



ChatGPT を使用してコードを記述することは、多くのプログラマーにとって日常的な作業になっています。
しかし、ChatGPT によって生成されたコードが、それは単に「正確に見える」だけではありませんか?
イリノイ大学アーバナシャンペーン校と南京大学による新しい研究によると、
ChatGPT と GPT-4 は、少なくとも 精度の高いコードを生成します。以前に評価された 13% 値下げされました !

一部のネチズンは、あまりにも多くの ML 論文がモデルの評価に問題のあるベンチマークや限定的なベンチマークを使用していると嘆いており、完全に「SOTA」に到達しており、評価方法を変えると本来の形状が明らかになりました。

# 一部のネチズンは、これは大規模なモデルによって生成されたコードには依然として手動による監視が必要であることを示していると述べました。まだ到着していません。」

では、この論文はどのような新しい評価手法を提案しているのでしょうか?
この新しいメソッドは EvalPlus と呼ばれ、自動化されたコード評価フレームワークです。
具体的には、既存の評価データセットの入力多様性と問題記述の精度を向上させることで、これらの評価ベンチマークをより厳密なものにします。
一方で、それは入力の多様性です。 EvalPlus は、最初に ChatGPT を使用して、標準の回答に基づいていくつかのシード入力サンプルを生成します (ChatGPT のプログラミング能力をテストする必要がありますが、それを使用してシード入力を生成することは矛盾していないようです)
