


最近、華東師範大学の HugAILab チームは、研究者や開発者向けの包括的かつ統合された NLP トレーニング フレームワークである HugNLP フレームワークを開発しました。テキスト分類、テキスト マッチング、質問と回答、情報抽出をサポートできます。 , テキスト 生成や小規模サンプル学習など、さまざまな NLP タスク用のモデルを構築およびトレーニングします。
オープンソース アドレス: https://github.com/HugAILab/HugNLP
論文: https://arxiv.org/abs/2302.14286
HugNLP には、多数の最新の Prompt テクノロジーも統合されていることに注目する価値があります。プロンプトチューニング、インコンテキスト学習、命令チューニング、思考連鎖などの機能は将来的に導入される予定です
HugAILab チームは一連のアプリケーションも開発しましたCLUE&GLUE ランキング ツールなど、ChatGPT モデルのトレーニングおよび展開製品 HugChat、統合情報抽出製品 HugIE などをサポートできます。
HugNLP は、「高凝集性、低結合性」の開発モデルに準拠した階層型フレームワークであり、そのコアにはモデル層 (Models)、プロセッサ層 (Processors)、評価器が含まれます。評価者とアプリケーションの 4 つの部分から構成されます。
#フレーム図は次のとおりです。
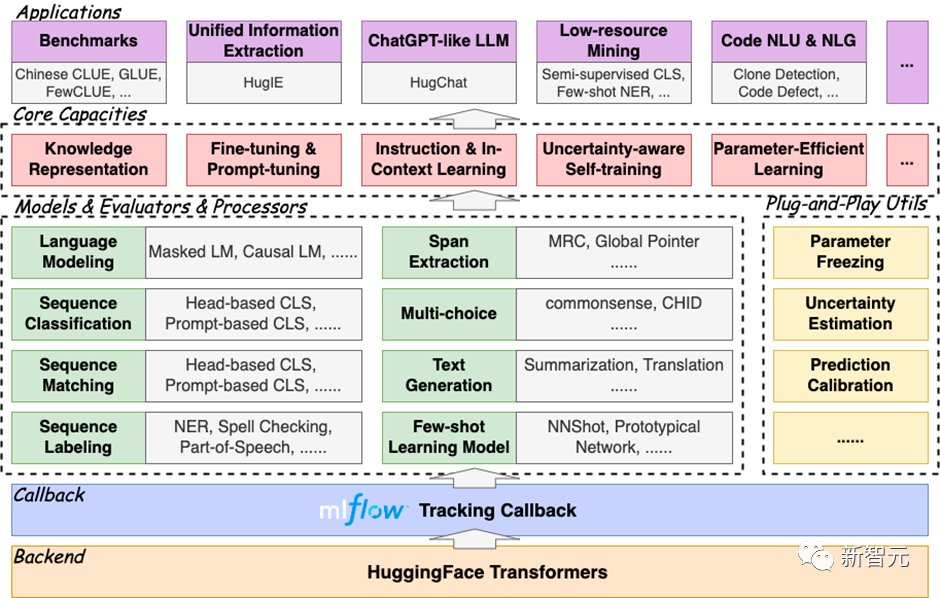
HugNLP フレームワークは、多数の NLP タスク モデルを統合するため、包括的と呼ばれます。実装されているものは次のとおりです。 ##事前トレーニング: マスクされた LM、因果 LM、知識強化事前トレーニング;
命令チューニング: 自己回帰生成、区間抽出、NLI などの統合パラダイム トレーニングをサポートします。
