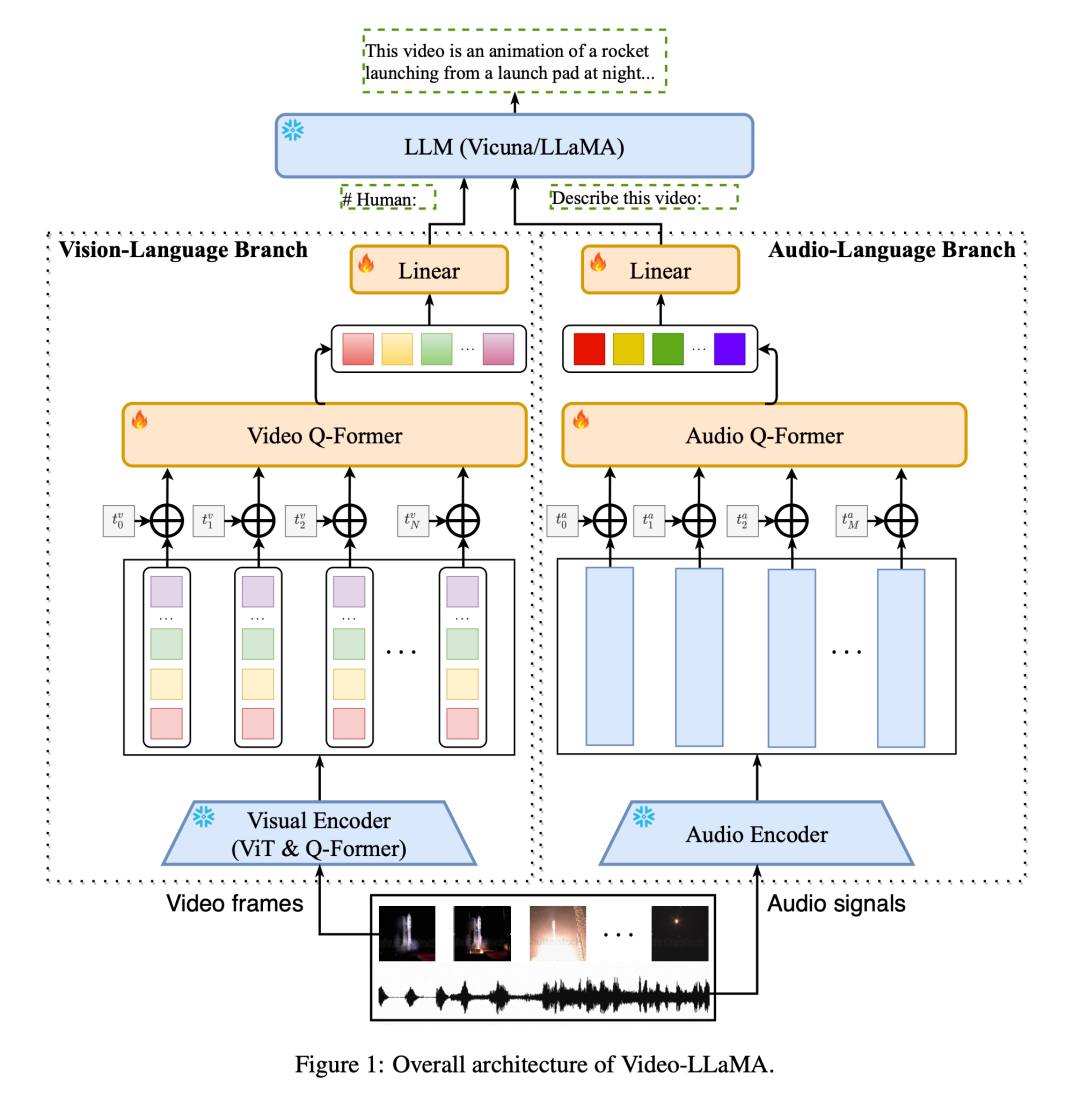
トレーニング コストを削減するために、Video-LLaMA は事前トレーニングされた画像/音声エンコーダーをフリーズし、ビジュアル ブランチとオーディオ ブランチの次のパラメーターのみを更新します: Video/Audio Q-Former 、位置コーディング層および線形層 (図 1 を参照)。
ビジョンとテキストの位置関係を学習するために、著者らはまず大規模なビデオテキストデータセット(WebVid-2M)と画像テキストデータセット(CC-595K)を使用してビジョンブランチを事前トレーニングしました。 )。その後、著者らは、MiniGPT-4、LLaVA の画像コマンド データ セットと、Video-Chat のビデオ コマンド データ セットを使用して微調整を行い、より優れたクロスモーダル コマンド追従機能を実現しました。
音声テキストの配置関係の学習に関しては、大規模で高品質な音声テキスト データが不足しているため、著者らはこの目標を達成するために回避策を採用しました。まず、オーディオ言語ブランチの学習可能なパラメーターの目標は、オーディオ エンコーダーの出力を LLM の埋め込み空間に合わせることで理解できます。オーディオ エンコーダ ImageBind には、非常に強力なマルチモーダル アライメント機能があり、さまざまなモダリティのエンベディングを共通の空間にアライメントできます。したがって、著者らはビジュアルテキストデータを使用してオーディオ言語ブランチをトレーニングし、ImageBind の共通埋め込み空間を LLM のテキスト埋め込み空間に位置合わせし、それによって音声モダリティと LLM テキスト埋め込み空間の位置合わせを実現します。この賢い方法により、Video-LLaMA は、音声データでトレーニングされていない場合でも、推論中に音声を理解する能力を実証できます。
著者は、Video-LLaMA のビデオ/オーディオ/画像ベースの対話の例をいくつか示します。
