



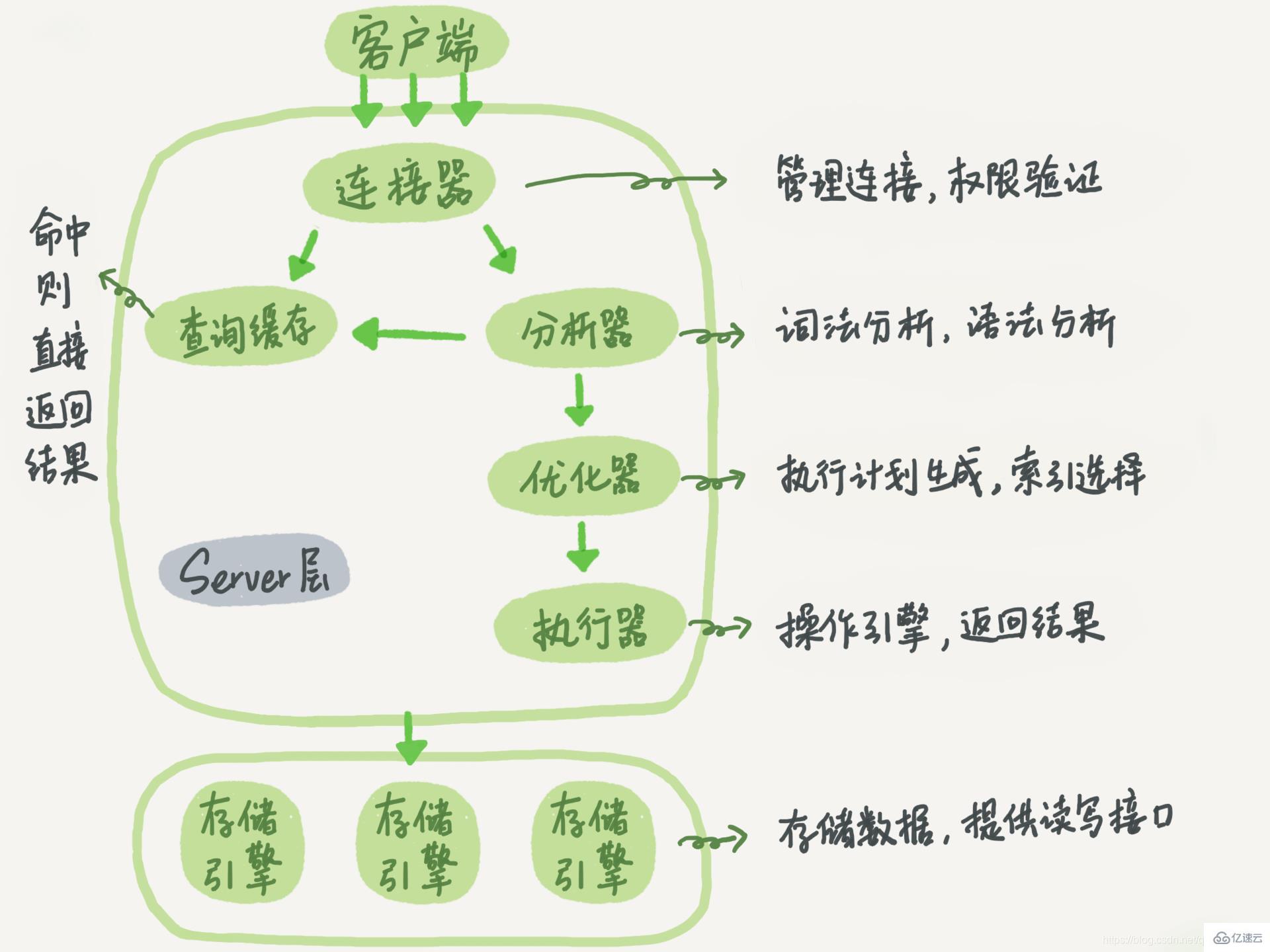
MySQL は、サーバー層とストレージ エンジン層の 2 つの部分に分けることができます
サーバー層には、コネクタ、クエリ キャッシュ、アナライザー、オプティマイザー、エグゼキューターなどが含まれており、MySQL のコア サービス機能のほとんどと、すべての組み込み関数 (日付、時刻、数学関数、暗号化関数など) をカバーします。など)、ストアド プロシージャ、トリガー、ビューなど、すべてのクロスストレージ エンジン機能はこの層で実装されます。
ストレージ エンジンは、データの保存と取得を担当します。プラグイン アーキテクチャ モデルに基づいた複数のストレージ エンジン (InnoDB、MyISAM、Memory など) をサポートできます。 InnoDB は現在最も一般的に使用されているストレージ エンジンであり、MySQL バージョン 5.5.5 以降はデフォルトのストレージ エンジンになっています。メモリ エンジンの実行を指定する方法は、engin=memoryを使用することです
異なるストレージ エンジンがサーバー層を共有します
mysql -h$ip -P$port -u$user -p

##しかし、長い接続をすべて使用した後、MySQL が占有するメモリが急速に増加する場合があります。これは、MySQL が実行中に一時的に使用するメモリが接続オブジェクトで管理されるためです。これらのリソースは、接続が切断されると解放されます。したがって、長い接続が蓄積されると、メモリを占有しすぎてシステムによって強制終了される可能性があります (OOM)。現象から判断すると、MySQL が異常に再起動します。
この問題は、次の 2 つの解決策で解決できます:
1. 長い接続は定期的に切断してください。プログラム内部の判断により、大量のメモリを消費するクエリを実行した場合、一定時間後に接続が切断されます。再度クエリする必要がある場合は、接続を再確立する必要があります
2。MySQL5.7 以降のバージョンを使用している場合は、比較的大規模なクエリを実行するたびに mysql_reset_connection を実行することで接続リソースを再初期化できます。手術。再説明: このプロセスでは再接続や権限の検証は必要ありませんが、接続ステータスは作成時の初期状態に戻ります
2. クエリ キャッシュ接続の確立completed その後、select ステートメントを実行できます。 MySQL はクエリ リクエストを取得すると、まずクエリ キャッシュに移動して、このステートメントが以前に実行されたかどうかを確認します。以前に実行されたステートメントとその結果は、キーと値のペアとしてメモリに直接キャッシュされる場合があります。キーはクエリ ステートメントであり、値はクエリ結果です。キーがキャッシュ内で見つかった場合、対応する値がクライアントに直接返されます。
可以将参数query_cache_type设置成DEMAND,这样对于默认的SQL语句都不使用查询缓存。而对于确定要是查询缓存的语句,可以用SQL_CACHE显示指定,如下面这条语句一样:
select SQL_CACHE * from T where ID=10;
MySQL8.0版本直接将查询缓存的整块功能删掉了
如果没有命中查询缓存,就要开始真正执行语句了。MySQL首先要对SQL语句做解析
分析器会先做词法分析。MySQL需要识别一条由多个字符串和空格组成的SQL语句,将其中的每个字符串识别并理解其代表的意义
select * from T where ID=10;
当输入select关键字时,MySQL会识别它为一个查询语句。它也要把字符串T识别成表名T,把字符串ID识别成列ID
做完了这些识别以后,就要做语法分析。基于词法分析的结果,语法分析器会依据MySQL语法规则来检查这个SQL语句是否符合规范。如果语法不对,就会收到"You have an error in your SQL syntax"的错误提示
