



#GPT-4 の画像認識機能はいつオンラインになりますか?この質問に対する答えはまだありません。
しかし、研究コミュニティはもう待ちきれずに DIY を開始しており、最も人気のあるプロジェクトは MiniGPT-4 と呼ばれるプロジェクトです。 MiniGPT-4 は、詳細な画像説明の生成や手書きの下書きから Web サイトを作成するなど、GPT-4 と同様の多くの機能を示します。さらに、著者らは、与えられた画像に基づいて物語や詩を作成すること、画像に示されている問題に対する解決策を提供すること、食べ物の写真に基づいて料理方法をユーザーに教えることなど、MiniGPT-4 の他の新しい機能を観察しました。このプロジェクトは、開始から 3 日以内に約 10,000 個のスターを獲得しました。

今日紹介するプロジェクト - LLaVA (Large Language and Vision Assistant) も同様で、ウィスコンシン大学によって開発されたプロジェクトです。 -Madison と Microsoft 研究所とコロンビア大学の研究者が共同でリリースした大規模なマルチモーダル モデル。

 #Heart of the Machine の試験結果は次のとおりです (詳細な結果については記事の最後を参照してください):
#Heart of the Machine の試験結果は次のとおりです (詳細な結果については記事の最後を参照してください):
論文概要
この目的を達成するために、コミュニティでは言語拡張に基づいてビジュアル モデルを開発する傾向があります。このタイプのモデルは、分類、検出、セグメンテーション、グラフィックスなどのオープンワールドの視覚的理解における強力な機能に加え、ビジュアル生成およびビジュアル編集機能を備えています。各タスクは大規模なビジュアル モデルによって独立して解決され、タスクのニーズはモデル設計で暗黙的に考慮されます。さらに、言語は画像の内容を説明するためにのみ使用されます。このため、言語は視覚信号を言語セマンティクス (人間のコミュニケーションの共通チャネル) にマッピングする上で重要な役割を果たしますが、多くの場合、対話性やユーザー指示への適応性に制限のある固定インターフェイスを持つモデルが生成されます。
一方、大規模言語モデル (LLM) は、言語が汎用インテリジェント アシスタントのためのユニバーサル インタラクティブ インターフェイスとして、より幅広い役割を果たすことができることを示しました。共通のインターフェイスでは、さまざまなタスクの指示を言語で明示的に表現し、エンドツーエンドで訓練されたニューラル ネットワーク アシスタントをガイドしてモードを切り替えてタスクを完了することができます。たとえば、ChatGPT と GPT-4 の最近の成功は、人間の指示に従ってタスクを完了する LLM の力を実証し、オープンソース LLM 開発の波を引き起こしました。その中でもLLaMAはGPT-3と同等の性能を持つオープンソースLLMです。 Alpaca、Vicuna、GPT-4-LLM は、さまざまな機械生成された高品質命令トレース サンプルを利用して LLM のアライメント機能を向上させ、独自の LLM と比較して優れたパフォーマンスを示します。残念ながら、これらのモデルへの入力はテキストのみです。
この記事では、研究者らは視覚的な命令チューニング方法を提案しています。これは、命令チューニングをマルチモーダル空間に拡張する最初の試みであり、一般的な視覚アシスタントの構築への道を開きます。
具体的には、この論文は次のことに貢献します:
入力画像 X_v について、この記事では、事前学習済みの CLIP ビジュアル エンコーダ ViT-L/14 を処理に使用し、視覚特徴を取得します。 Z_v=g (X_v)。最後の Transformer レイヤーの前後のメッシュ フィーチャが実験で使用されました。この記事では、単純な線形レイヤーを使用して、画像特徴を単語埋め込み空間に接続します。具体的には、トレーニング可能な射影行列 W を適用して、Z_v を言語埋め込みトークン H_q に変換します。これは、言語モデルの単語埋め込み空間と同じ次元を持ちます。
#その後、一連の視覚マーカー H_v が取得されます。このシンプルな投影スキームは軽量かつ低コストで、データ中心の実験を迅速に繰り返すことができます。また、Flamingo のゲート クロスアテンション メカニズムや BLIP-2 の Q-former など、画像と言語の機能を連結するためのより複雑な (しかし高価な) スキームや、オブジェクト レベルの機能を提供する他のビジュアル エンコーダを検討することもできます。サム。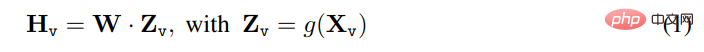
実験結果
研究者は、チャット ロボットのサンプル製品を開発しました。 LLaVA の画像理解と対話機能を実証します。 LLaVA がどのように視覚入力を処理し、命令を処理する能力を実証するかをさらに研究するために、研究者らはまず、表 4 および 5 に示すように、元の GPT-4 論文の例を使用しました。使用されるプロンプトは画像の内容に適合する必要があります。比較のために、この記事ではマルチモーダル モデル GPT-4 のプロンプトと結果を論文から引用しています。

驚くべきことに、LLaVA は小規模なマルチモーダル命令データセット ((約 80K の固有の画像) を使用して実行されましたが、 ) ですが、上記の 2 つの例では、マルチモーダル モデル GPT-4 と非常によく似た推論結果が示されています。どちらの画像も LLaVA のデータセットの範囲外であることに注意してください。LLaVA はシーンを理解し、質問の指示に答えることができます。対照的に、BLIP-2 と OpenFlamingo は、ユーザーの指示に適切な方法で応答するのではなく、画像を記述することに重点を置いています。他の例を図 3、図 4、および図 5 に示します。



#定量的な評価結果を表 3 に示します。

ScienceQA
ScienceQA には、21,000 個のマルチモーダルな複数選択の質問が含まれています、3 つのテーマ、26 のトピック、127 のカテゴリ、および 379 のスキルが含まれており、ドメインの多様性が豊かです。ベンチマーク データセットは、トレーニング、検証、テストの各部分に分割されており、それぞれ 12726、4241、4241 個のサンプルがあります。この記事では、GPT-3.5 モデル (text-davinci-002) と、思考連鎖 (CoT) バージョン、LLaMA アダプター、およびマルチモーダル思考連鎖 (MM-CoT) を含まない GPT-3.5 モデルを含む 2 つの代表的な方法を比較します [57] ]、これはこのデータセットに対する現在の SoTA メソッドであり、その結果を表 6 に示します。

論文に記載されているビジュアライゼーションの使用方法のページで、マシンハートはいくつかの画像と命令を入力しようとしました。 。 1 つ目は、Q&A における複数人で行う一般的なタスクです。テストの結果、人数を数える際に小さなターゲットが無視されること、重なっている人に対して認識エラーが発生すること、性別についても認識エラーが発生することが判明しました。


#次に、写真に名前を付ける、または絵に基づいてストーリーを語るなど、いくつかの生成タスクを試しました。絵物語。モデルによって出力される結果は依然として画像コンテンツの理解に偏っており、生成機能を強化する必要があります。


以上がLava Alpaca LLaVA が登場: GPT-4 と同様に、写真の表示とチャットが可能で、招待コードは不要で、オンラインでプレイできますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。





























![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



