


人工知能技術の急速な発展に伴い、ChatGPT、New Bing、GPT-4などの新製品や新技術が次々にリリースされており、基本的な大型モデルは多くのアプリケーションでますます重要な役割を担うことになります。
現在の大規模な言語モデルのほとんどは自己回帰モデルです。自己回帰は、モデルが出力時に単語ごとの出力を使用することが多いことを意味します。つまり、各単語を出力するときに、モデルは以前に出力した単語を入力として使用する必要があります。通常、この自己回帰モードでは、出力中の並列アクセラレータの完全な使用が制限されます。
多くのアプリケーション シナリオでは、大規模なモデルの出力は、次の 3 つの一般的なシナリオのように、一部の参考テキストとよく似ています。
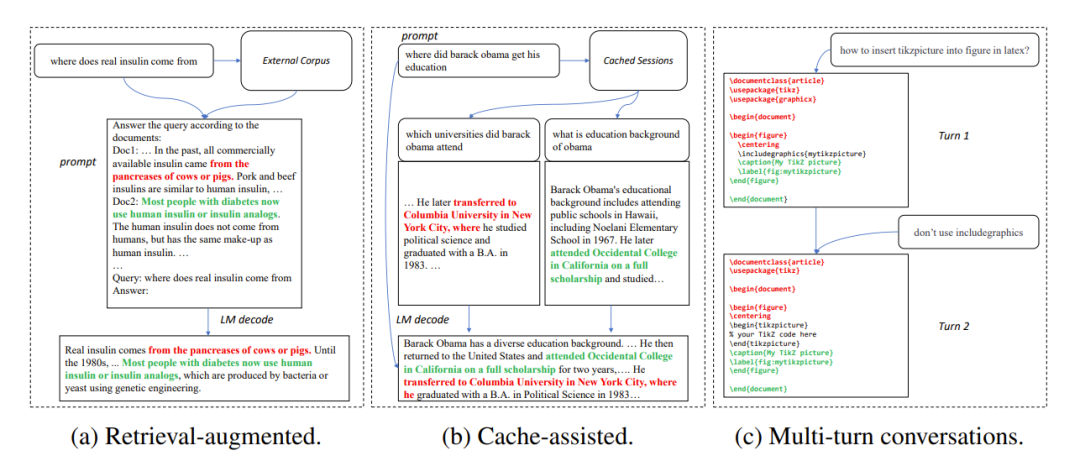
1. 検索拡張生成New Bing などの検索アプリケーションがユーザー入力に応答すると、まずユーザー入力に関連する情報を返します。次に、関連情報を使用して、言語モデルを使用して取得した情報を要約し、ユーザー入力に応答します。このシナリオでは、モデルの出力には、検索結果からの多数のテキストの断片が含まれることがよくあります。
#2. キャッシュされた生成を使用する
#言語モデルの大規模なデプロイメントのプロセスでは、履歴入力が必要になります。そして出力はキャッシュされます。新しい入力を処理するとき、取得アプリケーションはキャッシュ内で同様の入力を探します。したがって、モデルの出力は、キャッシュ内の対応する出力とよく似ています。
3. マルチターン会話での生成
ChatGPT などのアプリケーションを使用する場合、ユーザーはモデル ベースを使用することがよくあります。 on 出力が繰り返し変更を要求しました。この複数ターンの対話シナリオでは、多くの場合、モデルの複数の出力には少量の変更しかなく、高度な繰り返しが含まれます。
上記の観察に基づいて、研究者らは、自己回帰のボトルネックを突破するための焦点として参照テキストとモデル出力の再現性を使用し、並列アクセラレータの使用率を向上させ、高速化を目指しました。大規模言語モデルの推論と、出力と参照テキストの繰り返しを使用して、複数の単語を 1 ステップで出力する方法 LLM Accelerator が提案されています。
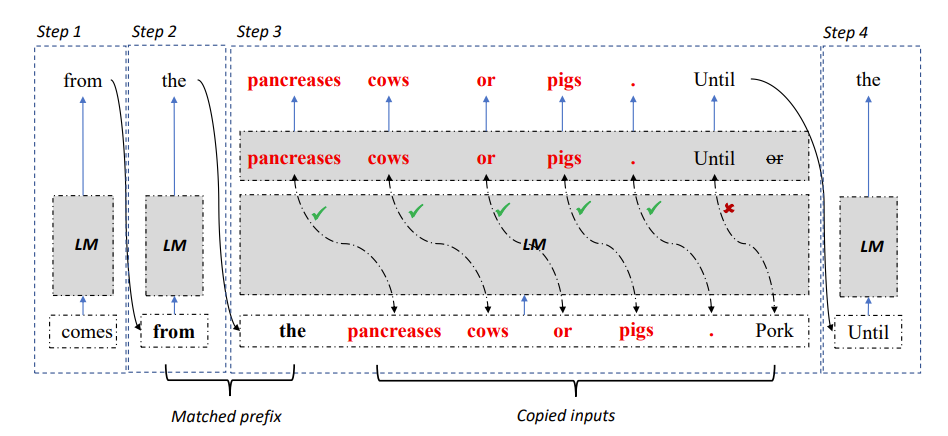 #図 2: LLM アクセラレータのデコード アルゴリズム
#図 2: LLM アクセラレータのデコード アルゴリズム
具体的には、各デコード ステップで、モデルが最初に既存の出力結果と参照テキストを一致させます。参照テキストが既存の出力と一致することが判明した場合、モデルは既存の参照テキストを延期して出力を続行する可能性があります。 。
したがって、研究者らは参照テキストの後続の単語をモデルへの入力として追加し、1 回のデコード ステップで複数の単語を出力できるようにしました。
入力と出力の正確性を保証するために、研究者はモデルによって出力された単語と参照文書から入力された単語をさらに比較しました。この 2 つが一致しない場合、間違った入力結果と出力結果は破棄されます。