经过了分析器,在开始执行之前,还要先经过优化器的处理
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联的时候,决定各个表的连接顺序
优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段,开始执行语句
开始执行的时候,要先判断一下你对这个表T有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示
mysql> select * from T where ID=10; ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口
比如在表T中,ID字段没有索引,那么执行器的执行流程是这样的:
1.调用InnoDB引擎接口取这个表的第一行,判断ID值是不是10,如果不是则跳过,如果是则将这个行存在结果集中
2.调用引擎接口取下一行,重复相同的判断逻辑,直到取到这个表的最后一行
3.执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端
在慢查询日志中可以查看到一个名为rows_examined的字段,其表示执行该语句所扫描的行数。这个值就是在执行器每次调用引擎获取数据行的时候累加的
在有些场景下,执行器调用一次,在引起内部则扫描了多行,因此引擎扫描行数跟rows_examined并不是完全相同的
表T的创建语句如下,这个表有一个主键ID和一个整型字段c:
create table T(ID int primary key, c int);
如果要将ID=2这一行的值加1,SQL语句如下:
update T set c=c+1 where ID=2;
在MySQL中,如果每次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程IO成本、查找成本都很高。MySQL里常说的WAL技术,全称是Write-Ahead Logging,它的关键点就是先写日志,再写磁盘
当有一条记录需要更新的时候,InnoDB引擎就会把记录写到redo log里面,并更新buffer pool的page,这个时候更新就算完成了
buffer pool是物理页的缓存,对InnoDB的任何修改操作都会首先在buffer pool的page上进行,然后这样的页面将被标记为脏页并被放到专门的flush list上,后续将由专门的刷脏线程阶段性的将这些页面写入磁盘
InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,从头开始写,写到末尾就又回到开头循环写
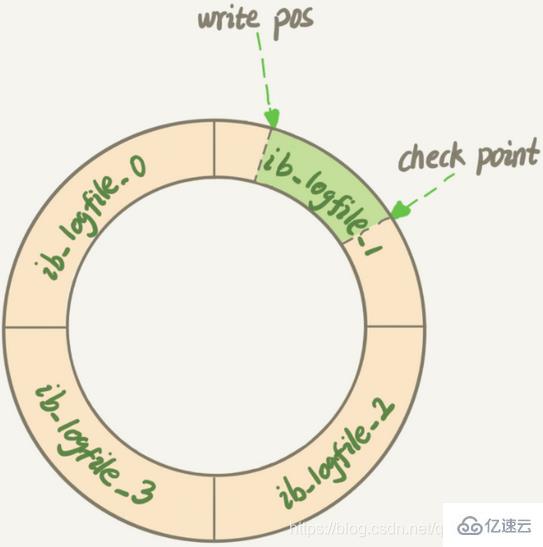
write pos是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。check point是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
write pos和check point之间空着的部分,可以用来记录新的操作。如果write pos追上check point,这时候不能再执行新的更新,需要停下来擦掉一些记录,把check point推进一下
有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe
MySQL整体来看就有两块:一块是Server层,主要做的是MySQL功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。InnoDB引擎拥有一种特定的日志称为redo log,而Server层也有其自己的日志,被称为binlog
为什么会有两份日志?
