


最近、あるネチズンが「すべての LLM 開発者が知っておくべき数値」のリストを作成し、これらの数値がなぜ重要なのか、またどのように使用すべきなのかについて説明しました。
彼が Google にいた頃、伝説のエンジニア、ジェフ ディーンがまとめた「エンジニアが知っておくべき数字」という文書がありました。

Jeff Dean: 「すべてのエンジニアが知っておくべき数字」
LLM (Large Language Model) 開発者にとって、大まかな見積もりのために同様の数値セットを用意しておくことも非常に役立ちます。

##40-90%: プロンプトに「concise」を追加します。コスト削減
#出力中に LLM によって使用されるトークンに応じて支払いが行われることを知っておく必要があります。これは、モデルを簡潔にすることで、大幅にコストを節約できることを意味します。
同時に、この概念はより多くの場所に拡張できます。
たとえば、当初は GPT-4 を使用して 10 個の代替案を生成したいと考えていましたが、最初に 5 個を提供するように要求し、その後残りの半分を保持できるようになりました。お金の。
1.3: 単語あたりの平均トークン数
LLM はトークン単位で動作します。そして、トークンは単語または単語の一部です。たとえば、「食べる」は 2 つのトークン「食べる」と「食べる」に分解できます。
一般的に、750 個の英単語から約 1000 個のトークンが生成されます。
英語以外の言語の場合、LLM の埋め込みコーパスにおける共通性に応じて、単語あたりのトークンの数が増加します。

~50: GPT-4 と GPT-3.5 Turbo のコスト比
GPT-3.5-Turbo の使用GPT-4よりも約50倍安い。 「およそ」と言ったのは、GPT-4 ではプロンプトと生成に対して料金が異なるためです。したがって、実際のアプリケーションでは、GPT-3.5-Turbo がニーズを十分に満たすかどうかを確認するのが最善です。
たとえば、要約などのタスクには GPT-3.5-Turbo で十分です。