上記の方法では、デコード結果がベースライン方法と完全に一致していることを保証でき、各デコードステップでの出力ワード数を増やすことができるため、大規模モデル推論のロスレス加速を実現できます。 。
LLM アクセラレータは追加の補助モデルを必要とせず、使いやすく、さまざまなアプリケーション シナリオに簡単に導入できます。
論文リンク: https://arxiv.org/pdf/2304.04487.pdf
プロジェクトリンク: https://github.com/microsoft/LMOps
LLM Accelerator を使用する場合、調整する必要があるハイパーパラメーターが 2 つあります。
1 つ目は、一致メカニズムをトリガーするために必要な出力と参照テキストの間で一致する単語の数です。一致する単語の数が長いほど精度が高く、単語がコピーされたことをより確実に確認できます。参照テキストからの正確な出力が得られ、不正確さが減少します。必要なトリガーと計算により、一致が短くなり、デコード手順が減り、潜在的に高速化が可能になります。
2 番目は、毎回コピーされる単語の数です。コピーされる単語が多いほど、高速化の可能性は大きくなりますが、より多くの誤った出力が破棄される可能性があり、コンピューティング リソースが無駄になります。 。研究者らは実験を通じて、より積極的な戦略(単一の単語トリガーに一致し、一度に 15 ~ 20 単語をコピーする)により、より優れた加速率を達成できることが多いことを発見しました。
LLM アクセラレータの有効性を検証するために、研究者らは検索強化とキャッシュ支援生成に関する実験を実施し、MS-MARCO 段落検索データセットを使用して実験サンプルを構築しました。
検索強化実験では、研究者らは検索モデルを使用して各クエリに対して最も関連性の高いドキュメント 10 件を返し、それらをモデル入力としてクエリに接続しました。文書は参考テキストとして使用されました。
キャッシュ アシスト生成実験では、各クエリで 4 つの同様のクエリが生成され、モデルを使用して対応するクエリが参照テキストとして出力されます。
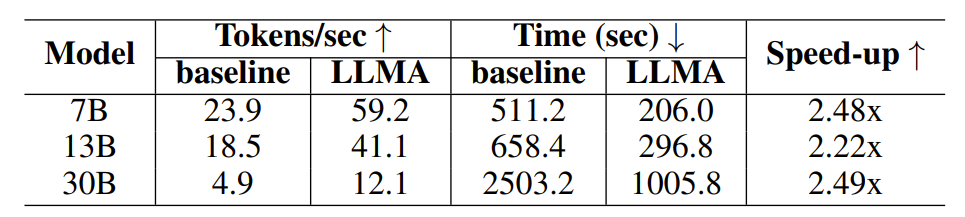
#表 1: 検索拡張生成シナリオでの時間の比較
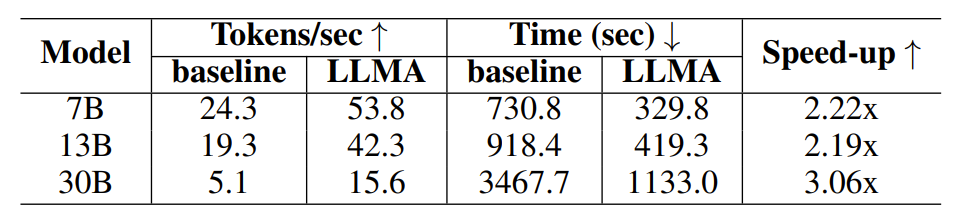
#表 2: キャッシュを使用した生成シナリオでの時間の比較
#研究者らは、高品質の出力を得るために、OpenAI インターフェイスを通じて取得した Davinci-003 モデルの出力をターゲット出力として使用しました。必要な入力、出力、および参照テキストを取得した後、研究者らはオープンソースの LLaMA 言語モデルで実験を実施しました。LLaMA モデルの出力は Davinci-003 の出力と一致しないため、研究者らは目標指向のデコード手法を使用して、理想的な出力 (Davinci-003) での高速化率をテストしました。モデルの結果)。