MySQL には最初から InnoDB エンジンがなかったからです。 MySQL に付属するエンジンは MyISAM ですが、MyISAM にはクラッシュセーフ機能がなく、binlog ログはアーカイブにのみ使用できます。 InnoDB は、プラグインの形式で MySQL に導入されます。binlog のみに依存するとクラッシュ セーフ機能がないため、InnoDB は REDO ログを使用してクラッシュ セーフ機能を実装します。
binlog ログ フォーマット:
binlog には 3 つの形式があります: STATEMENT、ROW、MIXED
1)、STATEMENT モード
SQL ステートメントはバイナリログに記録されます。利点は、データの変更を各行に記録する必要がないため、binlog ログの量が減り、IO が節約され、パフォーマンスが向上することです。欠点は、場合によってはマスターとスレーブ内のデータが不整合になることです (sleep() 関数、last_insert_id()、ユーザー定義関数 (udf) などが問題を引き起こします)
2 )、ROW モード
# では、各 SQL ステートメントのコンテキスト情報を記録することなく、変更されたデータと変更されたステータスのみを記録する必要があります。また、特定の状況下でストアド プロシージャや関数、トリガーの呼び出しやトリガーが正しくコピーされないという問題は発生しません。欠点は、特にテーブルの変更操作を実行するときに大量のログが生成され、ログが急速に増加することです。
#3)、MIXED モード
上記の 2 つのモードを混合して使用します。一般的なレプリケーションでは STATEMENT モードを使用してバイナリ ログを保存します。STATEMENT モードでコピーできない操作の場合は、ROW モードを使用してバイナリ ログを保存します。MySQL は実行された SQL ステートメントに基づいてログの保存方法を選択します
1.REDO ログは InnoDB エンジンに固有であり、binlog は MySQL のサーバー層によって実装され、すべてのエンジンで使用できます。
#2.redo ログは物理ログであり、ログは特定のデータに加えられた変更を記録します。binlog は論理ログで、ステートメントの元のロジックを記録します。たとえば、1## を追加します。 ID=2の行のcフィールドに#3を書き込む REDOログはループで書き込まれるため常に容量を使い果たしますが、binlogは追加で書き込むことができます binlogファイルが一定サイズに達すると、 に切り替わります次のログは上書きされません。
4. 2 段階の送信1. エグゼキュータは最初にエンジンを見つけて、この行で ID =2 を取得します。 ID が主キーであり、エンジンはツリー検索を直接使用してこの行を見つけます。 ID=2 の行のデータが既にメモリ内にある場合は、そのデータが直接実行プログラムに返されますが、それ以外の場合は、ディスクからメモリに読み取られてから返される必要があります。エグゼキューターはエンジンに行データを取得し、この値に 1 を加算して新しいデータ行を取得し、エンジン インターフェイスを呼び出してこの新しいデータ行
3 を書き込みます。エンジンはこの新しい行を更新します。データをメモリに読み込んで更新します 操作はREDOログに記録されますが、この時点でREDOログは準備状態になっています。次に、実行が完了し、いつでもトランザクションを送信できることを実行者に通知します (
4)。実行者は、この操作のバイナリログを生成し、そのバイナリログをディスクに書き込みます
5。 executor がエンジンのコミット トランザクション インターフェイスを呼び出し、エンジンは書き込まれたばかりの REDO ログを送信済みの状態に変更し、更新が完了します。
