


ChatGPT でチャットするだけで、100,000 人の HuggingFace モデルに電話をかけることができます。
これは、Hugging Face がリリースした最新機能、HuggingFace Transformers Agents で、リリース以来大きな注目を集めています:

この機能は、ChatGPT などの大規模モデルに「マルチモーダル」機能を装備するのと同等です -
テキストに限定されず、画像、音声、ドキュメントなどのあらゆるマルチモーダル タスクを解決できます。 。
たとえば、ChatGPT に「この画像について説明してください」リクエストを作成し、ビーバーの写真を渡すことができます。 ChatGPT を使用すると、画像インタプリタを呼び出して「ビーバーが泳いでいる」と出力できます。

次に、ChatGPT がテキスト読み上げを呼び出し、次の文を読むことができます:
A beaver is swim in thewater Audio: 00:0000:01
これは、ChatGPT などの OpenAI の大規模モデルをサポートするだけでなく、 OpenAssistant などの他の無料の大規模モデルをサポートします。
Transformer Agent は、Hugging Face 上の任意の AI モデルを直接呼び出し、処理された結果を出力するように、これらの大規模モデルを「教育」する責任があります。
それでは、この新しく開始された機能の背後にある原理は何でしょうか?
トランスフォーマー エージェントは、簡単に言うと大型モデル専用の「抱き顔AIツール統合パッケージ」です。
このパッケージには、HuggingFace 上の大小さまざまな AI モデルが含まれており、「画像ジェネレーター」、「画像インタープリター」、「テキスト読み上げツール」に分類されています...
At同時に、各ツールには対応するテキストの説明があり、大規模なモデルがどのモデルを呼び出す必要があるかを理解しやすくなります。
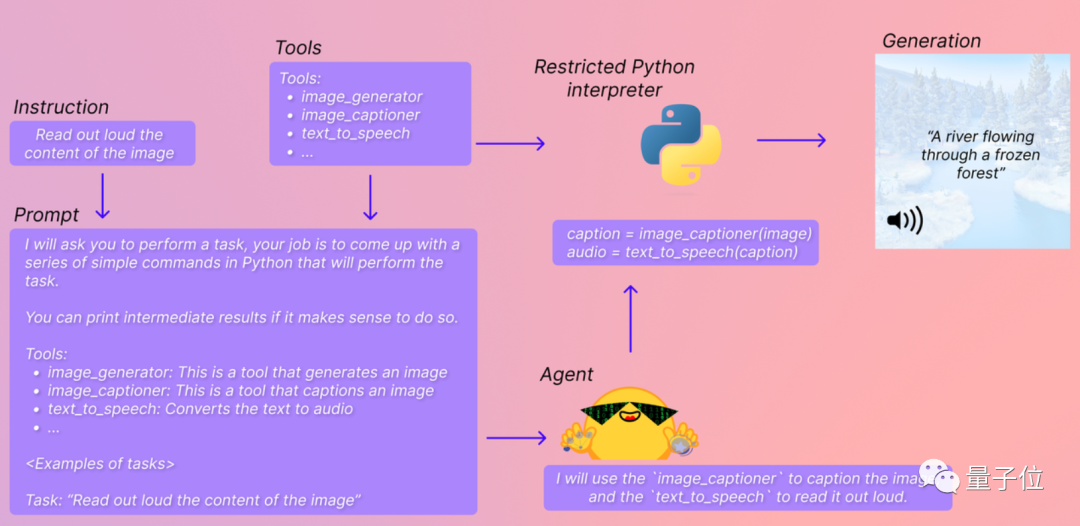
この方法では、簡単なコード プロンプトを作成するだけで、大きなモデルを利用して AI モデルを直接実行して結果を出力できるようになります。リアルタイムで返されます. プロセスは 3 つのステップに分かれています:
まず、使用したい大規模モデルを設定します. ここでは OpenAI の大規模モデルが使用できます (もちろん API は有料):
from transformers import OpenAiAgentagent = OpenAiAgent(model="text-davinci-003", api_key="") BigCode や OpenAssistant などの無料の大規模モデルも使用できます:
from huggingface_hub import loginlogin("") 次に、Hugging Transformers Agent をセットアップします。ここでは、デフォルトのエージェントを例として取り上げます。
from transformers import HfAgent# Starcoderagent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")# StarcoderBase# agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")# OpenAssistant# agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")次に、コマンド run() または chat() を使用して、Transformers エージェントを実行できます。
run() は、複数の AI モデルを同時に呼び出して、より複雑で専門的なタスクを実行するのに適しています。
単一の AI ツールを呼び出すことができます。
たとえば、agent.run("Draw me a picture of Rivers and lakes.") を実行すると、画像の生成を支援する AI グラフィック ツールが呼び出されます。