研究者らはアルゴリズム 2 を使用して、貪欲なデコード中にターゲット出力を生成するために必要なデコード ステップを取得し、取得したデコード ステップに従って LLaMA モデルにデコードを強制しました。

7B および 13B パラメータのモデルの場合、研究者は 1 台の 32G NVIDIA V100 GPU で実験を実施し、30B パラメータのモデルの場合は 4 台の同一の GPU で実験を実施しました。の上。すべての実験では半精度浮動小数点数が使用され、デコードは貪欲デコードで、バッチ サイズは 1 です。
実験結果は、LLM アクセラレータがさまざまなモデル サイズ (7B、13B、30B) およびさまざまなアプリケーション シナリオ (検索強化、キャッシュ支援) で 2 ~ 3 倍のパフォーマンスを達成したことを示しています。 。
さらなる実験分析により、LLM Accelertator が必要なデコード ステップを大幅に削減できること、および加速比がデコード ステップの削減比と正の相関があることがわかりました。
デコード ステップが少ないということは、一方では各デコード ステップでより多くの出力ワードが生成されることを意味し、GPU コンピューティングの計算効率を向上させることができますが、他方では、マルチカードの並列処理 30B モデルでは、マルチカードの同期が少なくなり、速度がより速く向上します。
アブレーション実験では、開発セット上の LLM Accelertator のハイパーパラメータを分析した結果、単一の単語が一致したとき (つまり、コピー メカニズムがトリガーされたとき)、15ワードを使用する場合、最大の高速化率に達します (図 4 を参照)。
図 5 では、一致する単語の数が 1 であることがわかります。これにより、コピー メカニズムがより多くトリガーされる可能性があり、コピーの長さが増加するにつれて、各デコード ステップで受け入れられる出力単語が増加し、デコードステップが減少し、より高い加速比が得られます。
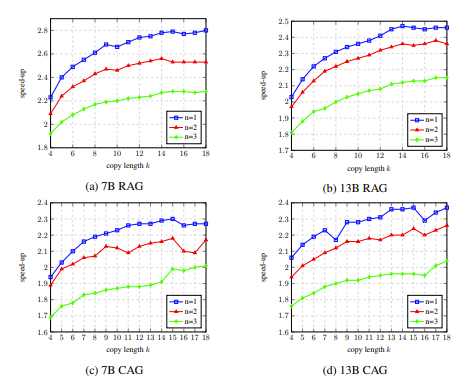
# 図 4: アブレーション実験における、開発における LLM Accelertator のハイパーパラメータの分析結果set
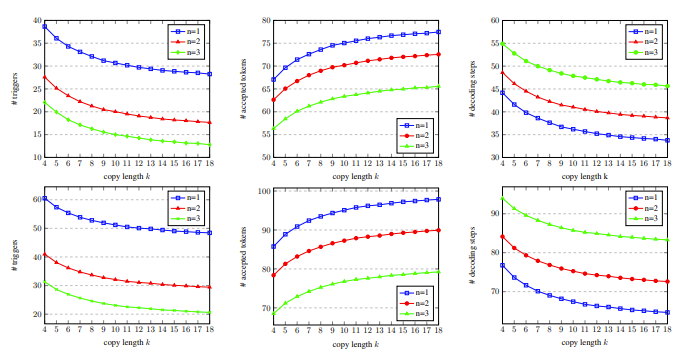
図 5: 異なる数の一致する単語 n と を使用した開発セット上copy Words 数 k のデコード ステップの統計データ
LLM Accelertator は、Microsoft Research Asia Natural Language Computing Group の大規模言語モデルの高速化に関する一連の作業の一部です。研究者は、より詳細な調査のために関連する問題を引き続き調査していきます。
以上がLLM 推論は 3 倍高速になりました。 Microsoft が LLM Accelerator をリリース: 参照テキストを使用してロスレス アクセラレーションを実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