update ステートメントの実行フローチャートは次のとおりです。図は InnoDB 内で実行されることを示し、黒いボックスはエグゼキューターで実行されることを示します。
# で実行されると、REDO ログの書き込みが 2 つのステップに分割されます。準備とコミット。これは 2 段階のコミットです。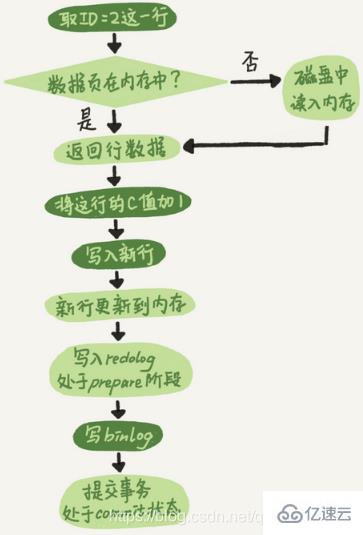 REDO ログと Binlog は 2 つの独立したロジックであるため、2 段階の送信が必要ない場合は、最初に REDO ログを書き込んでから binlog を書き込むか、最初に binlog を書き込み、次に REDO ログを書き込みます
REDO ログと Binlog は 2 つの独立したロジックであるため、2 段階の送信が必要ない場合は、最初に REDO ログを書き込んでから binlog を書き込むか、最初に binlog を書き込み、次に REDO ログを書き込みます
1.最初に REDO ログを書き込み、次に binlog を書き込みます。 REDO ログは書き込まれたが、バイナリログはまだ書き込まれていないときに、MySQL プロセスが異常に再起動した場合。 REDO ログが書き込まれた後は、システムがクラッシュしてもデータを回復できるため、回復後のこの行の c の値は 1 になります。ただし、バイナリログが完了する前にクラッシュしたため、このステートメントはこの時点ではバイナリログには記録されませんでした。バイナリログに記録されたこの行の c の値は 0
2 です。最初にバイナリログを書き込み、次にバイナリログを書き込みます。やり直しログ。 binlog の書き込み後にクラッシュが発生した場合、REDO ログはまだ書き込まれていないため、クラッシュ回復後のトランザクションは無効になるため、この行の c の値は 0 になります。ただし、binlog には、c を 0 から 1 に変更するログがすでに記録されています。したがって、バイナリログリカバリを使用すると、トランザクションが 1 つ多くなり、最終的に回復されるカラム c の値は 1
2 フェーズコミットが使用されない場合、データベースの状態はライブラリの状態と異なる可能性があります。ログリカバリの使用に一貫性がありません。 REDO ログと binlog の両方を使用して、トランザクションのコミット ステータスを表すことができます。2 段階コミットは、2 つの状態の論理的な一貫性を維持するために使用されます。
REDO ログは、クラッシュ セーフ機能を確保するために使用されます。 innodb_flush_log_at_trx_commit パラメータが 1 に設定されている場合、各トランザクションの REDO ログがディスクに直接永続化され、MySQL が異常に再起動した後にデータが失われないことが保証されます。 1 に設定すると、すべてのトランザクションのバイナリログがディスクに永続化され、MySQL が異常に再起動した後でもバイナリログが失われないことを意味します。
当内存数据页跟磁盘数据页不一致的时候,我们称这个内存页为脏页。当内存数据被写入磁盘后,内存和磁盘上的数据页就会保持一致,这种状态被称为“干净页”
第一种场景是,InnoDB的redo log写满了,这时候系统会停止所有更新操作,把checkpoint往前推进,redo log留出空间可以继续写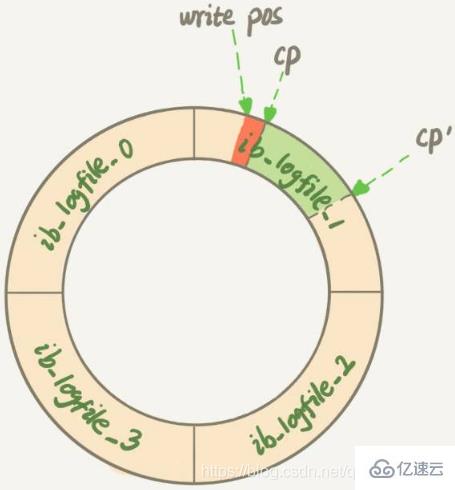
checkpoint位置从CP推进到CP’,就需要将两个点之间的日志对应的所有脏页都flush到磁盘上。之后,上图中从write pos到CP’之间就是可以再写入的redo log的区域
第二种场景是,系统内存不足。当内存空间不足以分配新的内存页时,系统会选择淘汰一些数据页来腾出内存空间以供其他数据页使用。如果淘汰的是脏页,就要先将脏页写到磁盘
这时候不能直接把内存淘汰掉,下次需要请求的时候,从磁盘读入数据页,然后拿redo log出来应用不就行了?
