


聖書にバベルの塔の話がありますが、人類は天国につながることを願って一致団結して高い塔を建てる計画を立てましたが、神が人間の言語を混乱させて計画は失敗したと言われています。今日、AI テクノロジーは人間の言語間の障壁を取り除き、人類が文明的なバベルの塔を構築するのに役立つと期待されています。
最近、Meta による研究がこの側面に向けて重要な一歩を踏み出しました。彼らは新しく提案された手法を大規模多言語音声 (MMS) と呼び、「聖書」に基づいて使用されました。
Meta は、多くの希少言語におけるデータ不足の問題をどのように解決しますか?彼らが使用した方法は興味深いもので、宗教コーパスを使用しています。なぜなら、聖書のようなコーパスには最も「整合性のある」音声データがあるからです。このデータセットは宗教的な内容に偏っており、主に男性の声を特徴としていますが、この論文は、このモデルが女性の声を使用した場合でも他の領域でも同様に良好に機能することを示しています。これはベースモデルの創発的な動作であり、本当に驚くべきことです。さらに驚くべきことは、Meta が新しく開発されたすべてのモデル (音声認識、TTS、言語認識) を無料でリリースしたことです。
数千の単語を認識できる音声モデルを作成するために、最初の課題は、さまざまな言語の音声データを収集することです。現在利用可能な最大の音声データセットはたったの 1 つだけであるためです。 100言語まで。この問題を克服するために、メタ研究者は、多くの異なる言語に翻訳されている聖書などの宗教文書を使用し、それらの翻訳は広範囲に研究されてきました。これらの翻訳には、さまざまな言語で読み上げた音声録音が含まれており、これらの音声も一般公開されています。研究者らは、これらの音声を使用して、1,100 の言語で新約聖書を読む人々の音声を含むデータセットを作成しました。音声の長さは 1 言語あたり平均 32 時間でした。
その後、他の多くのキリスト教の朗読の注釈なしの録音が含まれ、利用可能な言語の数が 4,000 以上に増加しました。このデータセットのフィールドは単一で、ほとんどが男性の声で構成されていますが、分析結果は、Meta が新たに開発したモデルが女性の声でも同様に良好に機能し、このモデルがより宗教的な言語を生成することに特に偏っていないことを示しています。研究者らはブログで、これは主に彼らが使用したコネクショニスト時間分類法によるものであり、この手法は大規模言語モデル (LLM) やシーケンスツーシーケンス音声認識モデルよりもはるかに優れていると述べています。
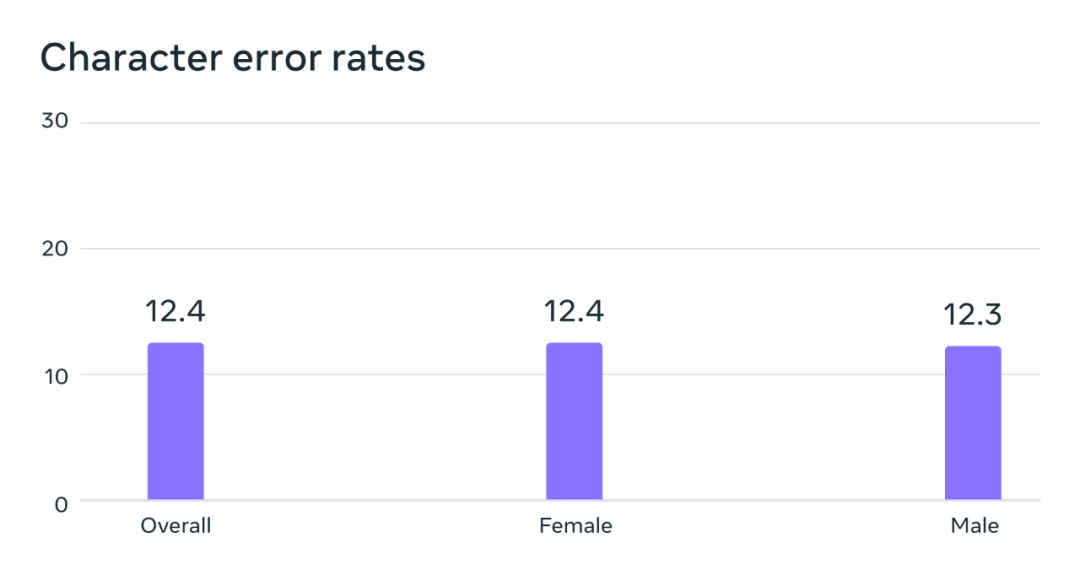