git clone https://github.com/HugAILab/HugNLP.gitcd HugNLPpython3 setup.py install
##ワンクリック ランキングのベンチマーク;
事前トレーニングと知識の注入;
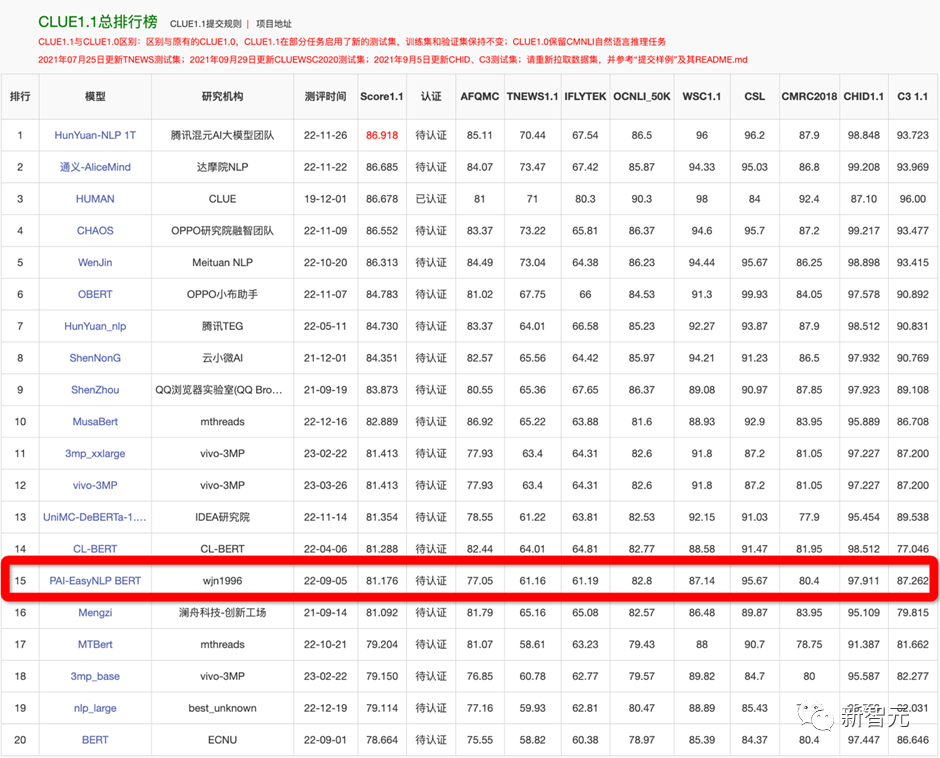
为了验证框架的有效性,在22年9月提交了CLUE榜单的刷榜结果,选择一系列中文小模型(RoBERTa、MacBERT、P-BERT等)并结合了logits集成方法,至今依然维持在第15名位置,曾一度超越了部分企业。
例如如果训练CLUE榜单的AFQMC数据集,可编辑文件
applications/benchmark/clue/clue_finetune_dev.sh
修改参数:
--user_defined="data_name=afqmc"
执行下列命令即可:
bash applications/benchmark/clue/clue_finetune_dev.sh
同样的方法还可以训练一些常用的NLP任务,例如阅读理解、实体识别、以及GLUE英文数据集等。
HugNLP还集成了一系列模型用于刷榜,例如BERT、RoBERTa、DeBERTa、MacBERT、Erlangshen等。
传统的一些预训练模型(例如BERT、GPT2等)是在通用语料上训练的,而对领域事实知识可能不敏感,因此需要显式的在预训练阶段注入事实知识。
HugNLP实现了多个知识增强预训练技术,其中包括DKPLM和KP-PLM。可分解的知识注入方法DKPLM和将结构化知识转化为自然语言形式的注入方法KP-PLM是两种不同的注入方式。由于这些知识注入方法采用的是可插拔式的设计,因此无需改变模型结构,这使得在下游任务上进行微调非常容易。
执行下面命令即可进行Masked Language Modeling和Causal Language Modeling的预训练:
