


辞書ツリー (トライ ツリー) は、文字列の保存と検索によく使用されるツリー データ構造です。ディクショナリ ツリーの中心的な考え方は、文字列間に共通のプレフィックスを使用してストレージ スペースを節約し、クエリの効率を向上させることです。これはマルチツリーであり、各ノードは文字列の接頭辞を表し、ルート ノードから葉ノードまでのパスが文字列を構成します。
辞書ツリーのルート ノードには文字が含まれません。各子ノードは文字を表します。ルート ノードから任意のノードへのパス上の文字は、ノードが表す文字列に接続されます。各ノードは 1 つ以上の文字列を格納でき、通常はフラグを使用して、ノードによって表される文字列が存在するかどうかをマークします。一連の文字列の中から文字列を検索する必要がある場合、辞書ツリーを使用して効率的な検索操作を実現できます。
たとえば、文字列配列 {"goog", "google", "bai", "baidu", "a"} のプレフィックス ツリーを作成します。現時点では、プレフィックス ツリーのいくつかの特徴がはっきりとわかります:
ルート ノードは文字を格納しません
プレフィックス ツリーはマルチフォーク ツリー
プレフィックス ツリーの各ノードは 1 文字を保存します
同じプレフィックスを持つ文字列は同じパスに保存されます
プレフィックス ツリーでは、文字列の末尾にも終了マークが付きます。プレフィックス ツリーの
1. プレフィックス ツリーのデータ構造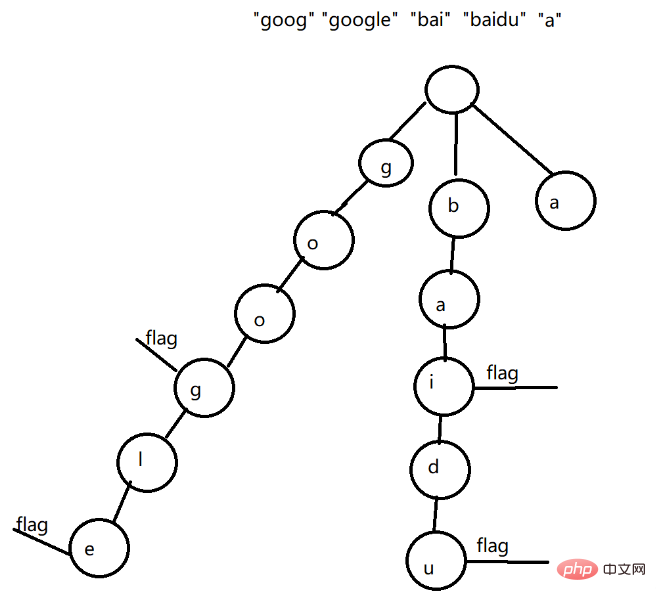
public class Trie { Map next; boolean isEnd; public Trie() { this.next = new HashMap<>(); this.isEnd = false; } public void insert(String word) { } public boolean search(String word) { return false; } public boolean startsWith(String prefix) { return false; } }
public void insert(String word) { Trie trie = this;//获得根结点 for (char c : word.toCharArray()) { if (trie.next.get(c) == null) {//当前结点不存在 trie.next.put(c, new Trie());//创建当前结点 } trie = trie.next.get(c);//得到字符c的结点,继续向下遍历 } trie.isEnd = true; }
public boolean search(String word) { Trie trie = this;//获得根结点 for (char c : word.toCharArray()) { if (trie.next.get(c) == null) {//当前结点不存在 return false; } trie = trie.next.get(c);//得到字符c的结点,继续向下遍历 } return trie.isEnd; }
public boolean startsWith(String prefix) { Trie trie = this;//获得根结点 for (char c : prefix.toCharArray()) { if (trie.next.get(c) == null) {//当前结点不存在 return false; } trie = trie.next.get(c);//得到字符c的结点,继续向下遍历 } return true; }
words
内の最長の単語を返します。この単語は、リコウ: リコウ2. 問題分析これは典型的なプレフィックス ツリーの質問ですが、この質問にはいくつかの特別な要件があり、返される答えは次のとおりです:
rree
以上がJavaでプレフィックスツリーを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