这里是从性能考虑的。如果刷脏页一定会写盘,就保证了每个数据页有两种状态:一种是内存里存在,内存里就肯定是正确的结果,直接返回;另一种是内存里没有数据,就可以肯定数据文件上是正确的结果,读入内存后返回。这样的效率最高
第三种场景是,MySQL认为系统空闲的时候刷脏页,当然在系统忙的时候也要找时间刷一点脏页
第四种场景是,MySQL正常关闭的时候会把内存的脏页都flush到磁盘上,这样下次MySQL启动的时候,就可以直接从磁盘上读数据,启动速度会很快
redo log写满了,要flush脏页,出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住
内存不够用了,要先将脏页写到磁盘,这种情况是常态。InnoDB用缓冲池管理内存,缓冲池中的内存页有三种状态:
第一种是还没有使用的
第二种是使用了并且是干净页
第三种是使用了并且是脏页
InnoDB的策略是尽量使用内存,因此对于一个长时间运行的库来说,未被使用的页面很少
如果要读取的数据页不在内存中,则需要从缓冲池中请求一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页,即必须将脏页先刷到磁盘,变成干净页后才能复用
刷页虽然是常态,但是出现以下两种情况,都是会明显影响性能的:
一个查询要淘汰的脏页个数太多,会导致查询的响应时间明显变长
日志写满,更新全部堵住,写性能跌为0,这种情况对敏感业务来说,是不能接受的
首先,要正确地告诉InnoDB所在主机的IO能力,这样InnoDB才能知道需要全力刷脏页的时候,可以刷多快。参数为innodb_io_capacity,建议设置成磁盘的IOPS
考虑到脏页比例和redo log写入速度,InnoDB的刷盘速度得到优化。默认值为75%,参数innodb_max_dirty_pages_pct限制了脏页的比例。脏页比例是通过Innodb_buffer_pool_pages_dirty/Innodb_buffer_pool_pages_total得到的,SQL语句如下:
mysql> select VARIABLE_VALUE into @a from performance_schema.global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty'; select VARIABLE_VALUE into @b from performance_schema.global_status where VARIABLE_NAME = 'Innodb_buffer_pool_pages_total'; select @a/@b;
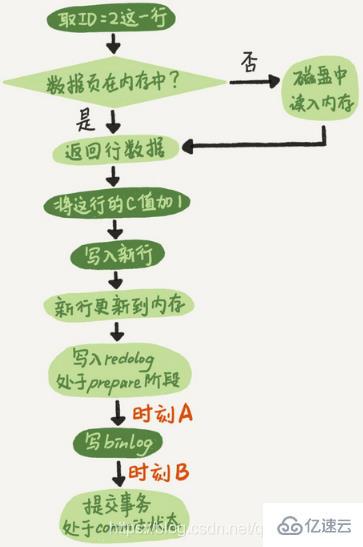
问题一:在两阶段提交的不同时刻,MySQL异常重启会出现什么现象
如果在图中时刻A的地方,也就是写入redo log处于prepare阶段之后、写binlog之前,发生了崩溃,由于此时binlog还没写,redo log也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog还没写,所以也不会传到备库
如果在图中时刻B的地方,也就是binlog写完,redo log还没commit前发生崩溃,那崩溃恢复的时候MySQL怎么处理?
崩溃恢复时的判断规则:
1)如果redo log里面的事务是完整的,也就是已经有了commit标识,则直接提交
2)如果redo log里面的事务只有完整的prepare,则判断对应的事务binlog是否存在并完整
a.如果完整,则提交事务
b.否则,回滚事务
时刻B发生崩溃对应的就是2(a)的情况,崩溃恢复过程中事务会被提交
问题二:MySQL怎么知道binlog是完整的?
一个事务的binlog是有完整格式的:
statement格式的binlog,最后会有COMMIT
row格式的binlog,最后会有一个XID event
问题三:redo log和binlog是怎么关联起来的?
它们有一个共同的数据字段,叫XID。崩溃恢复的时候,会按顺序扫描redo log:
如果碰到既有prepare、又有commit的redo log,就直接提交
如果碰到只有prepare、而没有commit的redo log,就拿着XID去binlog找对应的事务
问题四:redo log一般设置多大?