これは、ベクトル ストレージ システムで何かを検索する方が、LLM で生成を使用するよりもはるかに安価であることを意味します。
具体的には、神経情報検索システムでの検索コストは、GPT-3.5-Turbo に依頼する場合の約 5 分の 1 です。 GPT-4と比較すると、コスト差はなんと250倍!
10: OpenAI Embed とセルフホスト型 Embed のコスト比
注: この数値は負荷に非常に敏感であり、埋め込みバッチ サイズも非常に敏感であるため、それらは近似値として考慮してください。
g4dn.4xlarge (オンデマンド価格: $1.20/時間) を使用すると、HuggingFace を備えた SentenceTransformers (OpenAI の埋め込みに相当) を 1 秒あたり最大 9000 トークンの速度で活用できます。埋め込み。
この速度とノード タイプで基本的な計算を行うと、セルフホスト型の埋め込みが 10 倍安くなる可能性があることがわかります。
6: OpenAI 基本モデルと微調整モデル クエリのコスト比
OpenAI では、ベースモデルの6倍のファインチューニングモデル。
これは、カスタム モデルを微調整するよりも、ベース モデルのプロンプトを調整する方がコスト効率が高いことも意味します。
1: セルフホスティングの基本モデルと微調整されたモデル クエリのコスト比
ホストする場合モデルを自分で作成する場合、微調整モデルのコストは基本モデルのコストとほぼ同じです。パラメータの数は両方のモデルで同じです。
~100 万ドル: 1 兆 4000 億のトークンで 130 億のパラメーター モデルをトレーニングするコスト
#論文アドレス: https://arxiv.org/pdf/2302.13971.pdf
LLaMa の論文LLaMa モデルのトレーニングには 21 日間かかり、2048 個の A100 80GB GPU を使用したと述べました。
Red Pajama トレーニング セットでモデルをトレーニングすると仮定し、すべてが正常に動作し、クラッシュも発生せず、初めて成功すると仮定すると、上記の数値が得られます。
さらに、このプロセスには 2048 GPU 間の調整も含まれます。
ほとんどの企業には、これを行うための条件がありません。
ただし、最も重要なメッセージは、独自の LLM をトレーニングすることは可能ですが、そのプロセスは安価ではないということです。
そして、実行するたびに数日かかります。
それに比べて、事前トレーニングされたモデルを使用すると、はるかにコストが安くなります。
##< 0.001: ゼロからの微調整とトレーニングのコスト率
#この数値は少し一般的ですが、一般的に言えば、微調整にかかるコストは無視できます。たとえば、6B パラメータ モデルを約 7 ドルで微調整できます。
これは、シェイクスピアの作品全体 (約 100 万語) を微調整したい場合、40 ~ 50 ドルしか費やす必要がないことを意味します。
ただし、微調整することと、ゼロからトレーニングすることは別のことです...
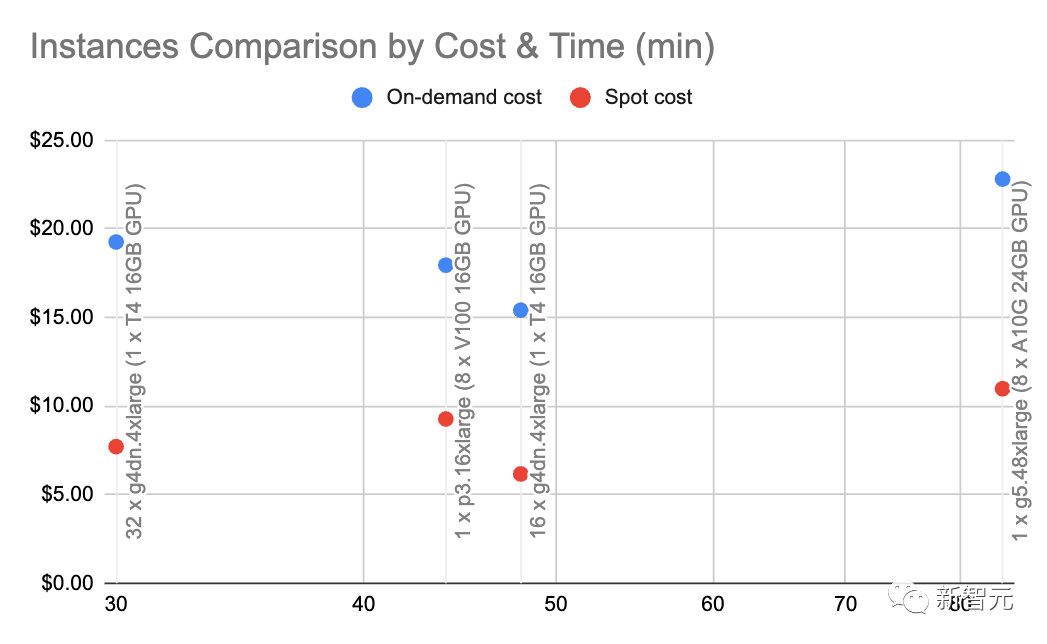
GPU メモリ