# 潜在的なジェンダーバイアス状況の分析。 FLEURS ベンチマークでは、多言語音声 (MMS) データセットでトレーニングされたこの自動音声認識モデルは、男性の声と女性の声で同様のエラー率を示します。
機械学習アルゴリズムで使用できるようにデータの品質を向上させるために、いくつかの前処理方法も採用されました。まず、100 を超える言語の既存データで位置合わせモデルをトレーニングし、それを 20 分を超える非常に長い録音を処理できる効率的な強制位置合わせアルゴリズムと組み合わせました。その後、複数ラウンドの位置合わせプロセスを経た後、相互検証フィルタリングの最終ステップが実行され、モデルの精度に基づいて位置ずれの可能性があるデータが除去されます。他の研究者が新しい音声データ セットを作成しやすくするために、Meta はアライメント アルゴリズムを PyTorch に追加し、アライメント モデルをリリースしました。
一般的に使用可能な教師あり音声認識モデルをトレーニングするには、言語ごとに 32 時間のデータだけでは十分ではありません。したがって、彼らのモデルは、自己教師あり音声表現学習に関する以前の研究である wav2vec 2.0 に基づいて開発されており、学習に必要なラベル付きデータの量を大幅に削減できます。具体的には、研究者らは、これまでの研究の 5 倍以上の言語である 1,400 以上の言語の約 500,000 時間の音声データを使用して自己教師ありモデルをトレーニングしました。次に、特定の音声タスク (多言語音声認識や言語認識など) に基づいて、研究者は結果のモデルを微調整します。
研究者らは、新しく開発したモデルをいくつかの既存のベンチマークで評価しました。
多言語音声認識モデルのトレーニングでは、10 億のパラメーターを持つ wav2vec 2.0 モデルが使用され、トレーニング データ セットには 1,100 以上の言語が含まれています。言語の数が増えるとモデルのパフォーマンスは確かに低下しますが、その低下は非常にわずかです。言語の数が 61 から 1107 に増加しても、文字エラー率は 0.4% しか増加しませんが、言語のカバレッジはさらに増加します。 18倍以上。
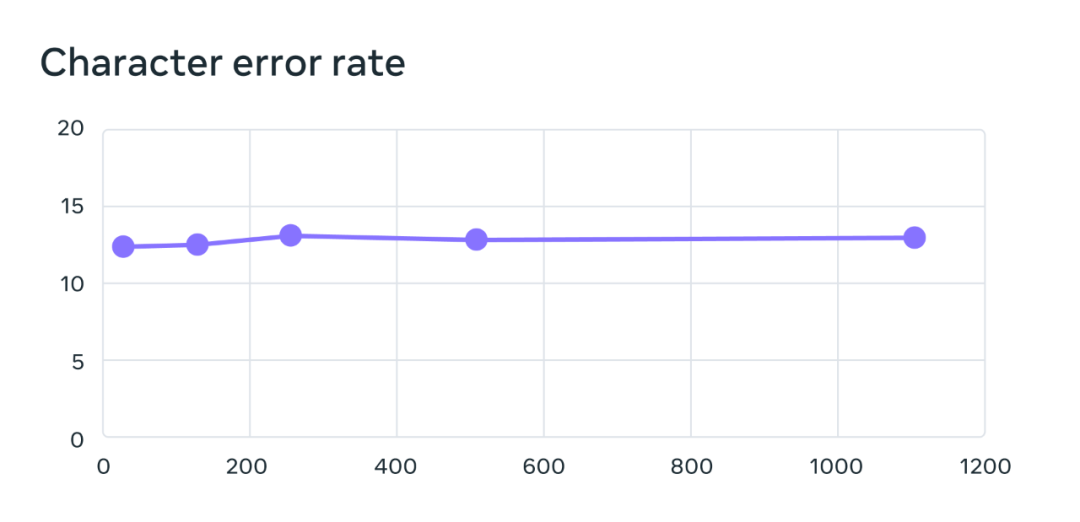
FLEURS 61言語のベンチマークテストでは、言語数が増えるにつれて文字誤り率が変化し、エラー率が高いほど、モデルは悪くなります。
研究者らは、OpenAI の Whisper モデルを比較したところ、彼らのモデルの単語誤り率は Whisper の半分しかないのに対し、新しいモデルは 11 倍多くの言語をサポートしていることを発見しました。この結果は、新しい方法の優れた機能を示しています。
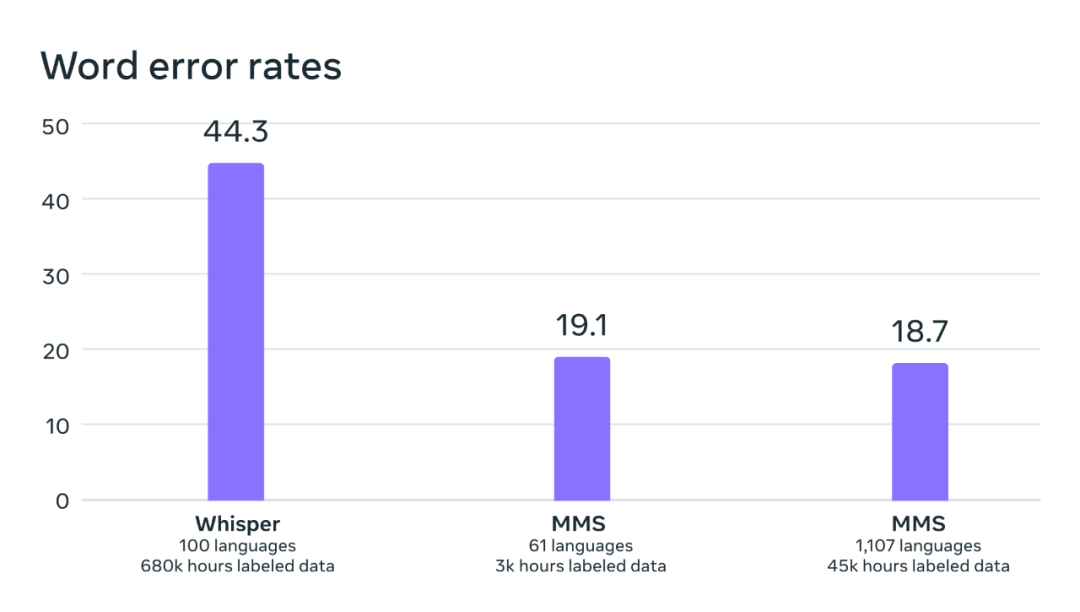
