



インデックスは、MySQL がデータを効率的に取得するのに役立つ順序付けされたデータ構造であり、MySQL 公式のインデックスの定義です。クエリの効率を向上させるために、インデックスはデータベース テーブルのフィールドに追加されるメカニズムです。データベース システムは、データに加えて、特定の検索アルゴリズムを満たすデータ構造も維持します。これらのデータ構造は、何らかの方法でデータを参照 (ポイント) するため、これらのデータ構造に高度な検索アルゴリズムを実装できます。このデータ構造は、索引。 。以下の図に示すように:
実際、簡単に言うと、インデックスはソートされたデータ構造です。
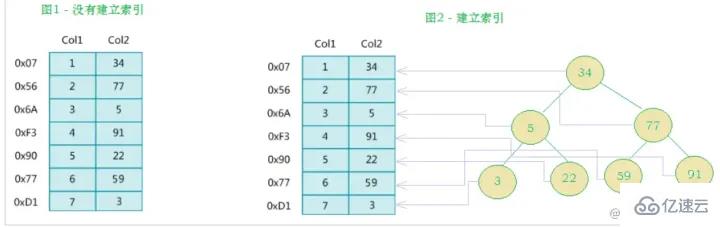
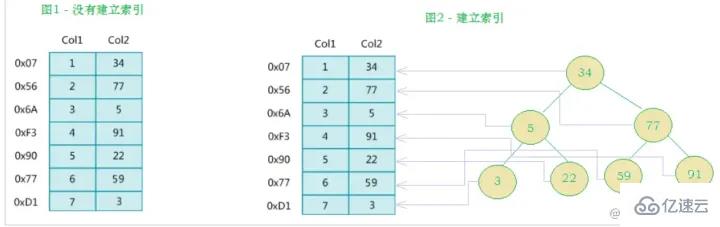
左側データ テーブルには合計 2 列と 7 つのレコードがあり、一番左はデータ レコードの物理アドレスです (論理的に隣接するレコードがディスク上で物理的に隣接しているとは限らないことに注意してください)。 Col2 の検索を高速化するために、右に示すようにバイナリ検索ツリーを維持できます。各ノードには、インデックス キー値と、対応するデータ レコードの物理アドレスへのポインタが含まれています。 なので、二分検索を使用して、対応するデータをすばやく取得できます。
インデックスの利点検索とソートの速度を高速化し、データベースのIOコストを削減します。 CPU 消費量
テーブルであり、主キー、インデックスのフィールド、ポイントが保存されます。エンティティへのクラス レコード自体がスペースを占有する必要があります
を指す インデックス ツリーのノードを変更する必要がある場合があります
しかし実際には、MySQL に保存するために二分探索ツリーでは、ここのノードは 1 つのデータのみを保存でき、ノードは MySQL のディスク ブロックに対応するため、毎回 1 つのディスク ブロックを読み取ることを知っておく必要があります。データは 1 つしか取得できず、効率が非常に悪いので、バイナリ検索ツリー を使用しません。なぜでしょうか?
