


結合操作を実行するときに mysql がどのように動作するかを見てみましょう。一般的な結合方法は何ですか?
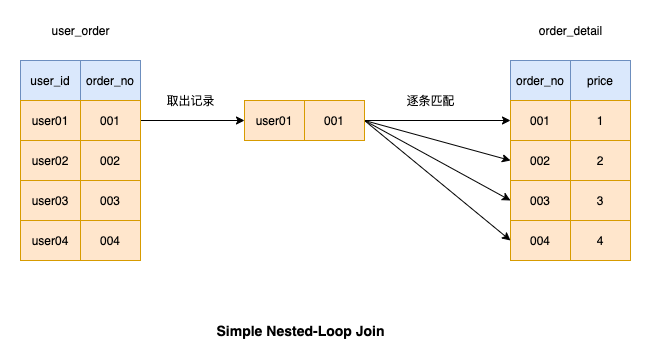
図に示すように、接続操作を実行すると、左側のテーブルは ドライバー テーブル、右側のテーブルは駆動テーブル
単純なネストループ結合 この結合操作は、駆動テーブルからレコードを取得し、駆動テーブルのレコードを 1 つずつ照合することです。条件が一致する場合、結果が返されます。次に、ドライバー テーブル内のすべてのデータが一致するまで、ドライバー テーブル内の次のレコードの照合を続けます。
毎回ドライバー テーブルからデータをフェッチするのは時間がかかるため、MySQL はこのアルゴリズムは使用しないでください。 結合操作を実行するには
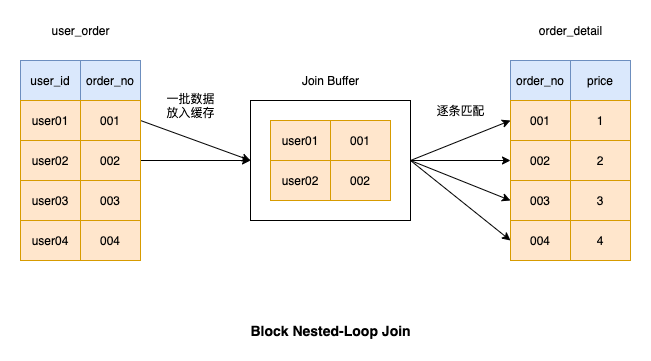
時間のかかるデータの取得を避けるため、ドライバー テーブルのバッチを追加するたびに、データがドライバー テーブルから一度に取得され、メモリ内で照合されます。このデータのバッチが一致すると、ドライバー テーブル内のすべてのデータが一致するまで、データのバッチがドライバー テーブルからフェッチされ、メモリに配置されます。
バッチ データの取得により、多くの IO 操作が削減されます。 , そのため、実行効率が比較的高いです. この種の接続操作は MySQL でも使用されます
ちなみに、このメモリには MySQ では結合バッファと呼ばれる正式な名前があります. 次のステートメントを実行して表示できます結合バッファのサイズ
show variables like '%join_buffer%'

前に使用したsingle_tableテーブルを移動し、single_tableテーブルに基づいて2つのテーブルを作成し、各テーブルに1wのランダムなレコードを挿入します
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
create table t1 like single_table;
create table t2 like single_table;join ステートメントを直接使用する場合、MySQL の最適化サーバーは駆動テーブルとしてテーブル t1 または t2 を選択する可能性があり、これは SQL ステートメントの分析プロセスに影響を与えるため、mysql に固定接続方法を使用させるために、straight_join を使用します。クエリを実行するには
select * from t1 straight_join t2 on (t1.common_field = t2.common_field)
実行時間は0.035秒です

実行計画は次のとおりです

「結合バッファーの使用」が「追加」列に表示されます。これは、接続操作が Block Nested -Loop Join アルゴリズム
に基づいていることを示しています。 Block Nested-Loop Join アルゴリズムを理解すると、ドライバー テーブルの各レコードがドリブン テーブルのすべてのレコードと一致するのに非常に時間がかかることがわかります。改善されるでしょうか?
あなたもこのアルゴリズムを考えたことがあると思います。このアルゴリズムは、図に示すように、駆動テーブルによって接続された列にインデックスを追加することで、一致プロセスが非常に高速になります。
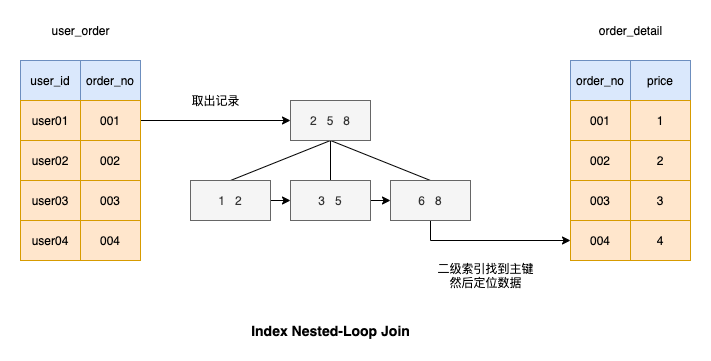 インデックス列に基づく結合に基づくクエリの実行速度を見てみましょう。
インデックス列に基づく結合に基づくクエリの実行速度を見てみましょう。
select * from t1 straight_join t2 on (t1.id = t2.id)
実行時間は0.001秒で、通常の列ベースで接続するよりも1段以上速いことがわかります。
 実行時間は0.001秒です。計画は次のとおりです
実行時間は0.001秒です。計画は次のとおりです

ドライバーテーブルはどのように選択すればよいですか?
次のように仮定します。ドライバー テーブルの行数は M なので、ドライバー テーブルの M 行をスキャンする必要があります。
毎回、駆動テーブルからデータの行を取得するときは、最初にインデックス a を検索する必要があります。そして主キーインデックスを検索します。駆動テーブルの行数は N です。毎回ツリーを検索するおおよその複雑さは底 2 N の対数であるため、駆動テーブル上の行を検索する時間計算量は 2\l o g 2 N 2*log2^N 2\log2N
Each となります。ドライバー テーブル内のデータ行は、駆動テーブルで 1 回検索する必要があります。実行プロセス全体のおおよその複雑さは、M M∗ 2∗ l o g 2 N M M*2*log2^N M M∗2∗log2N
## です。#明らかに M はスキャンされる行数に大きな影響を与えるため、小さなテーブルを駆動テーブルとして使用する必要があります。もちろん、この結論の前提は、駆動テーブルのインデックスが使用できることです。
つまり、小さなテーブルを駆動テーブルにするだけで済みます。
結合ステートメントの実行が遅い場合は、次の方法で最適化できます
以上がMySQL で join ステートメントを最適化する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