如果是现在常见的几个TB的磁盘的话,redo log设置为4个文件、每个文件1GB
问题五:正常运行中的实例,数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在数据最终落盘是由redo log更新过去的情况
脏页是指在正常运行的实例中,当数据页被修改后,与存储在磁盘上的数据页不一致。最终数据落盘,就是把内存中的数据页写盘。这个过程,甚至与redo log毫无关系
2.在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它对到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态
问题六:redo log buffer是什么?是先修改内存,还是先写redo log文件?
在一个事务的更新过程中,日志是要写多次的。比如下面这个事务:
begin;insert into t1 ...insert into t2 ...commit;
这个事务要往两个表中插入记录,插入数据的过程中,生成的日志都得先保存起来,但又不能在还没commit的时候就直接写到redo log文件里
所以,redo log buffer就是一块内存,用来先存redo日志的。也就是说,在执行第一个insert的时候,数据的内存被修改了,redo log buffer也写入了日志。在执行commit语句时,才真正将日志写入redo log文件
只要redo log和binlog保证持久化到磁盘,就能确保MySQL异常重启后,数据可以恢复
事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog文件中。无法分割一个事务的binlog,因此无论该事务有多大,都必须确保一次性写入
系统给binlog cache分配了一片内存,每个线程一个,参数binlog_cache_size用于控制单个线程内binlog cache所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘
事务提交的时候,执行器把binlog cache里的完整事务写入到binlog中,并清空binlog cache
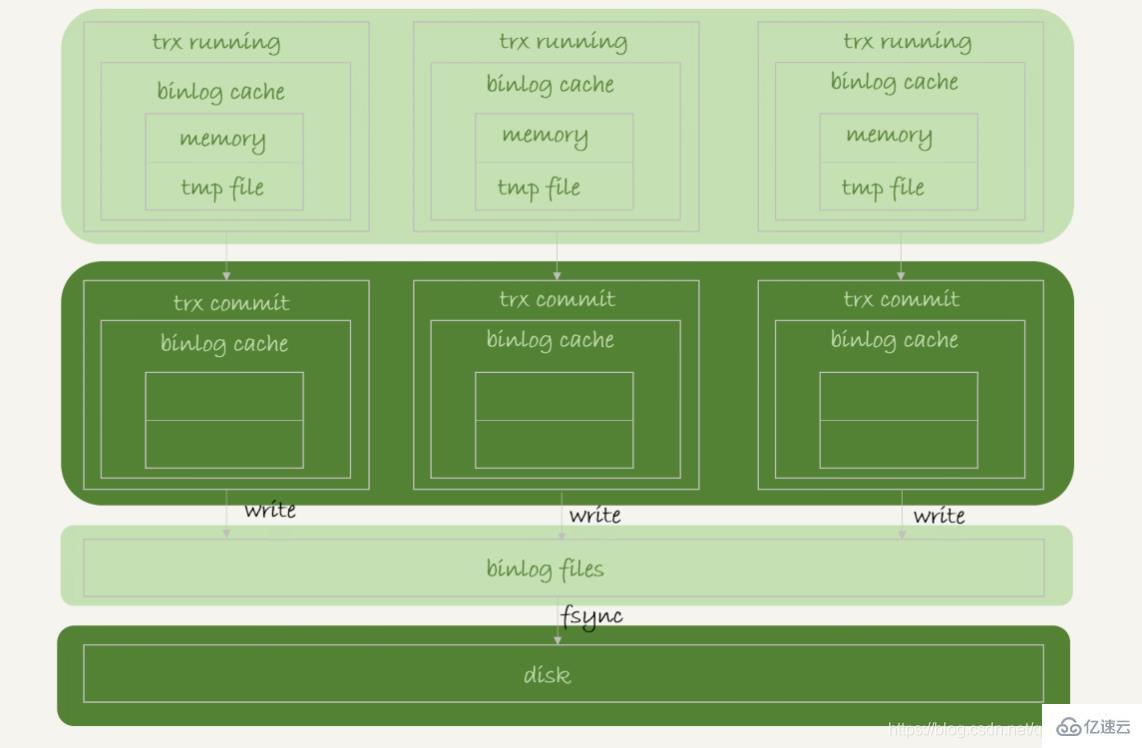
每个线程有自己binlog cache,但是共用一份binlog文件
图中的write,指的就是把日志写入到文件系统的page cache,并没有把数据持久化到磁盘,所以速度比较快
图中的fsync,才是将数据持久化到磁盘的操作。一般情况下认为fsync才占磁盘的IOPS
write和fsync的时机,是由参数sync_binlog控制的:
sync_binlog=0的时候,表示每次提交事务都只write,不fsync
sync_binlog=1的时候,表示每次提交事务都会执行fsync
sync_binlog=N(N>1)的时候,表示每次提交事务都write,但累积N个事务后才fsync