次に、次を使用します。 EvalPlus は、これらのシード入力を改善し、より難しく、より複雑で、よりトリッキーなものにします。
もう 1 つの側面は、問題の説明の正確さです。 EvalPlus は、コード要件の記述をより正確に変更し、入力条件を制限しながら、自然言語の問題の記述を補足して、モデル出力の精度要件を向上します。
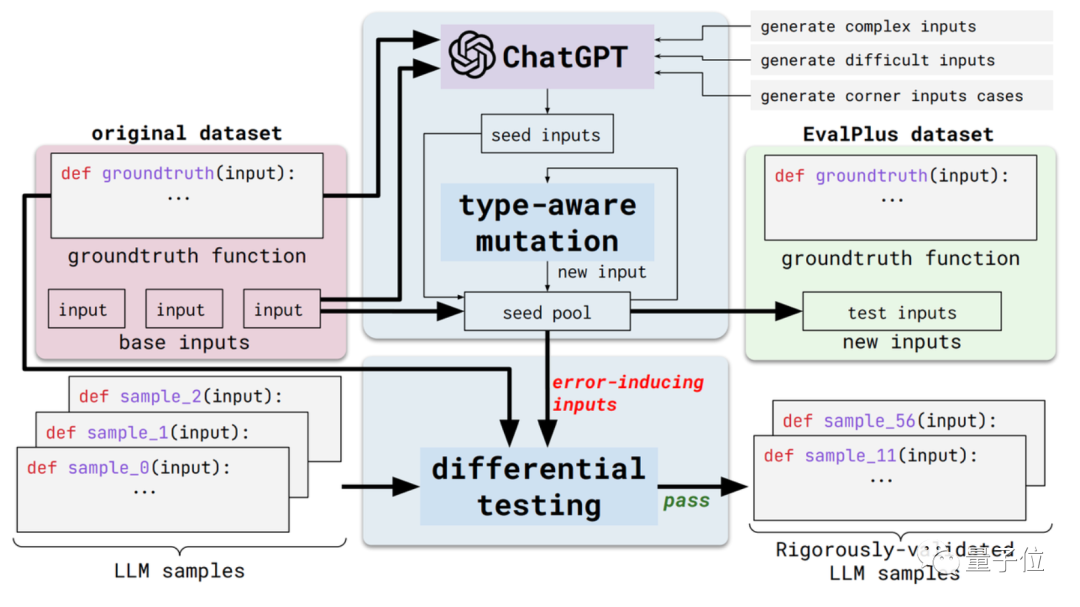
ここでは、この論文ではデモンストレーションとして HUMANEVAL データ セットを選択します。
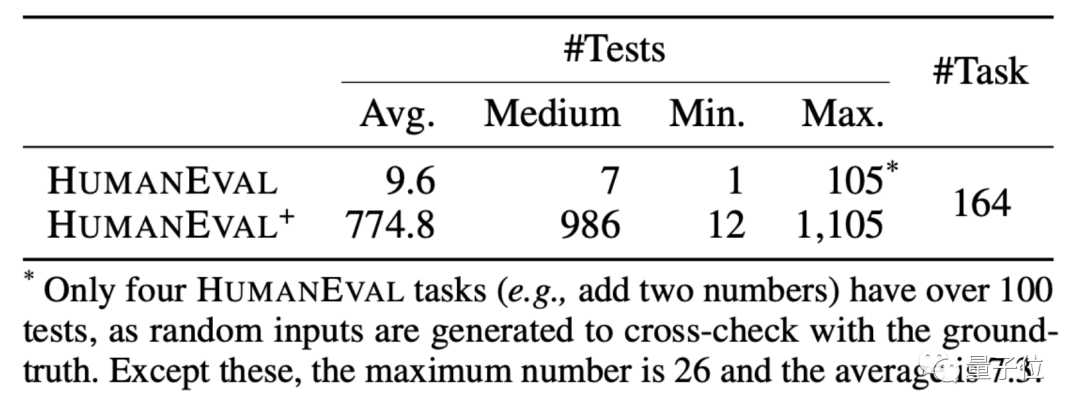
HUMANEVAL は、OpenAI と Anthropic AI によって作成されたコード データ セットで、言語理解、アルゴリズム、数学、ソフトウェア面接に関する数種類の質問を含む 164 のオリジナルのプログラミング質問が含まれています。
EvalPlus は、そのようなデータセットの入力タイプと関数の説明を改善することで、プログラミングの問題をより明確に見せると同時に、テストに使用される入力をより「トリッキー」または困難なものにします。
和集合プログラミングの質問の 1 つを例として挙げると、AI は 2 つのデータ リスト内の共通要素を見つけてこれらの要素を並べ替えるコードを記述する必要があります。
EvalPlus は、ChatGPT によって記述されたコードの精度をテストするためにこれを使用します。
簡単な入力テストを行った結果、ChatGPT は正確な回答を出力できることがわかりました。しかし、入力を変更すると、ChatGPT バージョンのコードにバグが見つかります。

