


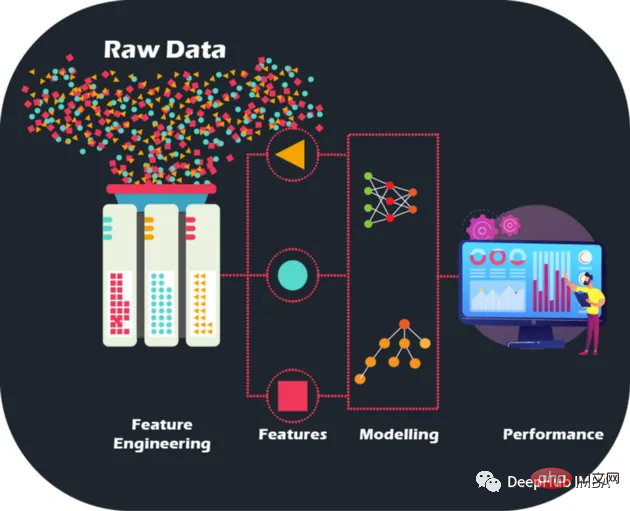
生データに対して手作業で特徴量エンジニアリングを実行することで、モデルの精度とパフォーマンスを新たなレベルに引き上げ、より正確な予測とより賢明なビジネス上の意思決定への道を開くことができます。これまでにない方法でモデルを最適化し、ビジネス能力を向上させることができます。

生データは、画像のないジグソーパズルのようなものです。しかし、特徴量エンジニアリングを使用すると、ピースを組み合わせることができます。ただし、大量のデータを取得するのは確かに困難です。金融機関にとっては学習モデルの宝庫ですが、すべてのデータが有益であるわけではないことを認識することも重要です。また、マニュアル機能は手動で設計されており、それぞれの操作の理由を説明できるため、解釈可能性ももたらします。
特徴エンジニアリングは、単に最適な特徴を選択するだけではありません。また、モデルの一般化能力を向上させるために、データ内のノイズと冗長性を削減することも含まれます。モデルが本当に役立つためには、目に見えないデータに対して適切なパフォーマンスを発揮する必要があるため、これは非常に重要です。
この記事で説明されているデータセットは、顧客データの機密性を維持するために匿名化およびマスクされています。特徴は次のように分類できます。
D_* = 拖欠变量 S_* = 支出变量 P_* = 支付变量 B_* = 平衡变量 R_* = 风险变量
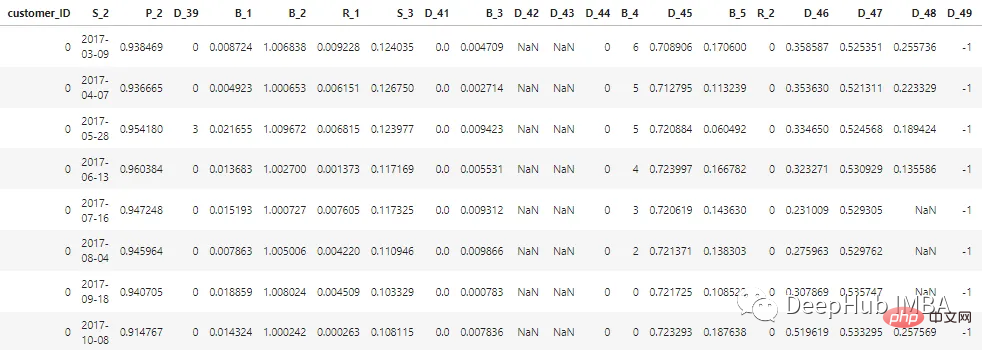
過去 12 か月間の顧客のステータスを表す、合計 100 個の整数特徴と 100 個の浮動小数点特徴があります。このデータセットには、1 から 13 までの顧客レポートに関する情報が含まれています。顧客のクレジット カードの明細ごとに 30 ~ 180 日のギャップが生じる場合があります (つまり、顧客のクレジット カードの明細が欠落している可能性があります)。各顧客は顧客 ID によって表されます。 customer_ID=0 の最初の 5 人の顧客のサンプル データは次のとおりです。
700 万件の customer_ID のうち、98% のラベルは「0」です (優良顧客、なしデフォルト)、2% には「1」(悪い顧客、デフォルト)というラベルが付けられます。
データセットが大きいため、処理を高速化するために cudf を使用します。cudf がインストールされていない場合は、pandas と同様です。
# LOAD LIBRARIES
import pandas as pd, numpy as np # CPU libraries
import cudf # GPU libraries
import matplotlib.pyplot as plt, gc, os
df = cudf.read_parquet('./data.parquet')数百ものアイデアがあり、特徴を生成するためにいくつかのアイデアを使用できますが、これらの特徴がモデルのパフォーマンス向上に役立つことも確認しています。次の図は、特徴エンジニアリングで使用されるいくつかの基本的な方法を示しています:
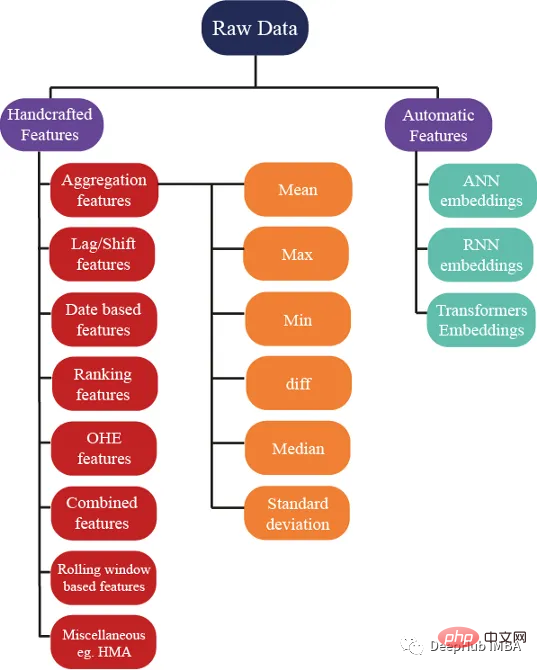
集計は、複雑なデータを理解するための秘訣です。 customer_ID (C_ID) や製品カテゴリなどのカテゴリ別グループ化変数、または数値変数の集計の概要統計を計算することで、目に見えないパターンや傾向を発見できます。平均、最大、最小、標準偏差、中央値などの概要統計を使用すると、より正確な予測モデルを構築し、顧客データ、トランザクション データ、またはその他の数値データから有意義な洞察を抽出できます。
これらの統計属性は顧客ごとに計算できます
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
num_features = [col for col in all_cols if col not in cat_features] #all features accept cateforical features.
test_num_agg = df.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
test_num_agg.columns = ['_'.join(x) for x in test_num_agg.columns]平均: 数値変数の平均値から、データの中心的な傾向を大まかに把握できます。平均キャプチャ:
顧客の平均銀行残高。
標準偏差 (Std): 平均値付近のデータの分布の尺度。データの変動の程度についての洞察が得られます。残高の変動が大きい場合は、顧客が支出していることを示しています。
最小値と最大値はクライアントの富を捉え、またクライアントの支出とリスクに関する情報も捉えます。
中央値: データの偏りが大きい場合、平均値を使用するのは良い考えではないため、中央値を使用できます (値の中央を使用できます。
最新値は、顧客に発行された最新の既知の信用明細書に関する情報が含まれており、顧客のアカウントの現在のステータスを示すため、最も重要な機能である可能性があります。
カテゴリカルな目的で使用します。変数 上記の統計的特性は、最小値、最大値、または標準偏差を計算しても有用な情報が得られないため、賢明ではありません。それでは、どうすればよいでしょうか? 特徴は、カウントや固有の数量などの特徴を使用して計算できます。最新の値は、次の方法で取得することもできます。
cat_features = ["B_1","B_2","D_1","D_2","D_10","P_21","D_126","D_3","D_42","R_66","R_68"]
test_cat_agg = df.groupby("customer_ID")[cat_features].agg(['count', 'last', 'nunique'])
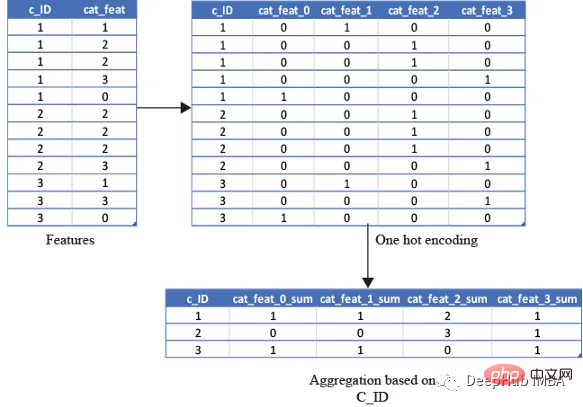
test_cat_agg.columns = ['_'.join(x) for x in test_cat_agg.columns]しかし、この情報は、顧客が特定のカテゴリに分類されているかどうかを捕捉するものではありません。そのため、変数を 1 回ホット エンコードし、次に平均、合計、最後に変数などをエンコードすることでこれを実行します)。
平均は、顧客がそのカテゴリに該当する合計回数/銀行取引明細書の合計数の比率を取得します。合計は、単に顧客がそのカテゴリに該当する合計回数になります。 category.