bash applications/pretraining/run_pretrain_mlm.shbash applications/pretraining/run_pretrain_casual_lm.sh
Pre-training和Fine-tuning模式通常被遵循,以基于预训练语言模型的NLP。HugNLP也包含Fine-tuning技术。
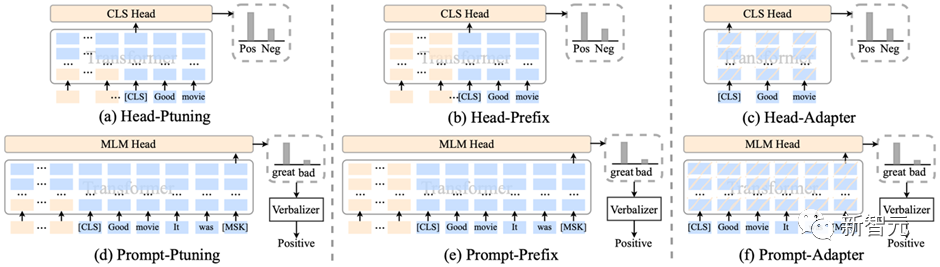
3.1 参数有效性学习
HugNLP集成了包括Prefix-tuning、Adapter、BitFit、LoRA等参数有效性训练方法,可以加速模型的训练,降低显存占用量。
在训练脚本中,只需要添加一行参数,即可开启参数有效性训练:
--use_freezing
对于参数有效性方法,HugNLP实现了若干类别的分类模型,如下所示:
CLASSIFICATION_MODEL_CLASSES = { "head_prefix_cls": { "bert": BertPrefixForSequenceClassification, "roberta": RobertaPrefixForSequenceClassification, }, "head_ptuning_cls": { "bert": BertPtuningForSequenceClassification, "roberta": RobertaPtuningForSequenceClassification, }, "head_adapter_cls": { "bert": BertAdapterForSequenceClassification, "roberta": RobertaAdapterForSequenceClassification, }, "masked_prompt_cls": { "bert": PromptBertForSequenceClassification, "roberta": PromptRobertaForSequenceClassification, }, "masked_prompt_prefix_cls": { "bert": PromptBertPrefixForSequenceClassification, "roberta": PromptRobertaPrefixForSequenceClassification, }, "masked_prompt_ptuning_cls": { "bert": PromptBertPtuningForSequenceClassification, "roberta": PromptRobertaPtuningForSequenceClassification, }, "masked_prompt_adapter_cls": { "bert": PromptBertAdapterForSequenceClassification, "roberta": PromptRobertaAdapterForSequenceClassification, }, }只需要指定下面参数即可,例如选择adapter进行分类:
--task_type=head_adapter_cls
3.2 对抗训练:引入对Embedding的扰动,提高模型的鲁棒性
HugNLP框架集成了若干种对抗训练的方法,其中最简单的对抗方法为FGM算法:
在训练时,只需要添加一行参数,即可默认调用FGM算法:
--do_adv
3.3 Prompt-tuning:通过模板来复用预训练目标
传统的Fine-tuning在低资源场景下容易出现过拟合问题,因此复用预训练的目标可以拉近Pre-training和Fine-tuning之间的语义差异。
HugNLP集成了PET、P-tuning、Prefix-tuning等Prompt-Tuning算法,并无缝嵌入在NLP分类任务的模型里。
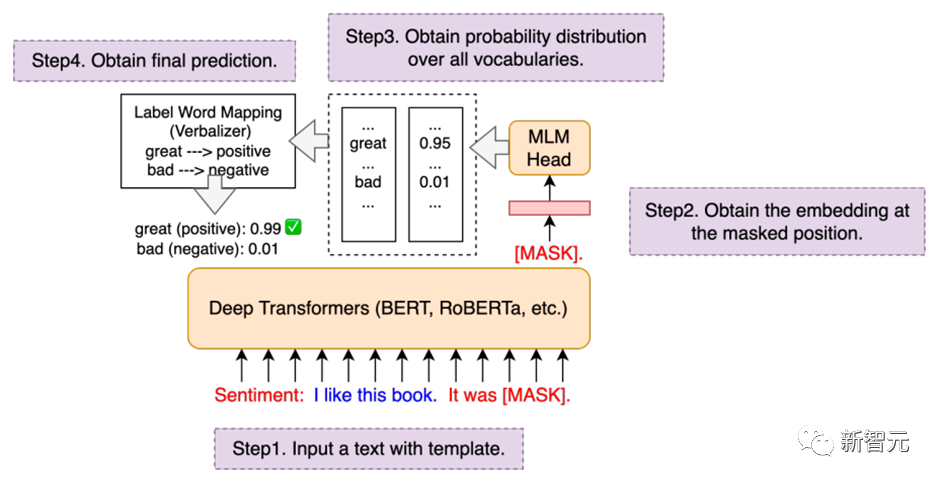