Ifモデルを自己ホストしている場合、LLM が GPU メモリを限界まで押し上げるため、GPU メモリを理解することが非常に重要です。次の統計は、特に推論に使用されます。トレーニングや微調整を行う場合は、かなりの量のビデオ メモリが必要です。 V100: 16GB、A10G: 24GB、A100: 40/80GB: GPU メモリ容量 それぞれの違いを理解するGPU が持つビデオ メモリの量は、LLM が持つことができるパラメータの量を制限するため、重要です。 一般的に、A10G は AWS オンデマンドで 1 時間あたり 1.5 ドルから 2 ドルの価格で、24G の GPU メモリを備えているため、A10G を使用するのが好きですが、A100 の価格はそれぞれ約 5 ドルです。時間。 2x パラメータ量: LLM の一般的な GPU メモリ要件 たとえば、70 億のパラメトリックがある場合このモデルには約 14GB の GPU メモリが必要です。 これは、ほとんどの場合、各引数に 16 ビット浮動小数点数 (または 2 バイト) が必要であるためです。 通常、16 ビットを超える精度は必要ありませんが、ほとんどの場合、精度が 8 ビットに達すると解像度が低下し始めます (これが許容される場合もあります)。 。 もちろん、この状況を改善したプロジェクトもいくつかあります。たとえば、llama.cpp は 6GB GPU で 4 ビットに量子化することで 130 億のパラメータ モデルを実行しました (8 ビットも許容されます) が、これは一般的ではありません。 ~1GB: 埋め込みモデルの一般的な GPU メモリ要件 ステートメント (クラスタリング、セマンティクス (検索や分類のタスクでよく行われます)、文コンバーターのような埋め込みモデルが必要です。 OpenAI には独自の商用埋め込みモデルもあります。 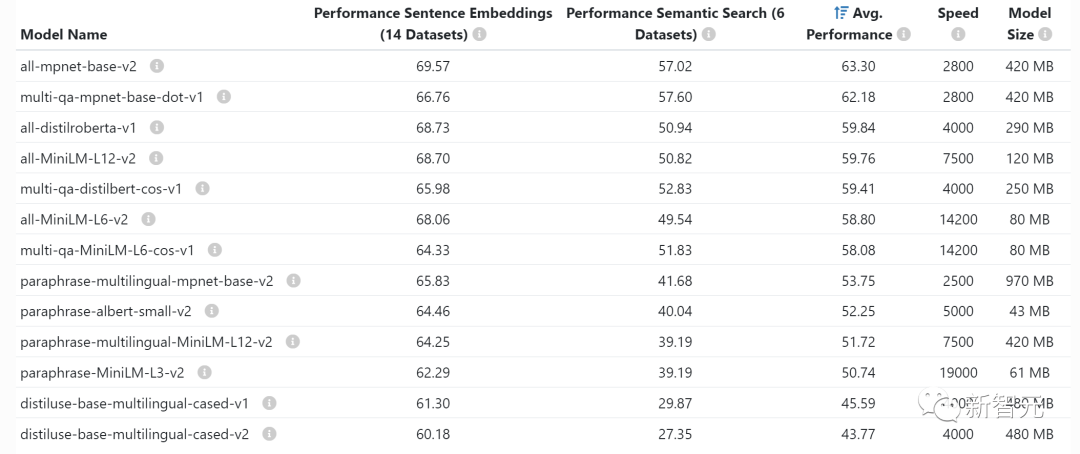
通常、ビデオ メモリの埋め込みが GPU をどれだけ占有するかを心配する必要はありません。小さく、同じ GPU に LLM を組み込むこともできます。
#>10 倍: LLM リクエストをバッチ処理することでスループットを向上
#GPU を介して LLM クエリを実行する際のレイテンシが非常に高い:スループットが 1 秒あたり 0.2 クエリの場合、待ち時間は 5 秒になる可能性があります。
興味深いことに、2 つのタスクを実行した場合、遅延はわずか 5.2 秒になる可能性があります。
これは、25 個のクエリを束ねることができる場合、約 10 秒の待ち時間が必要となり、スループットは 1 秒あたり 2.5 クエリに増加することを意味します。
ただし、ぜひ読み続けてください。
~1 MB: 1 トークンを出力する 130 億パラメータ モデルに必要な GPU メモリ
必要なものビデオ メモリの量は、生成するトークンの最大数に正比例します。
たとえば、最大 512 トークン (約 380 ワード) の出力を生成するには、512MB のビデオ メモリが必要です。
これは大したことではない、と思われるかもしれません。ビデオ メモリは 24 GB ありますが、512 MB とは何ですか?ただし、より大きなバッチを実行する場合は、この数が増加し始めます。
たとえば、16 バッチを実行する場合、ビデオ メモリは直接 8GB に増加します。
以上がJeff Dean の神聖な要約を真似して、元 Google エンジニアが「LLM 開発の秘密」、つまりすべての開発者が知っておくべき数字を共有しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