B-tree 構造を使用して格納することを考えます。
インデックス構造インデックスは、サーバー層ではなく、MySQL のストレージ エンジン層に実装されます。したがって、インデックスはストレージ エンジン間で異なる場合があり、すべてのエンジンがすべての種類のインデックスをサポートしているわけではありません。BTREE インデックス: 最も一般的なインデックス タイプで、ほとんどのインデックスが B ツリー インデックスをサポートします。
HASH Index: メモリ エンジンによってのみサポートされており、使用シナリオは簡単です。
R ツリー インデックス (空間インデックス) : 空間インデックスは MyISAM エンジンの特殊なインデックス タイプで、主に地理空間データ タイプに使用されますが、通常はあまり使用されません。特別な紹介は行いません。
フルテキスト (フルテキスト インデックス) : フルテキスト インデックスも MyISAM の特殊なインデックス タイプで、主にフルテキスト インデックスに使用されます。 Mysql5.6 バージョンから全文インデックスをサポートします。
| #INNODB エンジン | #MYISAM エンジン |
##メモリ エンジン | ##BTREE インデックス |
|||||||||||
| サポート | サポート済み | HASH インデックス | ##サポートされていません||||||||||||
| ## サポートされていません | サポートされている | R ツリー インデックス | サポートされていません | |||||||||||
| サポート | サポート対象外 | 全文 | バージョン 5.6 以降でサポートされます | |||||||||||
| サポートされます | サポートされません |
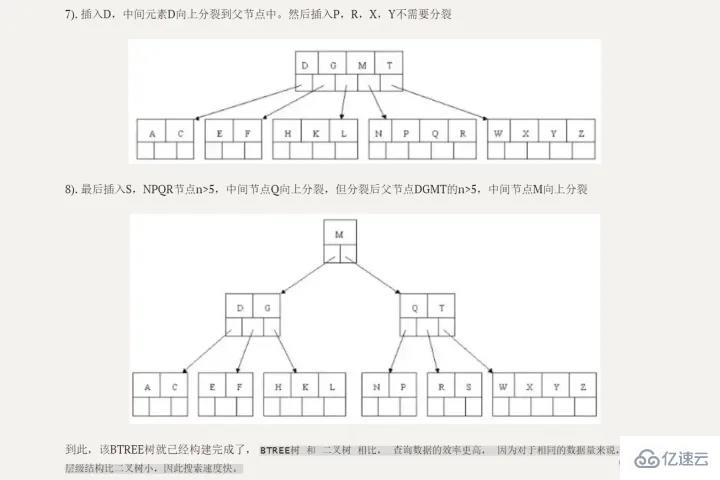
明示的に指定しない限り、通常参照するインデックスは、B ツリー (多方向検索ツリー、必ずしもバイナリである必要はない) 構造を使用して編成されています。クラスター化インデックス、複合インデックス、プレフィックス インデックス、およびインデックスと呼ばれる一意のインデックスはすべて、デフォルトで B ツリー インデックスを使用します。 BTREEマルチパスバランス検索ツリー、m 次 (m フォーク) BTREE は次の条件を満たします:
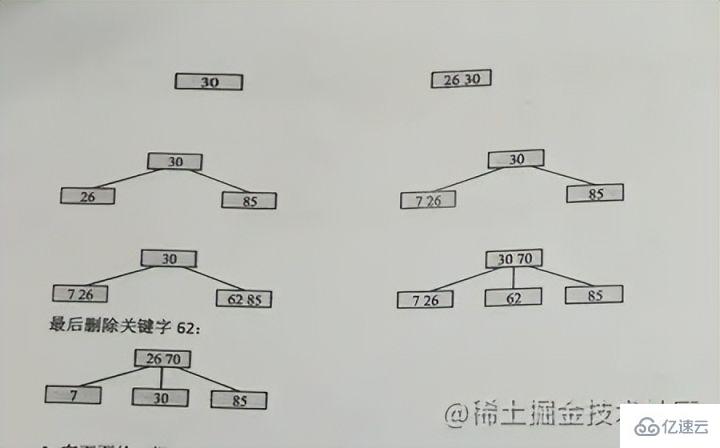
#キーワード case の挿入
つまり: になります。 70 を再度図に挿入すると、たまたま 70 が中央の上の位置になり、その後 62 が維持され、再び 85 になります 新しいノードを分割します
同じ理由で上方向に分割し続けます
B Tree のクエリ効率はより安定しています
が形成され、シーケンシャル ポインタを備えた B ツリーが形成され、改善されます。インターバルアクセスのパフォーマンス。 注意深い生徒なら、この図と二分探索ツリー図の最大の違いは何であるかがわかるでしょうか?