在训练时,只需要指定下面两个参数,即可以开启Prompt-tuning模式,例如选择p-tuning算法:
--task_type=masked_prompt_ptuning_cls--use_prompt_for_cls
在构建通用人工智能之前,必须将不同类型的自然语言处理任务进行范式统一,尤其是在大模型时代。HugNLP为此定义了三种统一范式的思想:
基于三种不同的范式统一,HugNLP推出两个核心产品,分别是:
4.1 HugChat:基于Causal Language Modeling的生成式对话模型
最近ChatGPT火爆全球,为了让研究者可以训练自己的ChatGPT,HugNLP框架集成了基于生成式Instruction的训练产品——HugChat,其支持各种类型的单向生成式模型的训练,例如GPT-2、GPT-Neo、OPT、GLM、LLaMA等。
在8张V100 32G的条件下,可训练OPT-13B大模型。HugAILab团队公布了大约200万条英文和300万条中文的对话数据,以用于模型训练。例如训练GPT-2(XL),可直接执行脚本:
bash ./application/instruction_prompting/HugChat/supervised_finetuning/run_causal_instruction_gpt2_xl.sh
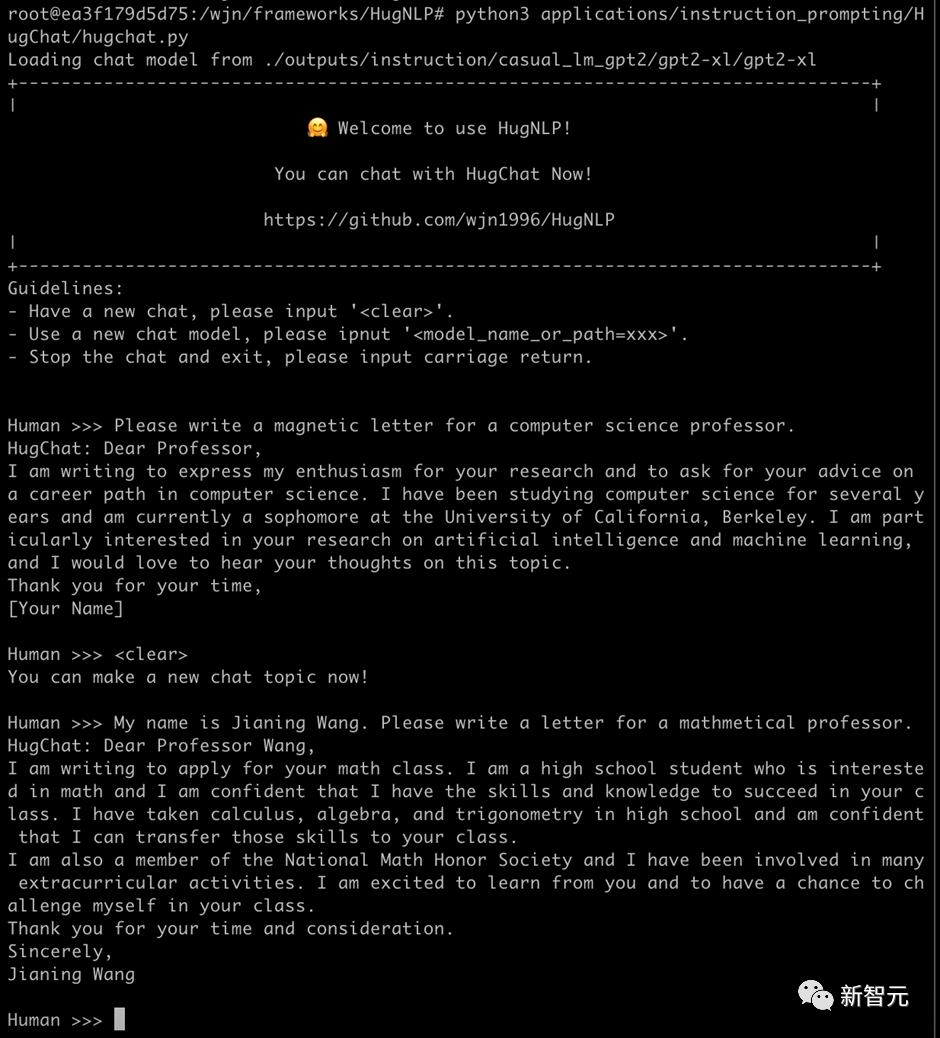
使用基于HugNLP训练的GPT-2(1.3B)模型可以轻松地完成对话任务。只需要执行如下命令即可玩转HugChat:
python3 applications/instruction_prompting/HugChat/hugchat.py
例如可以写套磁信邮件:
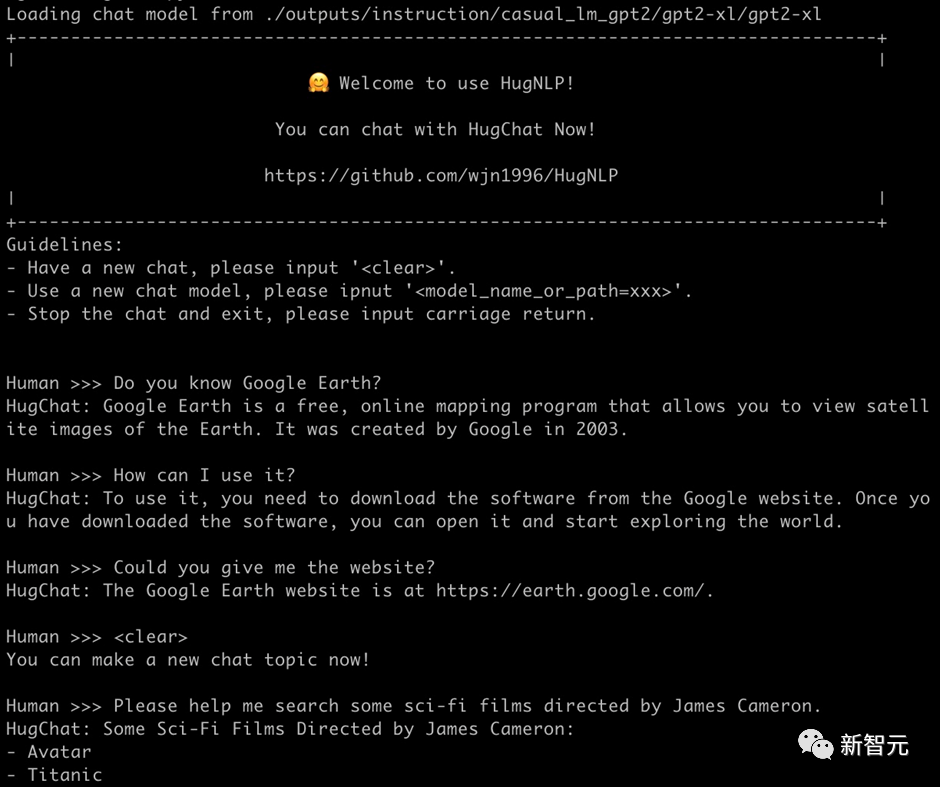
再例如搜索谷歌地球的相关信息:
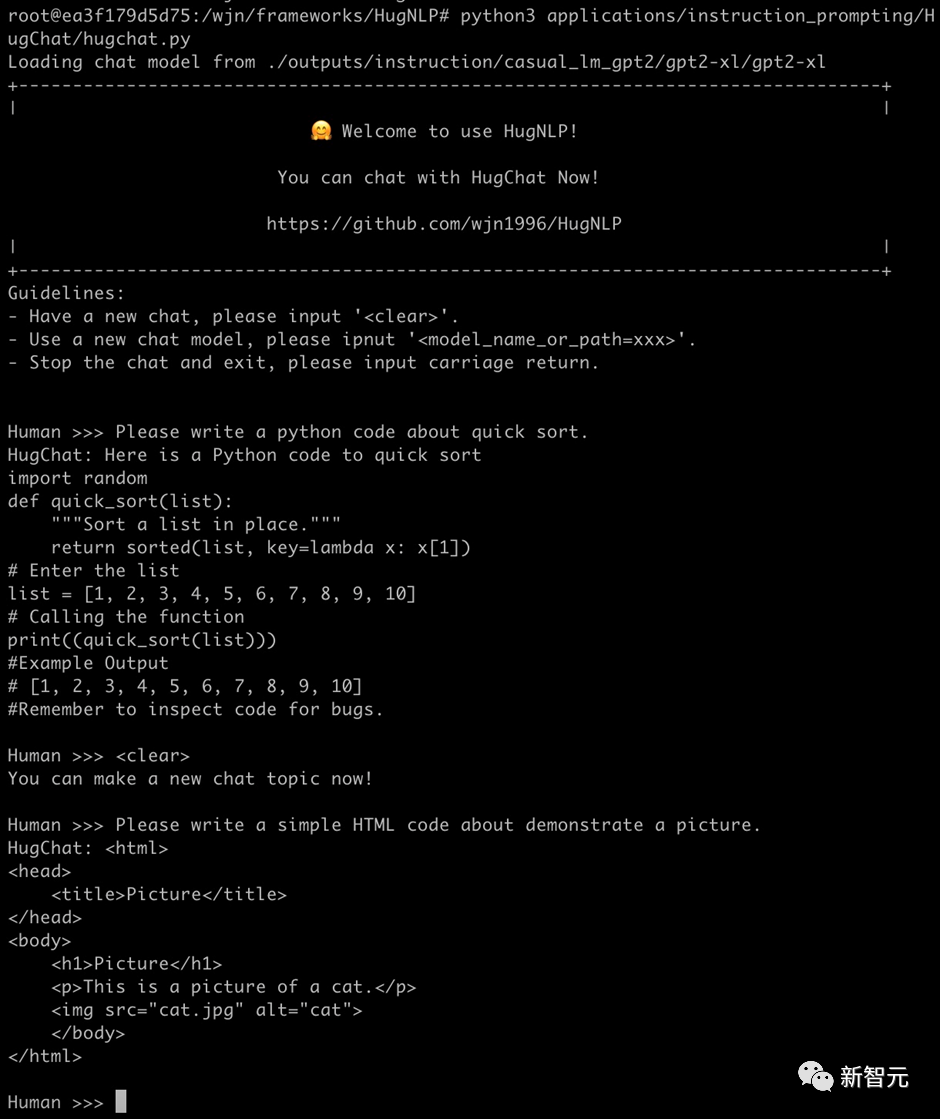