from cuml.preprocessing import OneHotEncoder
df_categorical = df_last[cat_features].astype(object)
ohe = OneHotEncoder(drop='first', sparse=False, dtype=np.float32, handle_unknown='ignore')
ohe.fit(df_categorical)with open("ohe.pickle", 'wb') as f:
pickle.dump(ohe, f) #save the encoder so that it can be used for test data as well df_categorical = pd.DataFrame(ohe.transform(df_categorical).astype(np.float16),index=df_categorical.index).rename(columns=str)
df_categorical['customer_ID']=df['customer_ID']
df_categorical.groupby('customer_ID').agg(['mean', 'sum', 'last'])
在预测客户行为方面,基于排名的特征是非常重要的。通过根据收入或支出等特定属性对客户进行排名,我们可以深入了解他们的财务习惯并更好地管理风险。
使用 cudf 的 rank 函数,我们可以轻松计算这些特征并使用它们来为预测提供信息。例如,可以根据客户的消费模式、债务收入比或信用评分对客户进行排名。然后这些特征可用于预测违约或识别有可能拖欠付款的客户。
基于排名的特征还可用于识别高价值客户、目标营销工作和优化贷款优惠。例如,可以根据客户接受贷款提议的可能性对客户进行排名,然后将排名最高的客户作为目标。
df[feat+'_rank']=df[feat].rank(pct=True, method='min')
PCT用于是否做百分位排名。客户的排名也可以基于分类特征来计算。
df[feat+'_rank']=df.groupby([cat_feat]).rank(pct=True, method='min')
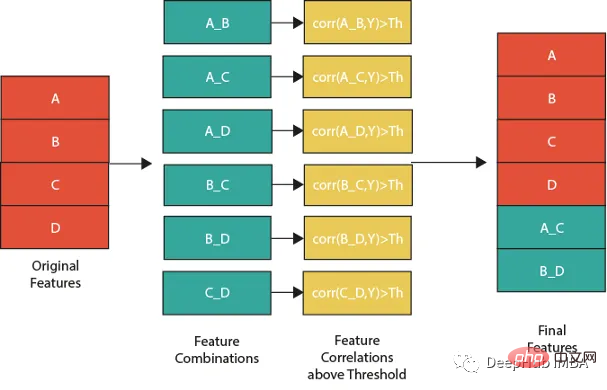
特征组合的一种流行方法是线性或非线性组合。这包括采用两个或多个现有特征,将它们组合在一起创建一个新的复合特征。然后使用这个复合特征来识别单独查看单个特征时可能不可见的模式、趋势和相关性。
例如,假设我们正在分析客户消费习惯的数据集。可以从个人特征开始,比如年龄、收入和地点。但是通过以线性或非线性的方式组合这些特性,可以创建新的复合特性,使我们能够更多地了解客户。可以结合收入和位置来创建一个复合特征,该特征告诉我们某一地区客户的平均支出。
但是并不是所有的特征组合都有用。关键是要确定哪些组合与试图解决的问题最相关,这需要对数据和问题领域有深刻的理解,并仔细分析创建的复合特征和试图预测的目标变量之间的相关性。
下图展示了一个组合特征并将信息用于模型的过程。作为筛选条件,这里只选择那些与目标相关性大于最大值 0.9 的特征。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features] for feat1 in features: for feat2 in features: th=max(np.corr(feat1,Y)[0],np.corr(feat1,Y)[0]) #calculate threshold feat3=df[feat1]-df[feat2] #difference feature corr3=np.corr(feat3,Y)[0] if(corr3>max(th,0.9)): #if correlation greater than max(th,0.9) we add it as feature df[feat1+'_'+feat2]=feat3
在数据分析方面,基于时间的特征非常重要。通过根据时间属性(例如月份或星期几)对数据进行分组,可以创建强大的特征。这些特征的范围可以从简单的平均值(如收入和支出)到更复杂的属性(如信用评分随时间的变化)。
借助基于时间的特征,还可以识别在孤立地查看数据时可能看不到的模式和趋势。下图演示了如何使用基于时间的特征来创建有用的复合属性。
首先,计算一个月内的值的平均值(可以使用该月的某天或该月的某周等),将获得的DF与原始数据合并,并取各个特征之间的差。
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features]
month_Agg=df.groupby([month])[features].agg('mean')#grouping based on month feature
month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns]
month_Agg.reset_index(inplace=True)
df=df.groupby(month_Agg,notallow='month')
for feat in features: #create composite features b taking difference
df[feat+'_'+feat+'_month_mean']=df[feat]-df[feat+'_month_mean']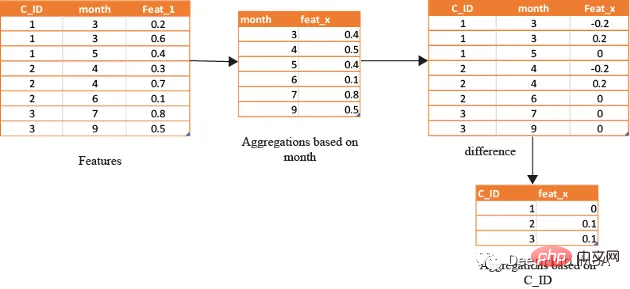
还可以通过使用时间作为分组变量来创建基于排名的特征,如下所示