##二分探索ツリー図:
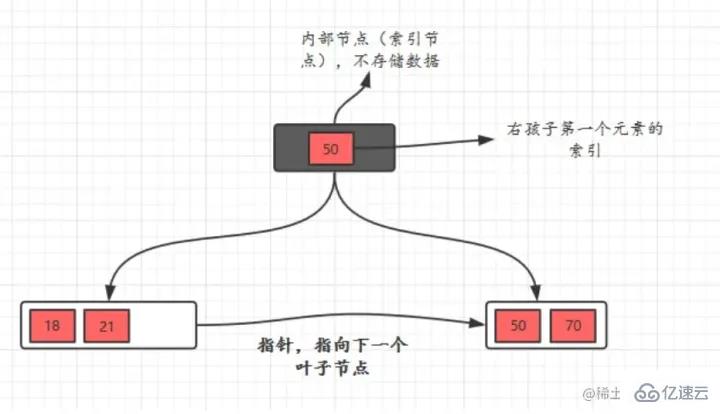
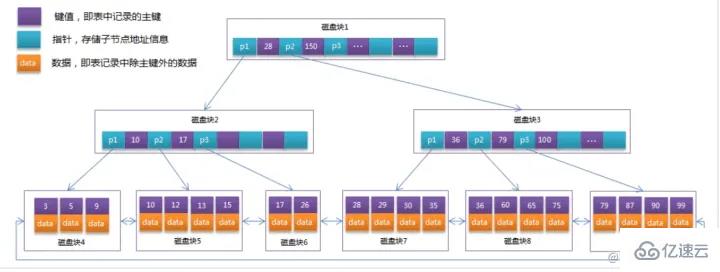
インデックスの原理 BTree インデックス: たとえば、ディスク ブロック 1 には、ポインター P1、P2、および P3 を含むデータ項目 17 と 35 が含まれています。P1 は、17 ブロック未満のディスクを表します。 、P2 は 17 ~ 35 のディスク ブロックを表し、P3 は 35 より大きいディスク ブロックを表します。
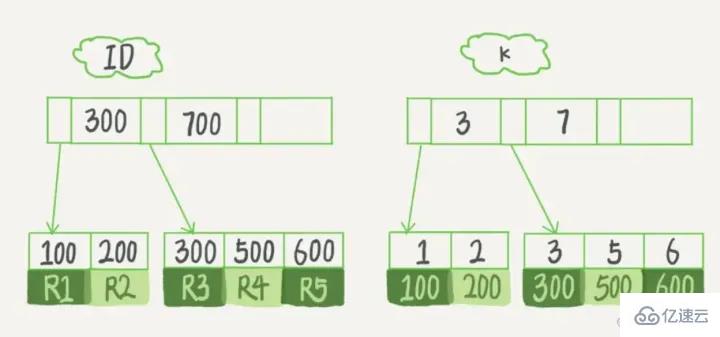
検索プロセスデータ項目 29 を検索する場合、最初にディスク ブロック 1 がディスクからメモリにロードされ、この時点で IO が発生します。メモリ内で二分探索を使用して、29 が 17 ~ 35 の間にあることを確認し、ディスク ブロック 1 の P2 ポインタをロックします。メモリ時間は (ディスクの IO と比較して) 非常に短いため、無視できます。ディスクを使用します。ディスク ブロック 1 からディスク ブロック 3 の P2 ポインタのアドレスがディスクからメモリにロードされます。2 番目の IO が発生します。29 は 26 と 30 の間にあります。ディスク ブロック 3 の P2 ポインタはロックされています。ディスク ブロック 8 がロードされます。ポインタを介してメモリにアクセス 3 回目の IO が発生 同時にメモリが通過 二分検索が 29 に達してクエリが終了し、合計 3 回の IO が発生します。 インデックスの分類インデックス構成テーブルとは、主キー順にインデックスとして格納されるテーブルで、InnoDB エンジンに適した方式です。 InnoDB は B ツリー インデックス モデルを使用するため、データは B ツリーに保存されます。 各インデックスは InnoDB の B ツリーに対応します。 mysql> create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB; 复制代码 ログイン後にコピー テーブル内のR1~R5の(ID,k)値は(100,1)、(200,2)、 (300,3)、(500,5)、および (600,6)、2 つのツリーの図の例は次のとおりです。図からはわかりにくいですが、リーフ ノードの内容に応じて、インデックス タイプが主キー インデックスと非主キー インデックスに分けられます。 主キー インデックス
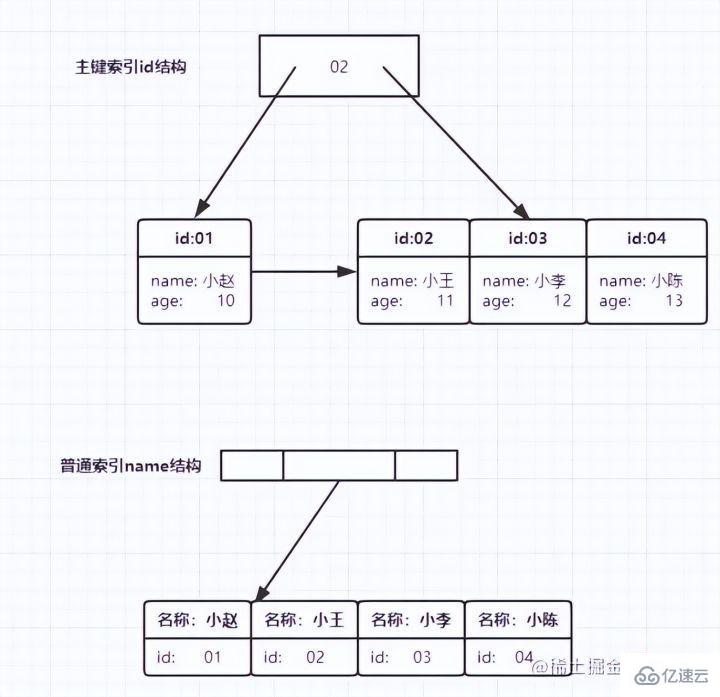