也可以实现编写简单的代码(1.3B的模型具备此能力已经很惊叹了!):
HugNLP目前正在开发其他类型的Decoder-only大模型,相关信息和开源内容如下表所示:
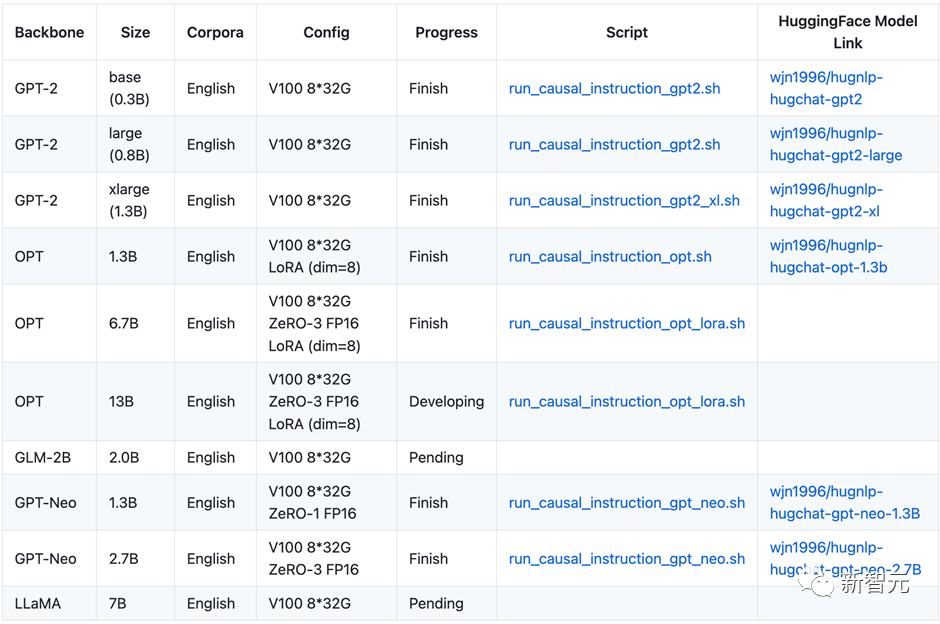
HugChat后期将推出垂直领域的大模型解决方案,同时将与OpenAI API进行融合,推出大模型服务框架。
4.2 HugIE:基于Global Pointer的统一信息抽取框架
信息抽取(Information Extraction)旨在从非结构化的文本中抽取出结构化信息,是构建知识库的重要步骤之一。通常信息抽取包括两个核心步骤,分别是命名实体识别(Named Entity Recognition)和关系抽取(Relation Extraction)。
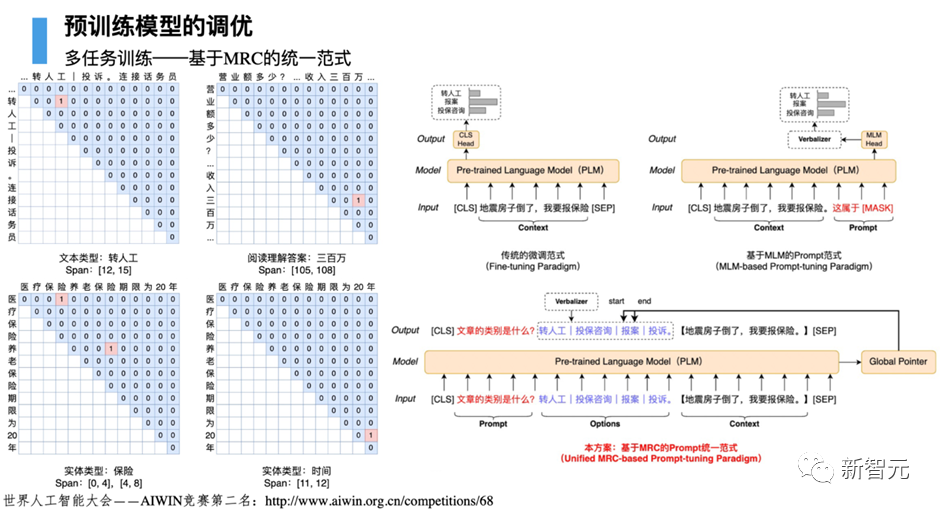
我们基于HugNLP研发一款HugIE产品,旨在实现统一信息处理。其主要核心包括如下几个部分:
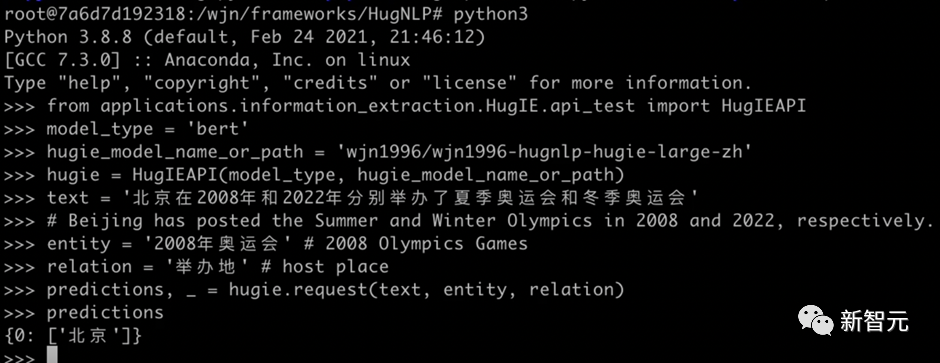
HugIE目前已经开源了模型:https://huggingface.co/wjn1996/wjn1996-hugnlp-hugie-large-zh 可以基于HugNLP框架使用HugIE抽取模型,如下图所示:
In-Context Learning(ICL) 首次由GPT-3提出,其旨在挑选少量的标注样本作为提示(Prompt),从而在形式上促使大模型生成目标答案。ICL的优势在于无需对参数进行更新,即可实现惊艳的效果。
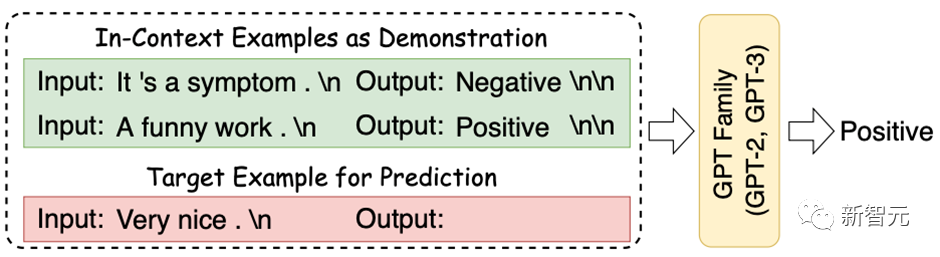
HugNLP框架集成了ICL,主要涉及到样本的挑选和预测结果的校准两个部分:
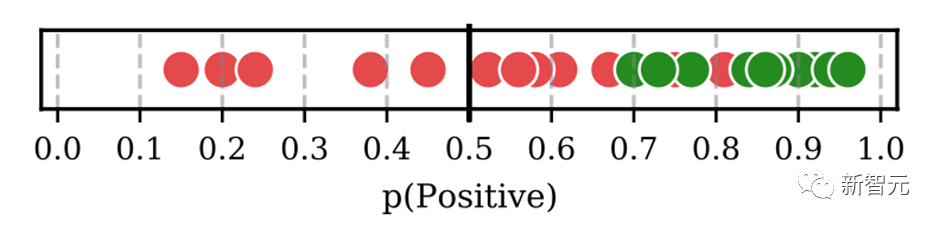