複数の AI ツールを同時に呼び出すこともできます。
たとえば、agent.run("海の絵を描いて、その絵を変換して島を追加します") を実行すると、「文勝図」と「土勝図」が呼び出されます。対応する画像の生成に役立つツール:

chat() は、チャットを通じて「タスクを継続的に完了する」のに適しています。
たとえば、最初に Wenshengtu AI ツールを呼び出して、川と湖の写真を生成します。agent.chat("Generate a picture of Rivers and lakes")

次に、この写真に基づいて「写真から写真」の変更を行います。agent.chat("そこに岩があるように写真を変換します")

呼び出される AI モデルは自分で設定することも、Huohuan Face に付属する一連のデフォルト設定を使用することもできます。
現在、Transformers Agent はデフォルトの AI モデルのセットを統合しています。これは、Transformer ライブラリで次の AI モデルを呼び出すことで完了します。
1. ビジョンドキュメント理解モデルドーナツ。画像形式のファイル (PDF から変換された画像を含む) を提供する限り、そのファイルを使用してファイルに関する質問に答えることができます。
たとえば、「TRRF 科学諮問委員会の会議はどこで開催されますか?」と尋ねると、Donut は次のように答えます:

2.テキスト質疑応答モデルFlan-T5。長い記事と質問があれば、さまざまな文章の質問に答え、読解に役立ちます。
3. ゼロサンプルの視覚言語モデル BLIP。画像の内容を直接理解し、画像のテキスト説明を提供します。
4. マルチモーダル モデル ViLT。与えられた画像の質問を理解して答えることができます (
5. マルチモーダル画像セグメンテーション モデル CLIPseg)。モデルとプロンプト単語を提供するだけで、システムはプロンプト単語に基づいて画像内の指定されたコンテンツ (マスク) をセグメント化できます。
6. 自動音声認識モデル Whisper。録音内のテキストを自動的に認識し、文字起こしを完了します。
7. 音声合成モデル SpeechT5。テキスト読み上げ用。
8. 自己エンコーディング言語モデル BART。テキスト コンテンツを自動的に分類するだけでなく、テキストの要約を作成することもできます。
9. 200 言語の翻訳モデル NLLB。一般的な言語に加えて、ラオス語やカンバ語などのあまり一般的ではない言語も翻訳できます。
上記の AI モデルを呼び出すことで、画像の質問と回答、文書の理解、画像のセグメンテーション、テキストへの録音、翻訳、キャプション、テキスト読み上げ、テキスト分類などのタスクをすべて完了できます。
さらに、Huohuan Lian には、Web ページからのテキスト、ヴィンセントの写真、写真、ヴィンセントのビデオのダウンロードなど、Transformer ライブラリ外の一部のモデルを含む「プライベート グッズ」も含まれています。

これらのモデルは個別に呼び出すだけでなく、組み合わせて呼び出すこともできます。たとえば、大きなモデルに「見栄えの良い写真を生成して説明する」ように依頼すると、 beaver」では、それぞれ「Venture Picture」AI モデルと「Picture Understanding」AI モデルを呼び出します。
もちろん、これらのデフォルトの AI モデルを使用せず、より便利な「ツール統合パッケージ」をセットアップしたい場合は、手順に従って自分でセットアップすることもできます。
Transformers Agent に関して、一部のネチズンは、LangChain エージェントの「置き換え」に少し似ていると指摘しました。
これら 2 つのツールを試してみましたか?どちらがより便利だと思いますか?
参考リンク: [1]https://twitter.com/huggingface/status/1656334778407297027[2]https://huggingface.co/docs/transformers/transformers_agents
以上がChatGPT で 100,000 以上のオープンソース AI モデルを呼び出しましょう! HuggingFace の新機能が人気沸騰中: 大型モデルをマルチモーダル AI ツールとして使用可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