features=[col for col in train.columns if col not in ['customer_ID',target]+cat_features] month_Agg=df.groupby([month])[features].rank(pct=True) #grouping based on month feature month_Agg.columns = ['_month_'.join(x) for x in month_Agg.columns] month_Agg.reset_index(inplace=True) df=pd.concat([df,month_Agg],axis=1) #concat to original dataframe
滞后特征是有效预测金融数据的重要工具。这些特征包括计算时间序列中当前值与之前值之间的差值。通过将滞后特征纳入分析,可以更好地理解数据中的模式和趋势,并做出更准确的预测。
如果滞后特征显示客户连续几个月按时支付信用卡账单,可能会预测他们将来不太可能违约。相反,如果延迟特征显示客户一直延迟或错过付款,可能会预测他们更有可能违约。
# difference function calculate the lag difference for numerical features
#between last value and shift last value.
def difference(groups,num_features,shift):
data=(groups[num_features].nth(-1)-groups[num_features].nth(-1*shift)).rename(columns={f: f"{f}_diff{shift}" for f in num_features})
return data
#calculate diff features for last -2nd last, last -3rd last, last- 4th last
def get_difference(data,num_features):
print("diff features...")
groups=data.groupby('customer_ID')
df1=difference(groups,num_features,2).fillna(0)
df2=difference(groups,num_features,3).fillna(0)
df3=difference(groups,num_features,4).fillna(0)
df1=pd.concat([df1,df2,df3],axis=1)
df1.reset_index(inplace=True)
df1.sort_values(by='customer_ID')
del df2,df3
gc.collect()
return df1train_diff = get_difference(df, num_features)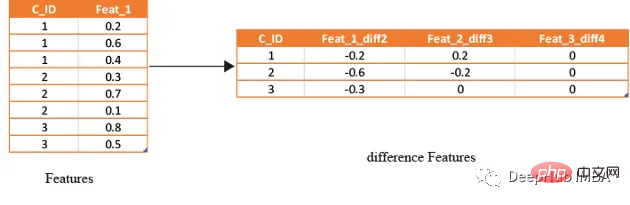
这些特征只是取最后3(4,5,…x)值的平均值,这取决于数据,因为基于时间的最新值携带了关于客户最新状态的信息。
xth=3 #define the window size
df["cumulative"]=df.groupby('customer_ID').sort_values(by=['time'],ascending=False).cumcount()
last_info=df[df["cumulative"]<=xth]
last_info = last_info.groupby("customer_ID")[num_features].agg(['mean', 'std', 'min', 'max', 'last','median']) #grouping by customerID
last_info.columns = ['_'.join(x) for x in last_info.columns]上面的方法已经创建了足够多的特征来构建一个很棒的模型。但是根据数据的性质,还可以创建更多的特征。例如:可以创建像null计数这样的特征,它可以计算客户当前的总null值,从而帮助捕获基于树的算法无法理解的特征分布。
def calc_nan(df,features):
print("calculating nan_info...")
df_nan = (df[features].mul(0) + 1).fillna(0) #marke non_null values as 1 and null as zero
df_nan['customer_ID'] = df['customer_ID']
nan_sum = df_nan.groupby("customer_ID").sum().sum(axis=1) #total unknown values for a customer
nan_last = df_nan.groupby("customer_ID").last().sum(axis=1)#how many last values that are not known
del df_nan
gc.collect()
return nan_sum,nan_last这里可以不使用平均值,而是使用修正的平均值,如基于时间的加权平均值或 HMA(hull moving average)。
この記事では、現実世界でのデフォルト リスクを予測するために使用される、最も一般的な手作りの機能戦略をいくつか紹介しました。ただし、フィーチャーを設計するには常に新しく革新的な方法があり、フィーチャーを手動で設定する方法は時間と労力がかかるため、フィーチャーを自動生成するツールの使用方法については、後の記事で紹介します。
以上が手作りの機能を使用してモデルのパフォーマンスを向上させるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