因此,在出现IO瓶颈的场景中,将sync_binlog设置成一个比较大的值,可以提升性能,对应的风险是:如果主机发生异常重启,会丢失最近N个事务的binlog日志
在执行事务过程中所产生的 redo log 需要先写入 redo log 缓存。redo log buffer里面的内容不是每次生成后都要直接持久化到磁盘,也有可能在事务还没提交的时候,redo log buffer中的部分日志被持久化到磁盘
redo log可能存在三种状态,对应下图的三个颜色块

这三张状态分别是:
REDO ログ バッファ内、物理的には MySQL プロセス メモリ内に存在します。図の赤い部分です。
はディスクに書き込まれますが、は永続化されず、ファイル システムのページ キャッシュ (図の黄色の部分) に物理的に保存されます。
はディスク (ハード ディスクに対応) に永続化されます。図の緑色の部分
REDO ログ バッファへのログの書き込みとページ キャッシュへの書き込みはどちらも非常に高速ですが、ディスクへの永続化ははるかに遅くなります
REDO ログの書き込み戦略では、InnoDB は innodb_flush_log_at_trx_commit パラメータを提供します。これには 3 つの可能な値があります:
0 に設定すると、毎回 REDO ログのみが REDO ログに残ることを意味します。トランザクションがコミットされます。バッファ内の
が 1 に設定されている場合、トランザクションが送信されるたびに REDO ログがディスクに直接保存されることを意味します。
コミットされていないトランザクションの REDO ログがディスクに書き込まれるシナリオは 2 つあります。
1. REDO ログ バッファが占める領域が innodb_log_buffer_size の半分に達しようとすると、バックグラウンド スレッドがディスクに積極的に書き込みます。トランザクションが送信されていないため、ディスク書き込みアクションは fsync を呼び出さずに書き込みのみになります。つまり、ファイル システムのページ キャッシュにのみ残ります
2。並列トランザクションが送信されると、このトランザクションは偶然に行われ、ログ バッファはディスクに保存されます。トランザクション A が実行途中で、REDO ログがバッファに書き込まれているとします。この時点で、別のスレッドからトランザクション B が送信されます。innodb_flush_log_at_trx_commit が 1 に設定されている場合、トランザクション B は、REDO ログ バッファ内のすべてのログを永続化します。ディスク。このとき、トランザクション A に関連する REDO ログ バッファも一緒にディスクに記録されます
2 段階コミット タイミングとしては、まず REDO ログが用意され、次に binlog が書き込まれ、最後に REDO ログが書き込まれます。専念 。 innodb_flush_log_at_trx_commit が 1 に設定されている場合、REDO ログは準備フェーズで一度永続化される必要があります。