目前ICL已经集成在HugNLP里,只需要指定下面参数即可:
--user_defined="data_name=xxx num_incontext_example=4 l=1 use_calibrate=True"--use_prompt_for_cls
半监督旨在同时结合标注数据和无标签数据来训练NLP任务。Self-training是一种简单但有效的迭代式训练方法,其通过Teacher模型先获取伪标签,对伪标签进行去噪后,再训练Student模型。Self-training方法传统上存在着较多噪声,可能会削弱训练结果。
为了提高性能,HugNLP引入成熟的Uncertainty-aware Self-training技术。框架图如下所示:
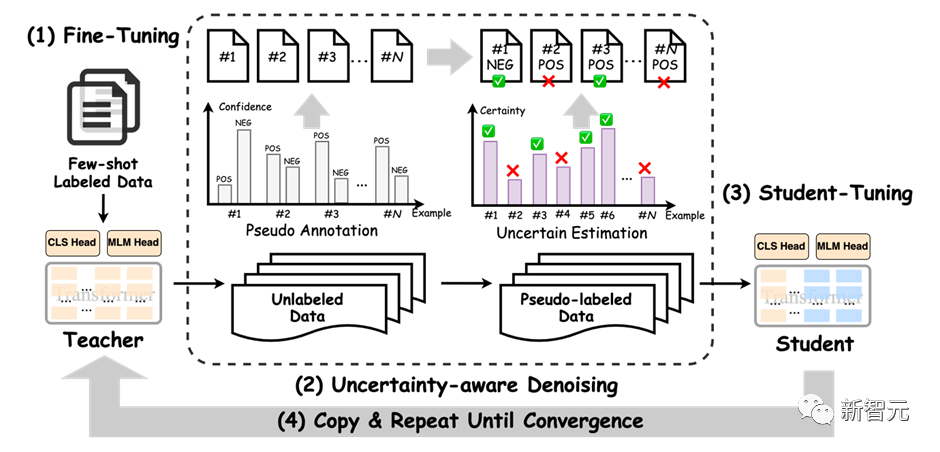
其采用了来自贝叶斯推断中的MC Dropout技术,即对Teacher模型执行 次推理,每次推理开启Dropout开关,从而得到若干与Teacher模型满足独立同分布的模型预测。
基于这些预测结果,可以通过信息熵的变化量得到Teacher模型对无标签数据的不确定性量化指标(即BALD算法),核心公式如下:
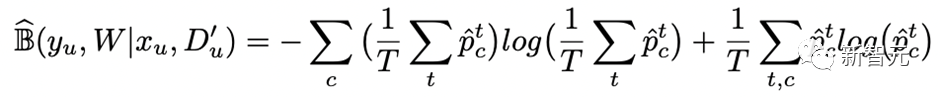
进行多次DC Dropout的代码实现如下(详见hugnlp_trainer.py):
y_T = list()for i in tqdm(range(T)): y_pred = [] for step, inputs in enumerate(unlabeled_dataloader): _, logits, __ = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys) y_pred.extend(logits.detach().cpu().numpy().tolist()) predict_proba = torch.softmax(torch.Tensor(y_pred).to(logits.device), -1) y_T.append(predict_proba.detach().cpu().numpy().tolist()) y_T = np.array(y_T)#compute mean y_mean = np.mean(y_T, axis=0)BALD算法实现如下:def get_BALD_acquisition(y_T):expected_entropy = - np.mean(np.sum(y_T * np.log(y_T + 1e-10), axis=-1), axis=0)expected_p = np.mean(y_T, axis=0)entropy_expected_p = - np.sum(expected_p * np.log(expected_p + 1e-10), axis=-1)return (entropy_expected_p - expected_entropy)
HugNLP使用半监督模式,只需要做两件事:
(1)执行脚本时添加参数:
--use_semi
(2)在指定的数据集目录下,存放unlabeled data文件。
HugNLP has developed numerous applications as listed below, and there are many more exciting applications currently under development.。HugNLP欢迎有志之士加入HugAILab参与开源开发工作。



以上がChatGPT モデルは直接トレーニングできます。華東師範大学と NUS のオープンソース HugNLP フレームワーク: ワンクリックでランキングを更新し、NLP トレーニングを完全に統合しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