直接比較できる 54 の FLEURS 言語のベンチマークにおける OpenAI Whisper と MMS の単語エラー率の比較。
次に、メタ研究者は、以前の既存のデータ セット (FLEURS や CommonVoice など) と新しいデータ セットを使用して、言語識別 (LID) モデルもトレーニングし、FLEURS LID タスクを評価しました。 。結果は、新しいモデルが優れたパフォーマンスを発揮するだけでなく、40 倍以上の言語をサポートしていることを示しています。
前回の調査でも、VoxLingua-107 ベンチマークでは 100 以上の言語のみがサポートされていましたが、MMS は 4000 以上の言語をサポートしています。
さらに、Meta は 1,100 の言語をサポートするテキスト読み上げシステムを構築しました。現在のテキスト読み上げモデルのトレーニング データは通常、単一の話者からの音声コーパスです。 MMS データの制限の 1 つは、多くの言語には話者の数が少なく、話者が 1 人の場合も多いことです。しかし、これはテキスト読み上げシステムを構築する際に利点となるため、Meta は 1,100 以上の言語をサポートする TTS システムを構築しました。研究者らは、これらのシステムによって生成される音声の品質は実際に非常に優れており、以下にいくつかの例を示します。
ヨルバ語、イロコ語、マイティリ語の MMS テキスト読み上げモデルのデモ。
にもかかわらず、研究者らは AI テクノロジーはまだ完璧ではなく、MMS についても同様であると述べています。たとえば、MMS は、音声をテキストに変換する際に、選択された単語やフレーズを誤って転記する可能性があります。これにより、出力に不快な表現や不正確な表現が含まれる可能性があります。研究者らは、責任を持って開発するためにAIコミュニティと協力することの重要性を強調した。
世界中の多くの言語が絶滅の危機に瀕しており、現在の音声認識および音声生成テクノロジーの限界この傾向はさらに加速するだけです。研究者はブログの中で次のように想像しました。優れたテクノロジーがあれば、情報を入手したりテクノロジーを使用したりするために自分の好きな言語を使用できるため、テクノロジーが人々に自分の言語を保持するよう促すことができるのかもしれません。
彼らは、MMS プロジェクトがこの方向への重要な一歩であると信じています。また、プロジェクトは今後も開発を続け、将来的にはさらに多くの言語をサポートし、方言やアクセントの問題も解決するだろうとも述べた。
以上がMeta は聖書を使用して超多言語モデルをトレーニングします。1107 言語を認識し、4017 言語を識別しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