MySQL の 2 つの 1 構成は、sync_binlog と innodb_flush_log_at_trx_commit の両方が 1 に設定されることを意味します。つまり、トランザクションが完全にコミットされる前に、REDO ログ (準備段階) 用と binlog 用の 2 回のディスク フラッシュを待つ必要があります。
#3. グループ送信メカニズム
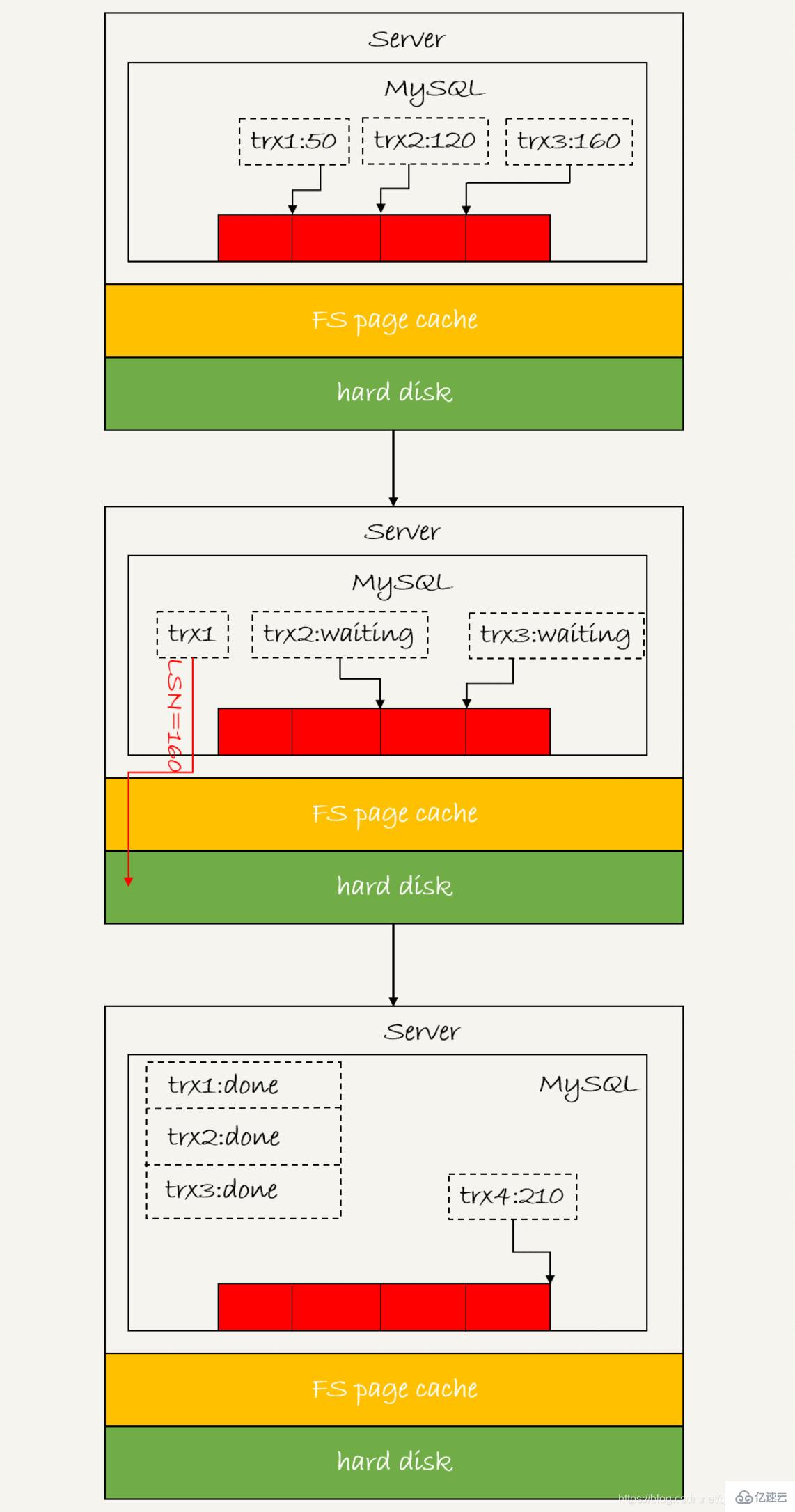 1.trx1 が最初に到着し、このグループのリーダーとして選択されます
1.trx1 が最初に到着し、このグループのリーダーとして選択されます
バイナリはグループで送信することもできます。上図のステップ 4 を実行してバイナリをディスクに fsync するときに、複数のトランザクションのバイナリが書き込まれている場合、それらは永続化されます。これにより、IOPS の消費も削減できます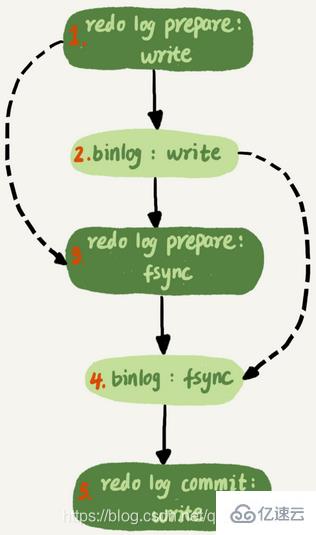
を呼び出す前に蓄積する回数を示します。これら 2 つの条件のいずれかが満たされている限り、 fsync が呼び出されます。
WAL メカニズムは主に 2 つの側面から恩恵を受けます。
REDO ログと binlog は両方ともシーケンシャルに書き込まれます。ディスクへのシーケンシャル書き込みは、ランダム書き込みよりも高速です。
1. binlog_group_commit_sync_lay を設定する(遅延 fsync が呼び出されるまでのマイクロ秒数) および binlog_group_commit_sync_no_delay_count (fsync が呼び出されるまでに蓄積される回数) パラメーターを使用して、ディスクへの binlog 書き込みの数を減らします。この方法ではステートメントの応答時間が増加する可能性がありますが、意図的に待機することで実現されるため、データ損失のリスクはありません。
2. sync_binlog を 1 より大きい値に設定します (各トランザクションは書き込みをコミットしますが、 N 個のトランザクションを蓄積した後の fsync)。これを実行すると、ホストの電源がオフになると binlog ログが失われるというリスクがあります。
3. innodb_flush_log_at_trx_commit を 2 に設定します (トランザクションがコミットされるたびに、REDO ログのみがページ キャッシュに書き込まれます)。これを行うリスクは、ホストの電源が切れたときにデータが失われることです
以上がMySQL インフラストラクチャとログ システムの例の分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