データ行全体が格納されます。 InnoDB では、主キー インデックスはクラスター化インデックス の値です。 InnoDB では、補助インデックスはSecondary Index (セカンダリ インデックス) とも呼ばれます。 以下に示すように:
ステートメントが select * from T where ID=500 (主キー クエリ メソッド) の場合、ID の B ツリーを検索するだけで済みます。
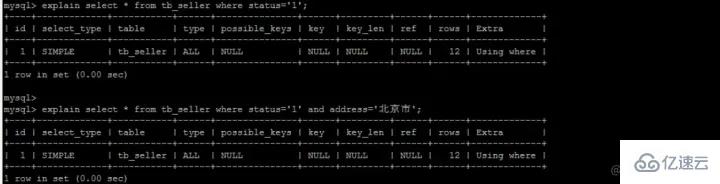
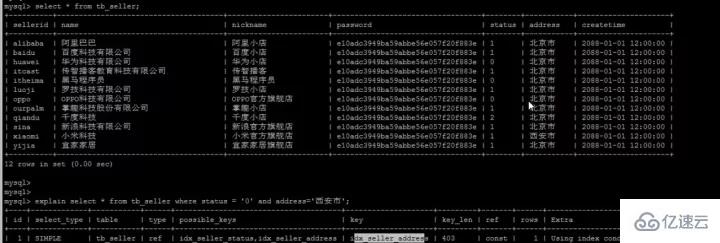
拡張機能 -- インデックス プッシュダウンいわゆるプッシュダウンは、その名前が示すように、実際には テーブルの戻り操作を延期します。MySQL はそれを許可しません。とてももったいないので簡単にテーブルに戻ります。それはどういう意味ですか?次の例を考えてみましょう。 複合インデックス (名前、ステータス、アドレス) を確立しました。これも、次の図のように、このフィールドに従って保存されます。 複合インデックス ツリー (インデックス列とアドレスのみを保存します)主キーはテーブルを返すために使用されます)
以上がMySQLインデックスの構文は何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
関連ラベル:
ソース:yisu.com
このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。
著者別の最新記事
最新の問題
結果セットから最小値のみを表示する方法 (MYSQL)
次のステートメントがあります: selectDATE(recieved_on)asDay,round(count(*)/24)AS'average'frommessagewhere...
から 2024-04-06 21:44:19
0
1
603
MySQL でグループ化してカウントするにはどうすればよいですか?
友人に送信され、削除されていないメッセージの合計数を抽出するクエリを作成しようとしています。これはテーブル構造のスクリーンショットです。 達成したい出力は次のとおりです。 idme...
から 2024-04-06 18:30:17
0
1
353
MySQL は複数のテーブルからデータを取得します
次の列を含む eg_design テーブル、および次の列を含む eg_domains テーブル、および次の列を含む eg_fonts テーブルがあります。 $domain_id に...
から 2024-04-06 18:42:44
0
2
479
関連トピック
詳細>
|



















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