テストの問題がさらに多いのは事実です。 AIにとっては難しい。

この方法に基づいて、EvalPlus は HUMANEVAL データ セットの改良版も作成しました。入力を追加しながら、HUMANEVAL の回答の一部を修正しました。 . プログラミングに関する問題。
それでは、この「新しいテスト質問セット」では、大規模な言語モデルの精度は実際にどのくらい割り引かれるのでしょうか?
著者は、現在人気のある 10 個のコード生成 AI をテストしました。
GPT-4、ChatGPT、CODEGEN、VICUNA、SANTACODER、INCODER、GPT-J、GPT-NEO、PolyCoder、StableLM-α。
表から判断すると、厳密なテストの後、このグループの AI の生成精度は低下しています:
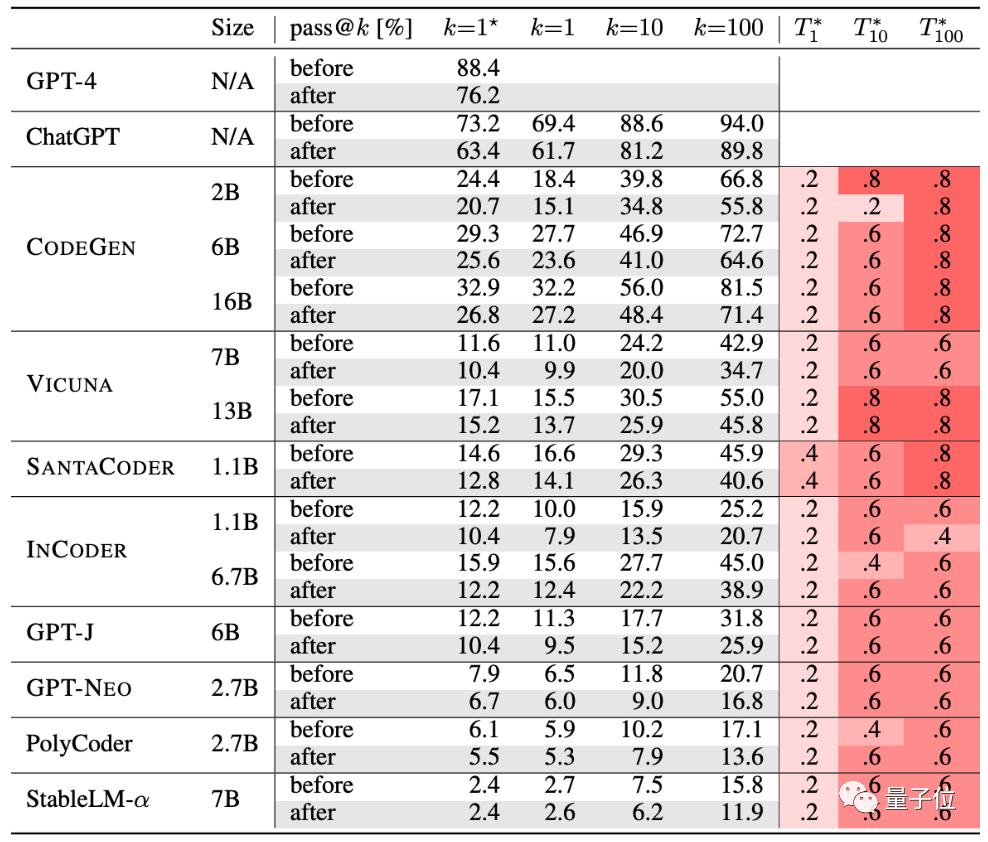
ここでは、精度は pass@k と呼ばれるメソッドを通じて評価されます。ここで、k は問題に対して大規模なモデルを生成できるプログラムの数、n はテストに使用される入力の数、c は正しい入力の数です。入力:
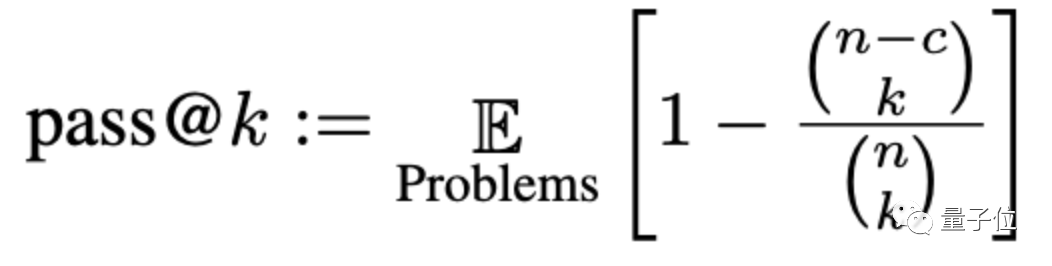
#新しい評価基準セットによると、大規模なモデルの精度は平均で 15% 低下し、より広く研究されているモデルの精度は、 CODEGEN-16B はさらに 18% 以上減少しました。
ChatGPT および GPT-4 で生成されたコードのパフォーマンスに関しても、少なくとも 13% 低下しました。
しかし、一部のネチズンは、大規模なモデルによって生成されたコードがそれほど優れていないのは「周知の事実」であり、研究する必要があるのは「なぜ大規模なモデルによって作成されたコードが優れたものではないのか」であると述べています。使用済み。"
#
以上がChatGPT プログラミングの精度が 13% 低下しました。 UIUC と NTU の新しいベンチマークにより、AI コードが本来の形式で表示されるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