(1) 次の 2 つの例は、Video-LLaMA の包括的な視聴覚認識機能を示しています。例内の会話はオーディオ ビデオを中心に展開されます。例 2 では、画面には出演者のみが表示されますが、音は観客の歓声や拍手であり、モデルが視覚信号しか受信できない場合、観客の肯定的な反応を推測することはできません。オーディオには楽器の音はありませんが、写真にはサックスが映っていますが、聴覚信号しか受信できないモデルでは、プレーヤーがサックスを演奏したことはわかりません。

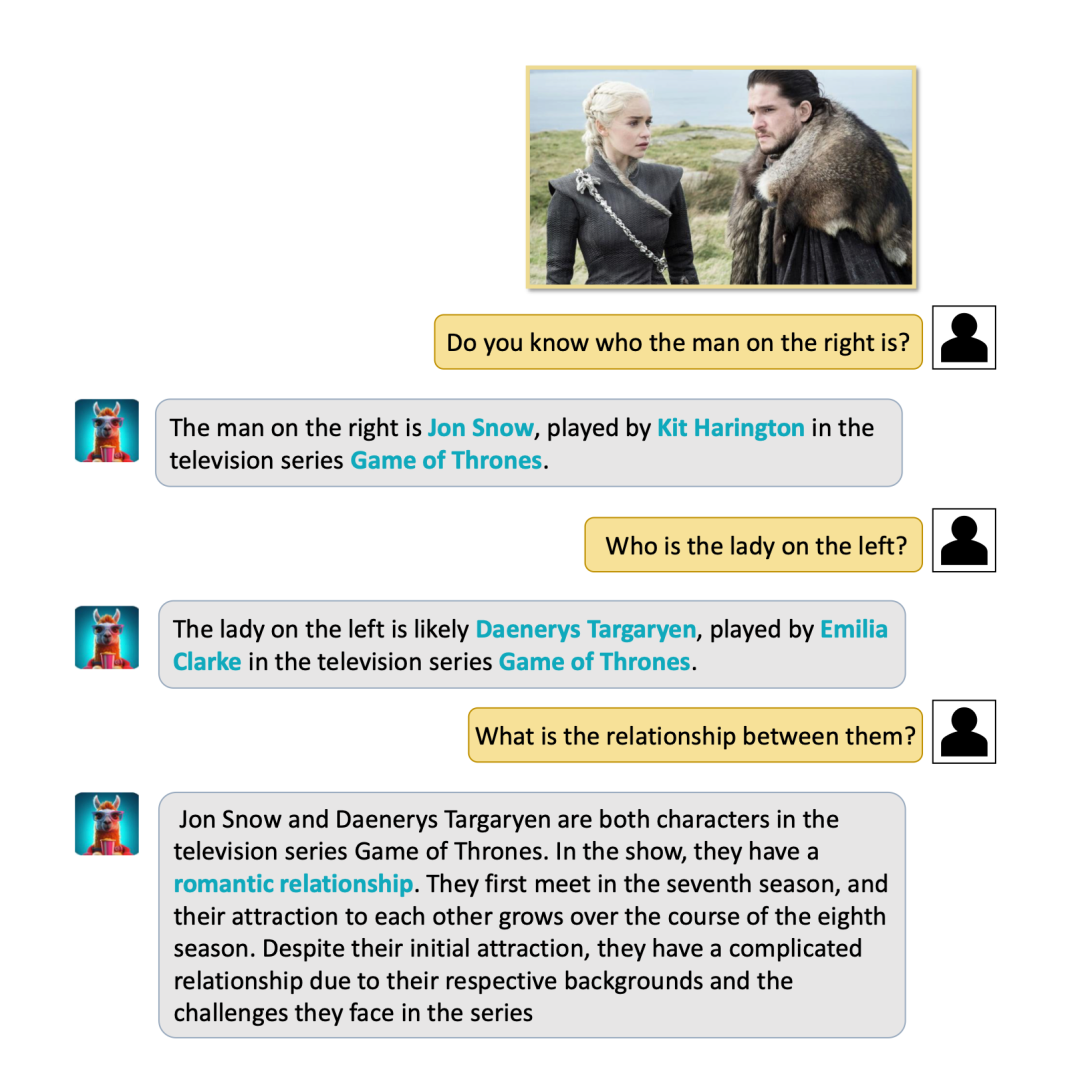
(2) Video-LLaMA は静止画像に対する強力な知覚理解能力も備えており、画像の説明、質問、および質問を完了することができます。回答 タスクを待ちます。


 概要
概要
(1) 限られた知覚能力: Video-LLaMA の視覚および聴覚能力はまだ比較的初歩的であり、複雑な視覚情報と音声情報を識別することは依然として困難です。理由の 1 つは、データ セットの品質とサイズが十分ではないことです。この研究グループは、モデルの知覚能力を向上させるために、高品質のオーディオ、ビデオ、テキストの配置データセットを構築することに熱心に取り組んでいます。
(2) 長いビデオの処理が難しい: 長いビデオ (映画やテレビ番組など) には大量の情報が含まれているため、モデルに高い推論能力とコンピューティング リソースが必要です。
(3) 言語モデルに固有の幻覚問題は、Video-LLaMA にも依然として存在します。
一般に、Video-LLaMA は、包括的なオーディオビジュアル機能を備えた大規模なモデルとして、オーディオとビデオの理解の分野で目覚ましい成果を達成しました。研究者が熱心に取り組み続けるにつれて、上記の課題は 1 つずつ克服され、オーディオとビデオの理解モデルが広範な実用的価値を持つようになるでしょう。
以上が大規模な言語モデルに包括的なオーディオビジュアル機能を追加し、DAMO アカデミーがソース Video-LLaMA をオープンしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



